


There has been rapid growth in biomedical literature, yet capturing the heterogeneity of the bibliographic information of these articles remains relatively understudied. Although graph mining research via heterogeneous graph neural networks has taken center stage, it remains unclear whether these approaches capture the heterogeneity of the PubMed database, a vast digital repository containing over 33 million articles. We introduce PubMed Graph Benchmark (PGB), a new benchmark dataset for evaluating heterogeneous graph embeddings for biomedical literature. The benchmark contains rich metadata including abstract, authors, citations, MeSH terms, MeSH hierarchy, and some other information. The benchmark contains three different evaluation tasks encompassing systematic reviews, node classification, and node clustering. In PGB, we aggregate the metadata associated with the biomedical articles from PubMed into a unified source and make the benchmark publicly available for any future works.
相關內容
While research in the field of transformer models has primarily focused on enhancing performance metrics such as accuracy and perplexity, practical applications in industry often necessitate a rigorous consideration of inference latency constraints. Addressing this challenge, we introduce SpeedLimit, a novel Neural Architecture Search (NAS) technique that optimizes accuracy whilst adhering to an upper-bound latency constraint. Our method incorporates 8-bit integer quantization in the search process to outperform the current state-of-the-art technique. Our results underline the feasibility and efficacy of seeking an optimal balance between performance and latency, providing new avenues for deploying state-of-the-art transformer models in latency-sensitive environments.
The Web, as a rich medium of diverse content, has been constantly under the threat of malicious entities exploiting its vulnerabilities, especially with the rapid proliferation of deep learning applications in various web services. One such vulnerability, crucial to the fidelity and integrity of web content, is the susceptibility of deep neural networks to adversarial perturbations, especially concerning images - a dominant form of data on the web. In light of the recent advancements in the robustness of classifiers, we delve deep into the intricacies of adversarial training (AT) and Jacobian regularization, two pivotal defenses. Our work {is the} first carefully analyzes and characterizes these two schools of approaches, both theoretically and empirically, to demonstrate how each approach impacts the robust learning of a classifier. Next, we propose our novel Optimal Transport with Jacobian regularization method, dubbed~\SystemName, jointly incorporating the input-output Jacobian regularization into the AT by leveraging the optimal transport theory. In particular, we employ the Sliced Wasserstein (SW) distance that can efficiently push the adversarial samples' representations closer to those of clean samples, regardless of the number of classes within the dataset. The SW distance provides the adversarial samples' movement directions, which are much more informative and powerful for the Jacobian regularization. Our empirical evaluations set a new standard in the domain, with our method achieving commendable accuracies of 51.41\% on the ~\CIFAR-10 and 28.49\% on the ~\CIFAR-100 datasets under the AutoAttack metric. In a real-world demonstration, we subject images sourced from the Internet to online adversarial attacks, reinforcing the efficacy and relevance of our model in defending against sophisticated web-image perturbations.
Anomaly detection in multivariate time series has emerged as a crucial challenge in time series research, with significant research implications in various fields such as fraud detection, fault diagnosis, and system state estimation. Reconstruction-based models have shown promising potential in recent years for detecting anomalies in time series data. However, due to the rapid increase in data scale and dimensionality, the issues of noise and Weak Identity Mapping (WIM) during time series reconstruction have become increasingly pronounced. To address this, we introduce a novel Adaptive Dynamic Neighbor Mask (ADNM) mechanism and integrate it with the Transformer and Denoising Diffusion Model, creating a new framework for multivariate time series anomaly detection, named Denoising Diffusion Mask Transformer (DDMT). The ADNM module is introduced to mitigate information leakage between input and output features during data reconstruction, thereby alleviating the problem of WIM during reconstruction. The Denoising Diffusion Transformer (DDT) employs the Transformer as an internal neural network structure for Denoising Diffusion Model. It learns the stepwise generation process of time series data to model the probability distribution of the data, capturing normal data patterns and progressively restoring time series data by removing noise, resulting in a clear recovery of anomalies. To the best of our knowledge, this is the first model that combines Denoising Diffusion Model and the Transformer for multivariate time series anomaly detection. Experimental evaluations were conducted on five publicly available multivariate time series anomaly detection datasets. The results demonstrate that the model effectively identifies anomalies in time series data, achieving state-of-the-art performance in anomaly detection.
Distributed optimization methods with random communication skips are gaining increasing attention due to their proven benefits in accelerating communication complexity. Nevertheless, existing research mainly focuses on centralized communication protocols for strongly convex deterministic settings. In this work, we provide a decentralized optimization method called RandCom, which incorporates probabilistic local updates. We analyze the performance of RandCom in stochastic non-convex, convex, and strongly convex settings and demonstrate its ability to asymptotically reduce communication overhead by the probability of communication. Additionally, we prove that RandCom achieves linear speedup as the number of nodes increases. In stochastic strongly convex settings, we further prove that RandCom can achieve linear speedup with network-independent stepsizes. Moreover, we apply RandCom to federated learning and provide positive results concerning the potential for achieving linear speedup and the suitability of the probabilistic local update approach for non-convex settings.
