


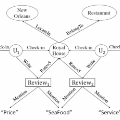
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
相關內容
IFIP TC13 Conference on Human-Computer Interaction是人機交互領域的研究者和實踐者展示其工作的重要平臺。多年來,這些會議吸引了來自幾個國家和文化的研究人員。官網鏈接: ·
Vision
·
變換
·
詞元分析器
·
Extensibility
·
Many adaptations of transformers have emerged to address the single-modal vision tasks, where self-attention modules are stacked to handle input sources like images. Intuitively, feeding multiple modalities of data to vision transformers could improve the performance, yet the inner-modal attentive weights may also be diluted, which could thus undermine the final performance. In this paper, we propose a multimodal token fusion method (TokenFusion), tailored for transformer-based vision tasks. To effectively fuse multiple modalities, TokenFusion dynamically detects uninformative tokens and substitutes these tokens with projected and aggregated inter-modal features. Residual positional alignment is also adopted to enable explicit utilization of the inter-modal alignments after fusion. The design of TokenFusion allows the transformer to learn correlations among multimodal features, while the single-modal transformer architecture remains largely intact. Extensive experiments are conducted on a variety of homogeneous and heterogeneous modalities and demonstrate that TokenFusion surpasses state-of-the-art methods in three typical vision tasks: multimodal image-to-image translation, RGB-depth semantic segmentation, and 3D object detection with point cloud and images.
Recurrent models have been dominating the field of neural machine translation (NMT) for the past few years. Transformers \citep{vaswani2017attention}, have radically changed it by proposing a novel architecture that relies on a feed-forward backbone and self-attention mechanism. Although Transformers are powerful, they could fail to properly encode sequential/positional information due to their non-recurrent nature. To solve this problem, position embeddings are defined exclusively for each time step to enrich word information. However, such embeddings are fixed after training regardless of the task and the word ordering system of the source or target language. In this paper, we propose a novel architecture with new position embeddings depending on the input text to address this shortcoming by taking the order of target words into consideration. Instead of using predefined position embeddings, our solution \textit{generates} new embeddings to refine each word's position information. Since we do not dictate the position of source tokens and learn them in an end-to-end fashion, we refer to our method as \textit{dynamic} position encoding (DPE). We evaluated the impact of our model on multiple datasets to translate from English into German, French, and Italian and observed meaningful improvements in comparison to the original Transformer.
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website //pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
This paper explores meta-learning in sequential recommendation to alleviate the item cold-start problem. Sequential recommendation aims to capture user's dynamic preferences based on historical behavior sequences and acts as a key component of most online recommendation scenarios. However, most previous methods have trouble recommending cold-start items, which are prevalent in those scenarios. As there is generally no side information in the setting of sequential recommendation task, previous cold-start methods could not be applied when only user-item interactions are available. Thus, we propose a Meta-learning-based Cold-Start Sequential Recommendation Framework, namely Mecos, to mitigate the item cold-start problem in sequential recommendation. This task is non-trivial as it targets at an important problem in a novel and challenging context. Mecos effectively extracts user preference from limited interactions and learns to match the target cold-start item with the potential user. Besides, our framework can be painlessly integrated with neural network-based models. Extensive experiments conducted on three real-world datasets verify the superiority of Mecos, with the average improvement up to 99%, 91%, and 70% in HR@10 over state-of-the-art baseline methods.
Recently pre-trained language representation models such as BERT have shown great success when fine-tuned on downstream tasks including information retrieval (IR). However, pre-training objectives tailored for ad-hoc retrieval have not been well explored. In this paper, we propose Pre-training with Representative wOrds Prediction (PROP) for ad-hoc retrieval. PROP is inspired by the classical statistical language model for IR, specifically the query likelihood model, which assumes that the query is generated as the piece of text representative of the "ideal" document. Based on this idea, we construct the representative words prediction (ROP) task for pre-training. Given an input document, we sample a pair of word sets according to the document language model, where the set with higher likelihood is deemed as more representative of the document. We then pre-train the Transformer model to predict the pairwise preference between the two word sets, jointly with the Masked Language Model (MLM) objective. By further fine-tuning on a variety of representative downstream ad-hoc retrieval tasks, PROP achieves significant improvements over baselines without pre-training or with other pre-training methods. We also show that PROP can achieve exciting performance under both the zero- and low-resource IR settings. The code and pre-trained models are available at //github.com/Albert-Ma/PROP.
