
The acoustic sensitivity of Autism Spectrum Disorder (ASD) individuals highly impacts their intelligibility in noisy urban environments. In this Letter, the disturbance sensing level is examined with perceptual listening tests that demonstrate the impact of their append High Internal Noise (HIN) profile on intelligibility. This particular sensing level is then proposed as additional aid to ASD diagnosis. In this Letter, a novel intelligibility enhancement scheme is also introduced for ASD particular circumstances. For this proposal, harmonic features estimated from speech signal frames are considered as center frequencies of auditory filterbanks. A gain factor is further applied to the output of the filtered samples. The experimental results demonstrate that the proposal improved the acoustic intelligibility of ASD and Neurotypicals (NT) people considering four acoustic noises at different signal-to-noise ratios.
相關內容
異構信(xin)息(xi)網絡 (Hetegeneous Information Network 以下(xia)簡稱 HIN),是由 UIUC 的 Han Jiawei 和 UCLA 的 Sun Yizhou 在 2011 年的 VLDB 論(lun)文中首次提出。
Existing knowledge graph (KG) embedding models have primarily focused on static KGs. However, real-world KGs do not remain static, but rather evolve and grow in tandem with the development of KG applications. Consequently, new facts and previously unseen entities and relations continually emerge, necessitating an embedding model that can quickly learn and transfer new knowledge through growth. Motivated by this, we delve into an expanding field of KG embedding in this paper, i.e., lifelong KG embedding. We consider knowledge transfer and retention of the learning on growing snapshots of a KG without having to learn embeddings from scratch. The proposed model includes a masked KG autoencoder for embedding learning and update, with an embedding transfer strategy to inject the learned knowledge into the new entity and relation embeddings, and an embedding regularization method to avoid catastrophic forgetting. To investigate the impacts of different aspects of KG growth, we construct four datasets to evaluate the performance of lifelong KG embedding. Experimental results show that the proposed model outperforms the state-of-the-art inductive and lifelong embedding baselines.
Graph Convolutional Networks (GCNs) have been widely applied in various fields due to their significant power on processing graph-structured data. Typical GCN and its variants work under a homophily assumption (i.e., nodes with same class are prone to connect to each other), while ignoring the heterophily which exists in many real-world networks (i.e., nodes with different classes tend to form edges). Existing methods deal with heterophily by mainly aggregating higher-order neighborhoods or combing the immediate representations, which leads to noise and irrelevant information in the result. But these methods did not change the propagation mechanism which works under homophily assumption (that is a fundamental part of GCNs). This makes it difficult to distinguish the representation of nodes from different classes. To address this problem, in this paper we design a novel propagation mechanism, which can automatically change the propagation and aggregation process according to homophily or heterophily between node pairs. To adaptively learn the propagation process, we introduce two measurements of homophily degree between node pairs, which is learned based on topological and attribute information, respectively. Then we incorporate the learnable homophily degree into the graph convolution framework, which is trained in an end-to-end schema, enabling it to go beyond the assumption of homophily. More importantly, we theoretically prove that our model can constrain the similarity of representations between nodes according to their homophily degree. Experiments on seven real-world datasets demonstrate that this new approach outperforms the state-of-the-art methods under heterophily or low homophily, and gains competitive performance under homophily.
Recent contrastive representation learning methods rely on estimating mutual information (MI) between multiple views of an underlying context. E.g., we can derive multiple views of a given image by applying data augmentation, or we can split a sequence into views comprising the past and future of some step in the sequence. Contrastive lower bounds on MI are easy to optimize, but have a strong underestimation bias when estimating large amounts of MI. We propose decomposing the full MI estimation problem into a sum of smaller estimation problems by splitting one of the views into progressively more informed subviews and by applying the chain rule on MI between the decomposed views. This expression contains a sum of unconditional and conditional MI terms, each measuring modest chunks of the total MI, which facilitates approximation via contrastive bounds. To maximize the sum, we formulate a contrastive lower bound on the conditional MI which can be approximated efficiently. We refer to our general approach as Decomposed Estimation of Mutual Information (DEMI). We show that DEMI can capture a larger amount of MI than standard non-decomposed contrastive bounds in a synthetic setting, and learns better representations in a vision domain and for dialogue generation.