Multi-modal trajectory forecasting methods commonly evaluate using single-agent metrics (marginal metrics), such as minimum Average Displacement Error (ADE) and Final Displacement Error (FDE), which fail to capture joint performance of multiple interacting agents. Only focusing on marginal metrics can lead to unnatural predictions, such as colliding trajectories or diverging trajectories for people who are clearly walking together as a group. Consequently, methods optimized for marginal metrics lead to overly-optimistic estimations of performance, which is detrimental to progress in trajectory forecasting research. In response to the limitations of marginal metrics, we present the first comprehensive evaluation of state-of-the-art (SOTA) trajectory forecasting methods with respect to multi-agent metrics (joint metrics): JADE, JFDE, and collision rate. We demonstrate the importance of joint metrics as opposed to marginal metrics with quantitative evidence and qualitative examples drawn from the ETH / UCY and Stanford Drone datasets. We introduce a new loss function incorporating joint metrics that, when applied to a SOTA trajectory forecasting method, achieves a 7\% improvement in JADE / JFDE on the ETH / UCY datasets with respect to the previous SOTA. Our results also indicate that optimizing for joint metrics naturally leads to an improvement in interaction modeling, as evidenced by a 16\% decrease in mean collision rate on the ETH / UCY datasets with respect to the previous SOTA. Code is available at \texttt{\hyperlink{//github.com/ericaweng/joint-metrics-matter}{github.com/ericaweng/joint-metrics-matter}}.
Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods.
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.
Recently many efforts have been devoted to applying graph neural networks (GNNs) to molecular property prediction which is a fundamental task for computational drug and material discovery. One of major obstacles to hinder the successful prediction of molecule property by GNNs is the scarcity of labeled data. Though graph contrastive learning (GCL) methods have achieved extraordinary performance with insufficient labeled data, most focused on designing data augmentation schemes for general graphs. However, the fundamental property of a molecule could be altered with the augmentation method (like random perturbation) on molecular graphs. Whereas, the critical geometric information of molecules remains rarely explored under the current GNN and GCL architectures. To this end, we propose a novel graph contrastive learning method utilizing the geometry of the molecule across 2D and 3D views, which is named GeomGCL. Specifically, we first devise a dual-view geometric message passing network (GeomMPNN) to adaptively leverage the rich information of both 2D and 3D graphs of a molecule. The incorporation of geometric properties at different levels can greatly facilitate the molecular representation learning. Then a novel geometric graph contrastive scheme is designed to make both geometric views collaboratively supervise each other to improve the generalization ability of GeomMPNN. We evaluate GeomGCL on various downstream property prediction tasks via a finetune process. Experimental results on seven real-life molecular datasets demonstrate the effectiveness of our proposed GeomGCL against state-of-the-art baselines.
Learning disentanglement aims at finding a low dimensional representation which consists of multiple explanatory and generative factors of the observational data. The framework of variational autoencoder (VAE) is commonly used to disentangle independent factors from observations. However, in real scenarios, factors with semantics are not necessarily independent. Instead, there might be an underlying causal structure which renders these factors dependent. We thus propose a new VAE based framework named CausalVAE, which includes a Causal Layer to transform independent exogenous factors into causal endogenous ones that correspond to causally related concepts in data. We further analyze the model identifiabitily, showing that the proposed model learned from observations recovers the true one up to a certain degree. Experiments are conducted on various datasets, including synthetic and real word benchmark CelebA. Results show that the causal representations learned by CausalVAE are semantically interpretable, and their causal relationship as a Directed Acyclic Graph (DAG) is identified with good accuracy. Furthermore, we demonstrate that the proposed CausalVAE model is able to generate counterfactual data through "do-operation" to the causal factors.
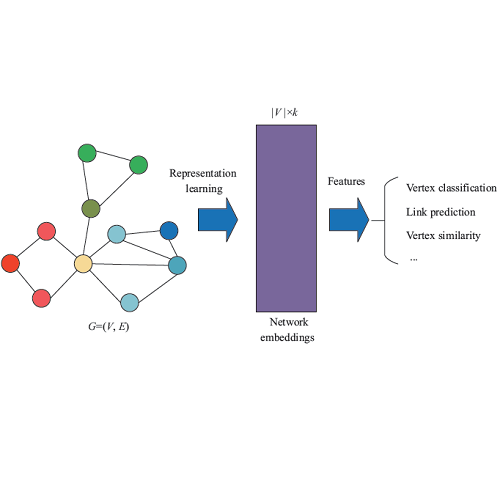
Graph Neural Networks (GNNs) are widely used for analyzing graph-structured data. Most GNN methods are highly sensitive to the quality of graph structures and usually require a perfect graph structure for learning informative embeddings. However, the pervasiveness of noise in graphs necessitates learning robust representations for real-world problems. To improve the robustness of GNN models, many studies have been proposed around the central concept of Graph Structure Learning (GSL), which aims to jointly learn an optimized graph structure and corresponding representations. Towards this end, in the presented survey, we broadly review recent progress of GSL methods for learning robust representations. Specifically, we first formulate a general paradigm of GSL, and then review state-of-the-art methods classified by how they model graph structures, followed by applications that incorporate the idea of GSL in other graph tasks. Finally, we point out some issues in current studies and discuss future directions.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191