


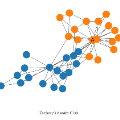
Heterogeneous information networks (HINs) have been extensively applied to real-world tasks, such as recommendation systems, social networks, and citation networks. While existing HIN representation learning methods can effectively learn the semantic and structural features in the network, little awareness was given to the distribution discrepancy of subgraphs within a single HIN. However, we find that ignoring such distribution discrepancy among subgraphs from multiple sources would hinder the effectiveness of graph embedding learning algorithms. This motivates us to propose SUMSHINE (Scalable Unsupervised Multi-Source Heterogeneous Information Network Embedding) -- a scalable unsupervised framework to align the embedding distributions among multiple sources of an HIN. Experimental results on real-world datasets in a variety of downstream tasks validate the performance of our method over the state-of-the-art heterogeneous information network embedding algorithms.
相關內容
《計算機信息》雜志發表高質量的論文,擴大了運籌學和計算的范圍,尋求有關理論、方法、實驗、系統和應用方面的原創研究論文、新穎的調查和教程論文,以及描述新的和有用的軟件工具的論文。官網鏈接: ·
Monte-Carlo Tree Search
·
GNN
·
泛函
·
可約的
·
Graph neural networks (GNNs) are powerful tools for performing data science tasks in various domains. Although we use GNNs in wide application scenarios, it is a laborious task for researchers and practitioners to design/select optimal GNN architectures in diverse graphs. To save human efforts and computational costs, graph neural architecture search (Graph NAS) has been used to search for a sub-optimal GNN architecture that combines existing components. However, there are no existing Graph NAS methods that satisfy explainability, efficiency, and adaptability to various graphs. Therefore, we propose an efficient and explainable Graph NAS method, called ExGNAS, which consists of (i) a simple search space that can adapt to various graphs and (ii) a search algorithm that makes the decision process explainable. The search space includes only fundamental functions that can handle homophilic and heterophilic graphs. The search algorithm efficiently searches for the best GNN architecture via Monte-Carlo tree search without neural models. The combination of our search space and algorithm achieves finding accurate GNN models and the important functions within the search space. We comprehensively evaluate our method compared with twelve hand-crafted GNN architectures and three Graph NAS methods in four graphs. Our experimental results show that ExGNAS increases AUC up to 3.6 and reduces run time up to 78\% compared with the state-of-the-art Graph NAS methods. Furthermore, we show ExGNAS is effective in analyzing the difference between GNN architectures in homophilic and heterophilic graphs.
Offline Reinforcement Learning (RL) is structured to derive policies from static trajectory data without requiring real-time environment interactions. Recent studies have shown the feasibility of framing offline RL as a sequence modeling task, where the sole aim is to predict actions based on prior context using the transformer architecture. However, the limitation of this single task learning approach is its potential to undermine the transformer model's attention mechanism, which should ideally allocate varying attention weights across different tokens in the input context for optimal prediction. To address this, we reformulate offline RL as a multi-objective optimization problem, where the prediction is extended to states and returns. We also highlight a potential flaw in the trajectory representation used for sequence modeling, which could generate inaccuracies when modeling the state and return distributions. This is due to the non-smoothness of the action distribution within the trajectory dictated by the behavioral policy. To mitigate this issue, we introduce action space regions to the trajectory representation. Our experiments on D4RL benchmark locomotion tasks reveal that our propositions allow for more effective utilization of the attention mechanism in the transformer model, resulting in performance that either matches or outperforms current state-of-the art methods.
Data produced by on-chip sensors in modern SoCs contains a large amount of information such as occurring faults, aging status, accumulated radiation dose, performance characteristics, environmental and other operational parameters. Such information provides insight into the overall health of a system's hardware as well as the operability of individual modules. This gives a chance to mitigate faults and avoid using faulty units, thus enabling hardware health management. Raw data from embedded sensors cannot be immediately used to perform health management tasks. In most cases, the information about occurred faults needs to be analyzed taking into account the history of the previously reported fault events and other collected statistics. For this purpose, we propose a special structure called Health Map (HM) that holds the information about functional resources, occurring faults and maps relationships between these. In addition, we propose algorithms for aggregation and classification of data received from on-chip sensors. The proposed Health Map contains detailed information on a particular system level (e.g., module, SoC, board) that can be compiled into a summary of hardware health status that in its turn enables distributed hierarchical health management by using this information at a higher level of system hierarchy, thus increasing the system's availability and effective lifetime.
