


Data silos create barriers in accessing and utilizing data dispersed over networks. Directly sharing data easily suffers from the long downloading time, the single point failure and the untraceable data usage. In this paper, we present Minerva, a peer-to-peer cross-cluster data query system based on InterPlanetary File System (IPFS). Minerva makes use of the distributed Hash table (DHT) lookup to pinpoint the locations that store content chunks. We theoretically model the DHT query delay and introduce the fat Merkle tree structure as well as the DHT caching to reduce it. We design the query plan for read and write operations on top of Apache Drill that enables the collaborative query with decentralized workers. We conduct comprehensive experiments on Minerva, and the results show that Minerva achieves up to $2.08 \times$ query performance acceleration compared to the original IPFS data query, and could complete data analysis queries on the Internet-like environments within an average latency of $0.615$ second. With collaborative query, Minerva could perform up to $1.39 \times$ performance acceleration than centralized query with raw data shipment.
相關內容
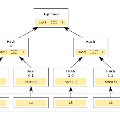
分布式哈希表技術(Distributed Hash Table)簡稱DHT,類似Tracker的根據種子特征碼返回種子信息的網絡·是一種分布式存儲方法。在不需要服務器的情況下,每個客戶端負責一個小范圍的路由,并負責存儲一小部分數據,從而實現整個DHT網絡的尋址和存儲。新版BitComet允許同行連接DHT網絡和Tracker,也就是說在完全不連上[Tracker服務器的情況下,也可以很好的下載,因為它可以在DHT網絡中尋找下載同一文件的其他用戶。BitComet的DHT網絡協議和BitTorrent今年5月測試版的協議完全兼容,也就是說可以連入一個同DHT網絡分享數據。
Recently, a large number of Low Earth Orbit (LEO) satellites have been launched and deployed successfully in space by commercial companies, such as SpaceX. Due to multimodal sensors equipped by the LEO satellites, they serve not only for communication but also for various machine learning applications, such as space modulation recognition, remote sensing image classification, etc. However, the ground station (GS) may be incapable of downloading such a large volume of raw sensing data for centralized model training due to the limited contact time with LEO satellites (e.g. 5 minutes). Therefore, federated learning (FL) has emerged as the promising solution to address this problem via on-device training. Unfortunately, to enable FL on LEO satellites, we still face three critical challenges that are i) heterogeneous computing and memory capabilities, ii) limited uplink rate, and iii) model staleness. To this end, we propose FedSN as a general FL framework to tackle the above challenges, and fully explore data diversity on LEO satellites. Specifically, we first present a novel sub-structure scheme to enable heterogeneous local model training considering different computing, memory, and communication constraints on LEO satellites. Additionally, we propose a pseudo-synchronous model aggregation strategy to dynamically schedule model aggregation for compensating model staleness. To further demonstrate the effectiveness of the FedSN, we evaluate it using space modulation recognition and remote sensing image classification tasks by leveraging the data from real-world satellite networks. Extensive experimental results demonstrate that FedSN framework achieves higher accuracy, lower computing, and communication overhead than the state-of-the-art benchmarks and the effectiveness of each components in FedSN.
Denoising diffusion models represent a recent emerging topic in computer vision, demonstrating remarkable results in the area of generative modeling. A diffusion model is a deep generative model that is based on two stages, a forward diffusion stage and a reverse diffusion stage. In the forward diffusion stage, the input data is gradually perturbed over several steps by adding Gaussian noise. In the reverse stage, a model is tasked at recovering the original input data by learning to gradually reverse the diffusion process, step by step. Diffusion models are widely appreciated for the quality and diversity of the generated samples, despite their known computational burdens, i.e. low speeds due to the high number of steps involved during sampling. In this survey, we provide a comprehensive review of articles on denoising diffusion models applied in vision, comprising both theoretical and practical contributions in the field. First, we identify and present three generic diffusion modeling frameworks, which are based on denoising diffusion probabilistic models, noise conditioned score networks, and stochastic differential equations. We further discuss the relations between diffusion models and other deep generative models, including variational auto-encoders, generative adversarial networks, energy-based models, autoregressive models and normalizing flows. Then, we introduce a multi-perspective categorization of diffusion models applied in computer vision. Finally, we illustrate the current limitations of diffusion models and envision some interesting directions for future research.