Vast amount of data generated from networks of sensors, wearables, and the Internet of Things (IoT) devices underscores the need for advanced modeling techniques that leverage the spatio-temporal structure of decentralized data due to the need for edge computation and licensing (data access) issues. While federated learning (FL) has emerged as a framework for model training without requiring direct data sharing and exchange, effectively modeling the complex spatio-temporal dependencies to improve forecasting capabilities still remains an open problem. On the other hand, state-of-the-art spatio-temporal forecasting models assume unfettered access to the data, neglecting constraints on data sharing. To bridge this gap, we propose a federated spatio-temporal model -- Cross-Node Federated Graph Neural Network (CNFGNN) -- which explicitly encodes the underlying graph structure using graph neural network (GNN)-based architecture under the constraint of cross-node federated learning, which requires that data in a network of nodes is generated locally on each node and remains decentralized. CNFGNN operates by disentangling the temporal dynamics modeling on devices and spatial dynamics on the server, utilizing alternating optimization to reduce the communication cost, facilitating computations on the edge devices. Experiments on the traffic flow forecasting task show that CNFGNN achieves the best forecasting performance in both transductive and inductive learning settings with no extra computation cost on edge devices, while incurring modest communication cost.

Deployment of Internet of Things (IoT) devices and Data Fusion techniques have gained popularity in public and government domains. This usually requires capturing and consolidating data from multiple sources. As datasets do not necessarily originate from identical sensors, fused data typically results in a complex data problem. Because military is investigating how heterogeneous IoT devices can aid processes and tasks, we investigate a multi-sensor approach. Moreover, we propose a signal to image encoding approach to transform information (signal) to integrate (fuse) data from IoT wearable devices to an image which is invertible and easier to visualize supporting decision making. Furthermore, we investigate the challenge of enabling an intelligent identification and detection operation and demonstrate the feasibility of the proposed Deep Learning and Anomaly Detection models that can support future application that utilizes hand gesture data from wearable devices.
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Graph Neural Networks (GNNs) have recently become increasingly popular due to their ability to learn complex systems of relations or interactions arising in a broad spectrum of problems ranging from biology and particle physics to social networks and recommendation systems. Despite the plethora of different models for deep learning on graphs, few approaches have been proposed thus far for dealing with graphs that present some sort of dynamic nature (e.g. evolving features or connectivity over time). In this paper, we present Temporal Graph Networks (TGNs), a generic, efficient framework for deep learning on dynamic graphs represented as sequences of timed events. Thanks to a novel combination of memory modules and graph-based operators, TGNs are able to significantly outperform previous approaches being at the same time more computationally efficient. We furthermore show that several previous models for learning on dynamic graphs can be cast as specific instances of our framework. We perform a detailed ablation study of different components of our framework and devise the best configuration that achieves state-of-the-art performance on several transductive and inductive prediction tasks for dynamic graphs.
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
High spectral dimensionality and the shortage of annotations make hyperspectral image (HSI) classification a challenging problem. Recent studies suggest that convolutional neural networks can learn discriminative spatial features, which play a paramount role in HSI interpretation. However, most of these methods ignore the distinctive spectral-spatial characteristic of hyperspectral data. In addition, a large amount of unlabeled data remains an unexploited gold mine for efficient data use. Therefore, we proposed an integration of generative adversarial networks (GANs) and probabilistic graphical models for HSI classification. Specifically, we used a spectral-spatial generator and a discriminator to identify land cover categories of hyperspectral cubes. Moreover, to take advantage of a large amount of unlabeled data, we adopted a conditional random field to refine the preliminary classification results generated by GANs. Experimental results obtained using two commonly studied datasets demonstrate that the proposed framework achieved encouraging classification accuracy using a small number of data for training.
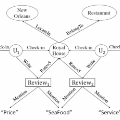
Recommender System (RS) is a hot area where artificial intelligence (AI) techniques can be effectively applied to improve performance. Since the well-known Netflix Challenge, collaborative filtering (CF) has become the most popular and effective recommendation method. Despite their success in CF, various AI techniques still have to face the data sparsity and cold start problems. Previous works tried to solve these two problems by utilizing auxiliary information, such as social connections among users and meta-data of items. However, they process different types of information separately, leading to information loss. In this work, we propose to utilize Heterogeneous Information Network (HIN), which is a natural and general representation of different types of data, to enhance CF-based recommending methods. HIN-based recommender systems face two problems: how to represent high-level semantics for recommendation and how to fuse the heterogeneous information to recommend. To address these problems, we propose to applying meta-graph to HIN-based RS and solve the information fusion problem with a "matrix factorization (MF) + factorization machine (FM)" framework. For the "MF" part, we obtain user-item similarity matrices from each meta-graph and adopt low-rank matrix approximation to get latent features for both users and items. For the "FM" part, we propose to apply FM with Group lasso (FMG) on the obtained features to simultaneously predict missing ratings and select useful meta-graphs. Experimental results on two large real-world datasets, i.e., Amazon and Yelp, show that our proposed approach is better than that of the state-of-the-art FM and other HIN-based recommending methods.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191