For better user experience and business effectiveness, Click-Through Rate (CTR) prediction has been one of the most important tasks in E-commerce. Although extensive CTR prediction models have been proposed, learning good representation of items from multimodal features is still less investigated, considering an item in E-commerce usually contains multiple heterogeneous modalities. Previous works either concatenate the multiple modality features, that is equivalent to giving a fixed importance weight to each modality; or learn dynamic weights of different modalities for different items through technique like attention mechanism. However, a problem is that there usually exists common redundant information across multiple modalities. The dynamic weights of different modalities computed by using the redundant information may not correctly reflect the different importance of each modality. To address this, we explore the complementarity and redundancy of modalities by considering modality-specific and modality-invariant features differently. We propose a novel Multimodal Adversarial Representation Network (MARN) for the CTR prediction task. A multimodal attention network first calculates the weights of multiple modalities for each item according to its modality-specific features. Then a multimodal adversarial network learns modality-invariant representations where a double-discriminators strategy is introduced. Finally, we achieve the multimodal item representations by combining both modality-specific and modality-invariant representations. We conduct extensive experiments on both public and industrial datasets, and the proposed method consistently achieves remarkable improvements to the state-of-the-art methods. Moreover, the approach has been deployed in an operational E-commerce system and online A/B testing further demonstrates the effectiveness.
Recent years have witnessed the emerging success of graph neural networks (GNNs) for modeling structured data. However, most GNNs are designed for homogeneous graphs, in which all nodes and edges belong to the same types, making them infeasible to represent heterogeneous structures. In this paper, we present the Heterogeneous Graph Transformer (HGT) architecture for modeling Web-scale heterogeneous graphs. To model heterogeneity, we design node- and edge-type dependent parameters to characterize the heterogeneous attention over each edge, empowering HGT to maintain dedicated representations for different types of nodes and edges. To handle dynamic heterogeneous graphs, we introduce the relative temporal encoding technique into HGT, which is able to capture the dynamic structural dependency with arbitrary durations. To handle Web-scale graph data, we design the heterogeneous mini-batch graph sampling algorithm---HGSampling---for efficient and scalable training. Extensive experiments on the Open Academic Graph of 179 million nodes and 2 billion edges show that the proposed HGT model consistently outperforms all the state-of-the-art GNN baselines by 9%--21% on various downstream tasks.
Graph Neural Networks (GNNs), which generalize deep neural networks to graph-structured data, have drawn considerable attention and achieved state-of-the-art performance in numerous graph related tasks. However, existing GNN models mainly focus on designing graph convolution operations. The graph pooling (or downsampling) operations, that play an important role in learning hierarchical representations, are usually overlooked. In this paper, we propose a novel graph pooling operator, called Hierarchical Graph Pooling with Structure Learning (HGP-SL), which can be integrated into various graph neural network architectures. HGP-SL incorporates graph pooling and structure learning into a unified module to generate hierarchical representations of graphs. More specifically, the graph pooling operation adaptively selects a subset of nodes to form an induced subgraph for the subsequent layers. To preserve the integrity of graph's topological information, we further introduce a structure learning mechanism to learn a refined graph structure for the pooled graph at each layer. By combining HGP-SL operator with graph neural networks, we perform graph level representation learning with focus on graph classification task. Experimental results on six widely used benchmarks demonstrate the effectiveness of our proposed model.
Dense video captioning aims to generate text descriptions for all events in an untrimmed video. This involves both detecting and describing events. Therefore, all previous methods on dense video captioning tackle this problem by building two models, i.e. an event proposal and a captioning model, for these two sub-problems. The models are either trained separately or in alternation. This prevents direct influence of the language description to the event proposal, which is important for generating accurate descriptions. To address this problem, we propose an end-to-end transformer model for dense video captioning. The encoder encodes the video into appropriate representations. The proposal decoder decodes from the encoding with different anchors to form video event proposals. The captioning decoder employs a masking network to restrict its attention to the proposal event over the encoding feature. This masking network converts the event proposal to a differentiable mask, which ensures the consistency between the proposal and captioning during training. In addition, our model employs a self-attention mechanism, which enables the use of efficient non-recurrent structure during encoding and leads to performance improvements. We demonstrate the effectiveness of this end-to-end model on ActivityNet Captions and YouCookII datasets, where we achieved 10.12 and 6.58 METEOR score, respectively.
State-of-the-art recommendation algorithms -- especially the collaborative filtering (CF) based approaches with shallow or deep models -- usually work with various unstructured information sources for recommendation, such as textual reviews, visual images, and various implicit or explicit feedbacks. Though structured knowledge bases were considered in content-based approaches, they have been largely neglected recently due to the availability of vast amount of data, and the learning power of many complex models. However, structured knowledge bases exhibit unique advantages in personalized recommendation systems. When the explicit knowledge about users and items is considered for recommendation, the system could provide highly customized recommendations based on users' historical behaviors. A great challenge for using knowledge bases for recommendation is how to integrated large-scale structured and unstructured data, while taking advantage of collaborative filtering for highly accurate performance. Recent achievements on knowledge base embedding sheds light on this problem, which makes it possible to learn user and item representations while preserving the structure of their relationship with external knowledge. In this work, we propose to reason over knowledge base embeddings for personalized recommendation. Specifically, we propose a knowledge base representation learning approach to embed heterogeneous entities for recommendation. Experimental results on real-world dataset verified the superior performance of our approach compared with state-of-the-art baselines.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191