Graph neural networks (GNNs) have demonstrated a significant boost in prediction performance on graph data. At the same time, the predictions made by these models are often hard to interpret. In that regard, many efforts have been made to explain the prediction mechanisms of these models from perspectives such as GNNExplainer, XGNN and PGExplainer. Although such works present systematic frameworks to interpret GNNs, a holistic review for explainable GNNs is unavailable. In this survey, we present a comprehensive review of explainability techniques developed for GNNs. We focus on explainable graph neural networks and categorize them based on the use of explainable methods. We further provide the common performance metrics for GNNs explanations and point out several future research directions.
Vast amount of data generated from networks of sensors, wearables, and the Internet of Things (IoT) devices underscores the need for advanced modeling techniques that leverage the spatio-temporal structure of decentralized data due to the need for edge computation and licensing (data access) issues. While federated learning (FL) has emerged as a framework for model training without requiring direct data sharing and exchange, effectively modeling the complex spatio-temporal dependencies to improve forecasting capabilities still remains an open problem. On the other hand, state-of-the-art spatio-temporal forecasting models assume unfettered access to the data, neglecting constraints on data sharing. To bridge this gap, we propose a federated spatio-temporal model -- Cross-Node Federated Graph Neural Network (CNFGNN) -- which explicitly encodes the underlying graph structure using graph neural network (GNN)-based architecture under the constraint of cross-node federated learning, which requires that data in a network of nodes is generated locally on each node and remains decentralized. CNFGNN operates by disentangling the temporal dynamics modeling on devices and spatial dynamics on the server, utilizing alternating optimization to reduce the communication cost, facilitating computations on the edge devices. Experiments on the traffic flow forecasting task show that CNFGNN achieves the best forecasting performance in both transductive and inductive learning settings with no extra computation cost on edge devices, while incurring modest communication cost.
Conventional unsupervised multi-source domain adaptation (UMDA) methods assume all source domains can be accessed directly. This neglects the privacy-preserving policy, that is, all the data and computations must be kept decentralized. There exists three problems in this scenario: (1) Minimizing the domain distance requires the pairwise calculation of the data from source and target domains, which is not accessible. (2) The communication cost and privacy security limit the application of UMDA methods (e.g., the domain adversarial training). (3) Since users have no authority to check the data quality, the irrelevant or malicious source domains are more likely to appear, which causes negative transfer. In this study, we propose a privacy-preserving UMDA paradigm named Knowledge Distillation based Decentralized Domain Adaptation (KD3A), which performs domain adaptation through the knowledge distillation on models from different source domains. KD3A solves the above problems with three components: (1) A multi-source knowledge distillation method named Knowledge Vote to learn high-quality domain consensus knowledge. (2) A dynamic weighting strategy named Consensus Focus to identify both the malicious and irrelevant domains. (3) A decentralized optimization strategy for domain distance named BatchNorm MMD. The extensive experiments on DomainNet demonstrate that KD3A is robust to the negative transfer and brings a 100x reduction of communication cost compared with other decentralized UMDA methods. Moreover, our KD3A significantly outperforms state-of-the-art UMDA approaches.
We present CoDEx, a set of knowledge graph completion datasets extracted from Wikidata and Wikipedia that improve upon existing knowledge graph completion benchmarks in scope and level of difficulty. In terms of scope, CoDEx comprises three knowledge graphs varying in size and structure, multilingual descriptions of entities and relations, and tens of thousands of hard negative triples that are plausible but verified to be false. To characterize CoDEx, we contribute thorough empirical analyses and benchmarking experiments. First, we analyze each CoDEx dataset in terms of logical relation patterns. Next, we report baseline link prediction and triple classification results on CoDEx for five extensively tuned embedding models. Finally, we differentiate CoDEx from the popular FB15K-237 knowledge graph completion dataset by showing that CoDEx covers more diverse and interpretable content, and is a more difficult link prediction benchmark. Data, code, and pretrained models are available at //bit.ly/2EPbrJs.
