
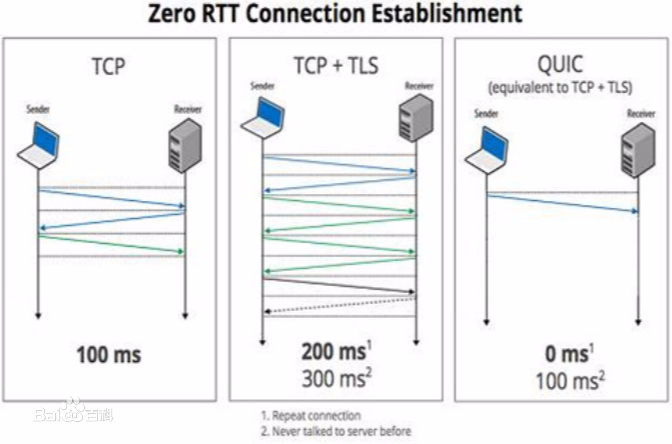

The Tactile Internet paradigm is set to revolutionize human society by enabling skill-set delivery and haptic communication over ultra-reliable, low-latency networks. The emerging sixth-generation (6G) mobile communication systems are envisioned to underpin this Tactile Internet ecosystem at the network edge by providing ubiquitous global connectivity. However, apart from a multitude of opportunities of the Tactile Internet, security and privacy challenges emerge at the forefront. We believe that the recently standardized QUIC protocol, characterized by end-to-end encryption and reduced round-trip delay would serve as the backbone of Tactile Internet. In this article, we envision a futuristic scenario where a QUIC-enabled network uses the underlying 6G communication infrastructure to achieve the requirements for Tactile Internet. Interestingly this requires a deeper investigation of a wide range of security and privacy challenges in QUIC, that need to be mitigated for its adoption in Tactile Internet. Henceforth, this article reviews the existing security and privacy attacks in QUIC and their implication on users. Followed by that, we discuss state-of-the-art attack mitigation strategies and investigate some of their drawbacks with possible directions for future work
相關內容
GEneral Matrix Multiply (GEMM) is a central operation in deep learning and corresponds to the largest chunk of the compute footprint. Therefore, improving its efficiency is an active topic of ongoing research. A popular strategy is the use of low bit-width integers to approximate the original entries in a matrix. This allows efficiency gains, but often requires sophisticated techniques to control the rounding error incurred. In this work, we first verify/check that when the low bit-width restriction is removed, for a variety of Transformer-based models, whether integers are sufficient for all GEMMs need -- for {\em both} training and inference stages, and can achieve parity with floating point counterparts. No sophisticated techniques are needed. We find that while a large majority of entries in matrices (encountered in such models) can be easily represented by {\em low} bit-width integers, the existence of a few heavy hitter entries make it difficult to achieve efficiency gains via the exclusive use of low bit-width GEMMs alone. To address this issue, we develop a simple algorithm, Integer Matrix Unpacking (IM-Unpack), to {\em unpack} a matrix with large integer entries into a larger matrix whose entries all lie within the representable range of arbitrarily low bit-width integers. This allows {\em equivalence} with the original GEMM, i.e., the exact result can be obtained using purely low bit-width integer GEMMs. This comes at the cost of additional operations -- we show that for many popular models, this overhead is quite small.
The anthropocentric cultural idea that humans are active agents exerting control over their environments has been largely normalized and inscribed in practices, policies, and products of contemporary industrialized societies. This view underlies a human-ecology relationship based on resource and knowledge extraction. To create a more sustainable and equitable future, it is essential to consider alternative cultural ideas rooted in ecological thinking. This perspective underscores the interconnectedness between humans and more-than-human worlds. We propose a path to reshape the human-ecology relationship by advocating for alternative human-AI interactions. In this paper, we undertake a critical comparison between anthropocentrism and ecological thinking, using storytelling to illustrate various human-AI interactions that embody ecological thinking. We also delineate a set of design principles aimed at guiding AI developments toward fostering a more caring human-ecology relationship.
With appropriate data selection and training techniques, Large Language Models (LLMs) have demonstrated exceptional success in various medical examinations and multiple-choice questions. However, the application of LLMs in medical dialogue generation-a task more closely aligned with actual medical practice-has been less explored. This gap is attributed to the insufficient medical knowledge of LLMs, which leads to inaccuracies and hallucinated information in the generated medical responses. In this work, we introduce the Medical dialogue with Knowledge enhancement and clinical Pathway encoding (MedKP) framework, which integrates an external knowledge enhancement module through a medical knowledge graph and an internal clinical pathway encoding via medical entities and physician actions. Evaluated with comprehensive metrics, our experiments on two large-scale, real-world online medical consultation datasets (MedDG and KaMed) demonstrate that MedKP surpasses multiple baselines and mitigates the incidence of hallucinations, achieving a new state-of-the-art. Extensive ablation studies further reveal the effectiveness of each component of MedKP. This enhancement advances the development of reliable, automated medical consultation responses using LLMs, thereby broadening the potential accessibility of precise and real-time medical assistance.
