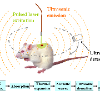

Photoacoustic imaging (PAI) represents an innovative biomedical imaging modality that harnesses the advantages of optical resolution and acoustic penetration depth while ensuring enhanced safety. Despite its promising potential across a diverse array of preclinical and clinical applications, the clinical implementation of PAI faces significant challenges, including the trade-off between penetration depth and spatial resolution, as well as the demand for faster imaging speeds. This paper explores the fundamental principles underlying PAI, with a particular emphasis on three primary implementations: photoacoustic computed tomography (PACT), photoacoustic microscopy (PAM), and photoacoustic endoscopy (PAE). We undertake a critical assessment of their respective strengths and practical limitations. Furthermore, recent developments in utilizing conventional or deep learning (DL) methodologies for image reconstruction and artefact mitigation across PACT, PAM, and PAE are outlined, demonstrating considerable potential to enhance image quality and accelerate imaging processes. Furthermore, this paper examines the recent developments in quantitative analysis within PAI, including the quantification of haemoglobin concentration, oxygen saturation, and other physiological parameters within tissues. Finally, our discussion encompasses current trends and future directions in PAI research while emphasizing the transformative impact of deep learning on advancing PAI.
相關內容
Understanding relations arising out of interactions among entities can be very difficult, and predicting them is even more challenging. This problem has many applications in various fields, such as financial networks and e-commerce. These relations can involve much more complexities than just involving more than two entities. One such scenario is evolving recursive relations between multiple entities, and so far, this is still an open problem. This work addresses the problem of forecasting higher-order interaction events that can be multi-relational and recursive. We pose the problem in the framework of representation learning of temporal hypergraphs that can capture complex relationships involving multiple entities. The proposed model, \textit{Relational Recursive Hyperedge Temporal Point Process} (RRHyperTPP) uses an encoder that learns a dynamic node representation based on the historical interaction patterns and then a hyperedge link prediction-based decoder to model the occurrence of interaction events. These learned representations are then used for downstream tasks involving forecasting the type and time of interactions. The main challenge in learning from hyperedge events is that the number of possible hyperedges grows exponentially with the number of nodes in the network. This will make the computation of negative log-likelihood of the temporal point process expensive, as the calculation of survival function requires a summation over all possible hyperedges. In our work, we develop a noise contrastive estimation method to learn the parameters of our model, and we have experimentally shown that our models perform better than previous state-of-the-art methods for interaction forecasting.
Object detection is a critical task in computer vision, with applications in various domains such as autonomous driving and urban scene monitoring. However, deep learning-based approaches often demand large volumes of annotated data, which are costly and difficult to acquire, particularly in complex and unpredictable real-world environments. This dependency significantly hampers the generalization capability of existing object detection techniques. To address this issue, we introduce a novel single-domain object detection generalization method, named GoDiff, which leverages a pre-trained model to enhance generalization in unseen domains. Central to our approach is the Pseudo Target Data Generation (PTDG) module, which employs a latent diffusion model to generate pseudo-target domain data that preserves source domain characteristics while introducing stylistic variations. By integrating this pseudo data with source domain data, we diversify the training dataset. Furthermore, we introduce a cross-style instance normalization technique to blend style features from different domains generated by the PTDG module, thereby increasing the detector's robustness. Experimental results demonstrate that our method not only enhances the generalization ability of existing detectors but also functions as a plug-and-play enhancement for other single-domain generalization methods, achieving state-of-the-art performance in autonomous driving scenarios.
Parallel kinematic manipulators (PKM) are characterized by closed kinematic loops, due to the parallel arrangement of limbs but also due to the existence of kinematic loops within the limbs. Moreover, many PKM are built with limbs constructed by serially combining kinematic loops. Such limbs are called hybrid, which form a particular class of complex limbs. Design and model-based control requires accurate dynamic PKM models desirably without model simplifications. Dynamics modeling then necessitates kinematic relations of all members of the PKM, in contrast to the standard kinematics modeling of PKM, where only the forward and inverse kinematics solution for the manipulator (relating input and output motions) are computed. This becomes more involved for PKM with hybrid limbs. In this paper a modular modeling approach is employed, where limbs are treated separately, and the individual dynamic equations of motions (EOM) are subsequently assembled to the overall model. Key to the kinematic modeling is the constraint resolution for the individual loops within the limbs. This local constraint resolution is a special case of the general \emph{constraint embedding} technique. The proposed method finally allows for a systematic modeling of general PKM. The method is demonstrated for the IRSBot-2, where each limb comprises two independent loops.
We aim at the solution of inverse problems in imaging, by combining a penalized sparse representation of image patches with an unconstrained smooth one. This allows for a straightforward interpretation of the reconstruction. We formulate the optimization as a bilevel problem. The inner problem deploys classical algorithms while the outer problem optimizes the dictionary and the regularizer parameters through supervised learning. The process is carried out via implicit differentiation and gradient-based optimization. We evaluate our method for denoising, super-resolution, and compressed-sensing magnetic-resonance imaging. We compare it to other classical models as well as deep-learning-based methods and show that it always outperforms the former and also the latter in some instances.
Accurate human motion prediction is crucial for safe human-robot collaboration but remains challenging due to the complexity of modeling intricate and variable human movements. This paper presents Parallel Multi-scale Incremental Prediction (PMS), a novel framework that explicitly models incremental motion across multiple spatio-temporal scales to capture subtle joint evolutions and global trajectory shifts. PMS encodes these multi-scale increments using parallel sequence branches, enabling iterative refinement of predictions. A multi-stage training procedure with a full-timeline loss integrates temporal context. Extensive experiments on four datasets demonstrate substantial improvements in continuity, biomechanical consistency, and long-term forecast stability by modeling inter-frame increments. PMS achieves state-of-the-art performance, increasing prediction accuracy by 16.3%-64.2% over previous methods. The proposed multi-scale incremental approach provides a powerful technique for advancing human motion prediction capabilities critical for seamless human-robot interaction.