A large number of real-world graphs or networks are inherently heterogeneous, involving a diversity of node types and relation types. Heterogeneous graph embedding is to embed rich structural and semantic information of a heterogeneous graph into low-dimensional node representations. Existing models usually define multiple metapaths in a heterogeneous graph to capture the composite relations and guide neighbor selection. However, these models either omit node content features, discard intermediate nodes along the metapath, or only consider one metapath. To address these three limitations, we propose a new model named Metapath Aggregated Graph Neural Network (MAGNN) to boost the final performance. Specifically, MAGNN employs three major components, i.e., the node content transformation to encapsulate input node attributes, the intra-metapath aggregation to incorporate intermediate semantic nodes, and the inter-metapath aggregation to combine messages from multiple metapaths. Extensive experiments on three real-world heterogeneous graph datasets for node classification, node clustering, and link prediction show that MAGNN achieves more accurate prediction results than state-of-the-art baselines.
Graph convolutional networks (GCNs) have recently become one of the most powerful tools for graph analytics tasks in numerous applications, ranging from social networks and natural language processing to bioinformatics and chemoinformatics, thanks to their ability to capture the complex relationships between concepts. At present, the vast majority of GCNs use a neighborhood aggregation framework to learn a continuous and compact vector, then performing a pooling operation to generalize graph embedding for the classification task. These approaches have two disadvantages in the graph classification task: (1)when only the largest sub-graph structure ($k$-hop neighbor) is used for neighborhood aggregation, a large amount of early-stage information is lost during the graph convolution step; (2) simple average/sum pooling or max pooling utilized, which loses the characteristics of each node and the topology between nodes. In this paper, we propose a novel framework called, dual attention graph convolutional networks (DAGCN) to address these problems. DAGCN automatically learns the importance of neighbors at different hops using a novel attention graph convolution layer, and then employs a second attention component, a self-attention pooling layer, to generalize the graph representation from the various aspects of a matrix graph embedding. The dual attention network is trained in an end-to-end manner for the graph classification task. We compare our model with state-of-the-art graph kernels and other deep learning methods. The experimental results show that our framework not only outperforms other baselines but also achieves a better rate of convergence.
Distant supervision can effectively label data for relation extraction, but suffers from the noise labeling problem. Recent works mainly perform soft bag-level noise reduction strategies to find the relatively better samples in a sentence bag, which is suboptimal compared with making a hard decision of false positive samples in sentence level. In this paper, we introduce an adversarial learning framework, which we named DSGAN, to learn a sentence-level true-positive generator. Inspired by Generative Adversarial Networks, we regard the positive samples generated by the generator as the negative samples to train the discriminator. The optimal generator is obtained until the discrimination ability of the discriminator has the greatest decline. We adopt the generator to filter distant supervision training dataset and redistribute the false positive instances into the negative set, in which way to provide a cleaned dataset for relation classification. The experimental results show that the proposed strategy significantly improves the performance of distant supervision relation extraction comparing to state-of-the-art systems.
We present Generative Adversarial Capsule Network (CapsuleGAN), a framework that uses capsule networks (CapsNets) instead of the standard convolutional neural networks (CNNs) as discriminators within the generative adversarial network (GAN) setting, while modeling image data. We provide guidelines for designing CapsNet discriminators and the updated GAN objective function, which incorporates the CapsNet margin loss, for training CapsuleGAN models. We show that CapsuleGAN outperforms convolutional-GAN at modeling image data distribution on the MNIST dataset of handwritten digits, evaluated on the generative adversarial metric and at semi-supervised image classification.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191