Despite the impressive performance across numerous tasks, large language models (LLMs) often fail in solving simple decision-making tasks due to the misalignment of the knowledge in LLMs with environments. On the contrary, reinforcement learning (RL) agents learn policies from scratch, which makes them always align with environments but difficult to incorporate prior knowledge for efficient explorations. To narrow the gap, we propose TWOSOME, a novel general online framework that deploys LLMs as decision-making agents to efficiently interact and align with embodied environments via RL without requiring any prepared datasets or prior knowledge of the environments. Firstly, we query the joint probabilities of each valid action with LLMs to form behavior policies. Then, to enhance the stability and robustness of the policies, we propose two normalization methods and summarize four prompt design principles. Finally, we design a novel parameter-efficient training architecture where the actor and critic share one frozen LLM equipped with low-rank adapters (LoRA) updated by PPO. We conduct extensive experiments to evaluate TWOSOME. i) TWOSOME exhibits significantly better sample efficiency and performance compared to the conventional RL method, PPO, and prompt tuning method, SayCan, in both classical decision-making environment, Overcooked, and simulated household environment, VirtualHome. ii) Benefiting from LLMs' open-vocabulary feature, TWOSOME shows superior generalization ability to unseen tasks. iii) Under our framework, there is no significant loss of the LLMs' original ability during online PPO finetuning.
We study a setting in which a community wishes to identify a strongly supported proposal from a space of alternatives, in order to change the status quo. We describe a deliberation process in which agents dynamically form coalitions around proposals that they prefer over the status quo. We formulate conditions on the space of proposals and on the ways in which coalitions are formed that guarantee deliberation to succeed, that is, to terminate by identifying a proposal with the largest possible support. Our results provide theoretical foundations for the analysis of deliberative processes such as the ones that take place in online systems for democratic deliberation support.
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine's Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture--observation, planning, and reflection--each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
Multimodality Representation Learning, as a technique of learning to embed information from different modalities and their correlations, has achieved remarkable success on a variety of applications, such as Visual Question Answering (VQA), Natural Language for Visual Reasoning (NLVR), and Vision Language Retrieval (VLR). Among these applications, cross-modal interaction and complementary information from different modalities are crucial for advanced models to perform any multimodal task, e.g., understand, recognize, retrieve, or generate optimally. Researchers have proposed diverse methods to address these tasks. The different variants of transformer-based architectures performed extraordinarily on multiple modalities. This survey presents the comprehensive literature on the evolution and enhancement of deep learning multimodal architectures to deal with textual, visual and audio features for diverse cross-modal and modern multimodal tasks. This study summarizes the (i) recent task-specific deep learning methodologies, (ii) the pretraining types and multimodal pretraining objectives, (iii) from state-of-the-art pretrained multimodal approaches to unifying architectures, and (iv) multimodal task categories and possible future improvements that can be devised for better multimodal learning. Moreover, we prepare a dataset section for new researchers that covers most of the benchmarks for pretraining and finetuning. Finally, major challenges, gaps, and potential research topics are explored. A constantly-updated paperlist related to our survey is maintained at //github.com/marslanm/multimodality-representation-learning.
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
Automatic KB completion for commonsense knowledge graphs (e.g., ATOMIC and ConceptNet) poses unique challenges compared to the much studied conventional knowledge bases (e.g., Freebase). Commonsense knowledge graphs use free-form text to represent nodes, resulting in orders of magnitude more nodes compared to conventional KBs (18x more nodes in ATOMIC compared to Freebase (FB15K-237)). Importantly, this implies significantly sparser graph structures - a major challenge for existing KB completion methods that assume densely connected graphs over a relatively smaller set of nodes. In this paper, we present novel KB completion models that can address these challenges by exploiting the structural and semantic context of nodes. Specifically, we investigate two key ideas: (1) learning from local graph structure, using graph convolutional networks and automatic graph densification and (2) transfer learning from pre-trained language models to knowledge graphs for enhanced contextual representation of knowledge. We describe our method to incorporate information from both these sources in a joint model and provide the first empirical results for KB completion on ATOMIC and evaluation with ranking metrics on ConceptNet. Our results demonstrate the effectiveness of language model representations in boosting link prediction performance and the advantages of learning from local graph structure (+1.5 points in MRR for ConceptNet) when training on subgraphs for computational efficiency. Further analysis on model predictions shines light on the types of commonsense knowledge that language models capture well.
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191