Ptychography is a scanning coherent diffractive imaging technique that enables imaging nanometer-scale features in extended samples. One main challenge is that widely used iterative image reconstruction methods often require significant amount of overlap between adjacent scan locations, leading to large data volumes and prolonged acquisition times. To address this key limitation, this paper proposes a Bayesian inversion method for ptychography that performs effectively even with less overlap between neighboring scan locations. Furthermore, the proposed method can quantify the inherent uncertainty on the ptychographic object, which is created by the ill-posed nature of the ptychographic inverse problem. At a high level, the proposed method first utilizes a deep generative model to learn the prior distribution of the object and then generates samples from the posterior distribution of the object by using a Markov Chain Monte Carlo algorithm. Our results from simulated ptychography experiments show that the proposed framework can consistently outperform a widely used iterative reconstruction algorithm in cases of reduced overlap. Moreover, the proposed framework can provide uncertainty estimates that closely correlate with the true error, which is not available in practice. The project website is available here.
The implementation of 5G and the future deployment of 6G necessitate the utilization of optical networks that possess substantial capacity and exhibit minimal latency. The dynamic arrival and departure of connection requests in optical networks result in particular central links experiencing more traffic and congestion than non-central links. The occurrence of congested links leads to service blocking despite the availability of resources within the network, restricting the efficient utilization of network resources. The available algorithms in the literature that aim to balance load among network links offer a trade-off between blocking performance and algorithmic complexity, thus increasing service provisioning time. This work proposes a dynamic routing-based congestion-aware routing, modulation, core, and spectrum assignment (RMCSA) algorithm for space division multiplexing elastic optical networks (SDM-EONs). The algorithm finds alternative candidate paths based on real-time link occupancy metrics to minimize blocking due to link congestion under dynamic traffic scenarios. As a result, the algorithm reduces the formation of congestion hotspots in the network owing to link-betweenness centrality. We have performed extensive simulations using two realistic network topologies to compare the performance of the proposed algorithm with relevant RMCSA algorithms available in the literature. The simulation results verify the superior performance of our proposed algorithm compared to the benchmark Yen's K-shortest paths and K-Disjoint shortest paths RMCSA algorithms in connection blocking ratio and spectrum utilization efficiency. To expedite the route-finding process, we present a novel caching strategy that allows the proposed algorithm to demonstrate a much-reduced service delay time compared to the recently developed adaptive link weight-based load-balancing RMCSA algorithm.
Visual recognition is currently one of the most important and active research areas in computer vision, pattern recognition, and even the general field of artificial intelligence. It has great fundamental importance and strong industrial needs. Deep neural networks (DNNs) have largely boosted their performances on many concrete tasks, with the help of large amounts of training data and new powerful computation resources. Though recognition accuracy is usually the first concern for new progresses, efficiency is actually rather important and sometimes critical for both academic research and industrial applications. Moreover, insightful views on the opportunities and challenges of efficiency are also highly required for the entire community. While general surveys on the efficiency issue of DNNs have been done from various perspectives, as far as we are aware, scarcely any of them focused on visual recognition systematically, and thus it is unclear which progresses are applicable to it and what else should be concerned. In this paper, we present the review of the recent advances with our suggestions on the new possible directions towards improving the efficiency of DNN-related visual recognition approaches. We investigate not only from the model but also the data point of view (which is not the case in existing surveys), and focus on three most studied data types (images, videos and points). This paper attempts to provide a systematic summary via a comprehensive survey which can serve as a valuable reference and inspire both researchers and practitioners who work on visual recognition problems.
Substantial efforts have been devoted more recently to presenting various methods for object detection in optical remote sensing images. However, the current survey of datasets and deep learning based methods for object detection in optical remote sensing images is not adequate. Moreover, most of the existing datasets have some shortcomings, for example, the numbers of images and object categories are small scale, and the image diversity and variations are insufficient. These limitations greatly affect the development of deep learning based object detection methods. In the paper, we provide a comprehensive review of the recent deep learning based object detection progress in both the computer vision and earth observation communities. Then, we propose a large-scale, publicly available benchmark for object DetectIon in Optical Remote sensing images, which we name as DIOR. The dataset contains 23463 images and 192472 instances, covering 20 object classes. The proposed DIOR dataset 1) is large-scale on the object categories, on the object instance number, and on the total image number; 2) has a large range of object size variations, not only in terms of spatial resolutions, but also in the aspect of inter- and intra-class size variability across objects; 3) holds big variations as the images are obtained with different imaging conditions, weathers, seasons, and image quality; and 4) has high inter-class similarity and intra-class diversity. The proposed benchmark can help the researchers to develop and validate their data-driven methods. Finally, we evaluate several state-of-the-art approaches on our DIOR dataset to establish a baseline for future research.

We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes. Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using explicit external tissue/organ localisation modules of cascaded convolutional neural networks (CNNs). AGs can be easily integrated into standard CNN architectures such as the U-Net model with minimal computational overhead while increasing the model sensitivity and prediction accuracy. The proposed Attention U-Net architecture is evaluated on two large CT abdominal datasets for multi-class image segmentation. Experimental results show that AGs consistently improve the prediction performance of U-Net across different datasets and training sizes while preserving computational efficiency. The code for the proposed architecture is publicly available.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191