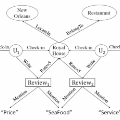
Recommender systems is set up to address the issue of information overload in traditional information retrieval systems, which is focused on recommending information that is of most interest to users from massive information. Generally, there is a sequential nature and heterogeneity to the behavior of a person interacting with a system, leading to the proposal of multi-behavior sequential recommendation (MBSR). MBSR is a relatively new and worthy direction for in-depth research, which can achieve state-of-the-art recommendation through suitable modeling, and some related works have been proposed. This survey aims to shed light on the MBSR problem. Firstly, we introduce MBSR in detail, including its problem definition, application scenarios and challenges faced. Secondly, we detail the classification of MBSR, including neighborhood-based methods, matrix factorization-based methods and deep learning-based methods, where we further classify the deep learning-based methods into different learning architectures based on RNN, GNN, Transformer, and generic architectures as well as architectures that integrate hybrid techniques. In each method, we present related works based on the data perspective and the modeling perspective, as well as analyze the strengths, weaknesses and features of these works. Finally, we discuss some promising future research directions to address the challenges and improve the current status of MBSR.
Deep neural networks (DNNs) have succeeded in many different perception tasks, e.g., computer vision, natural language processing, reinforcement learning, etc. The high-performed DNNs heavily rely on intensive resource consumption. For example, training a DNN requires high dynamic memory, a large-scale dataset, and a large number of computations (a long training time); even inference with a DNN also demands a large amount of static storage, computations (a long inference time), and energy. Therefore, state-of-the-art DNNs are often deployed on a cloud server with a large number of super-computers, a high-bandwidth communication bus, a shared storage infrastructure, and a high power supplement. Recently, some new emerging intelligent applications, e.g., AR/VR, mobile assistants, Internet of Things, require us to deploy DNNs on resource-constrained edge devices. Compare to a cloud server, edge devices often have a rather small amount of resources. To deploy DNNs on edge devices, we need to reduce the size of DNNs, i.e., we target a better trade-off between resource consumption and model accuracy. In this dissertation, we studied four edge intelligence scenarios, i.e., Inference on Edge Devices, Adaptation on Edge Devices, Learning on Edge Devices, and Edge-Server Systems, and developed different methodologies to enable deep learning in each scenario. Since current DNNs are often over-parameterized, our goal is to find and reduce the redundancy of the DNNs in each scenario.
Advances in artificial intelligence often stem from the development of new environments that abstract real-world situations into a form where research can be done conveniently. This paper contributes such an environment based on ideas inspired by elementary Microeconomics. Agents learn to produce resources in a spatially complex world, trade them with one another, and consume those that they prefer. We show that the emergent production, consumption, and pricing behaviors respond to environmental conditions in the directions predicted by supply and demand shifts in Microeconomics. We also demonstrate settings where the agents' emergent prices for goods vary over space, reflecting the local abundance of goods. After the price disparities emerge, some agents then discover a niche of transporting goods between regions with different prevailing prices -- a profitable strategy because they can buy goods where they are cheap and sell them where they are expensive. Finally, in a series of ablation experiments, we investigate how choices in the environmental rewards, bartering actions, agent architecture, and ability to consume tradable goods can either aid or inhibit the emergence of this economic behavior. This work is part of the environment development branch of a research program that aims to build human-like artificial general intelligence through multi-agent interactions in simulated societies. By exploring which environment features are needed for the basic phenomena of elementary microeconomics to emerge automatically from learning, we arrive at an environment that differs from those studied in prior multi-agent reinforcement learning work along several dimensions. For example, the model incorporates heterogeneous tastes and physical abilities, and agents negotiate with one another as a grounded form of communication.
Besides entity-centric knowledge, usually organized as Knowledge Graph (KG), events are also an essential kind of knowledge in the world, which trigger the spring up of event-centric knowledge representation form like Event KG (EKG). It plays an increasingly important role in many machine learning and artificial intelligence applications, such as intelligent search, question-answering, recommendation, and text generation. This paper provides a comprehensive survey of EKG from history, ontology, instance, and application views. Specifically, to characterize EKG thoroughly, we focus on its history, definitions, schema induction, acquisition, related representative graphs/systems, and applications. The development processes and trends are studied therein. We further summarize perspective directions to facilitate future research on EKG.
Graph neural networks (GNNs) is widely used to learn a powerful representation of graph-structured data. Recent work demonstrates that transferring knowledge from self-supervised tasks to downstream tasks could further improve graph representation. However, there is an inherent gap between self-supervised tasks and downstream tasks in terms of optimization objective and training data. Conventional pre-training methods may be not effective enough on knowledge transfer since they do not make any adaptation for downstream tasks. To solve such problems, we propose a new transfer learning paradigm on GNNs which could effectively leverage self-supervised tasks as auxiliary tasks to help the target task. Our methods would adaptively select and combine different auxiliary tasks with the target task in the fine-tuning stage. We design an adaptive auxiliary loss weighting model to learn the weights of auxiliary tasks by quantifying the consistency between auxiliary tasks and the target task. In addition, we learn the weighting model through meta-learning. Our methods can be applied to various transfer learning approaches, it performs well not only in multi-task learning but also in pre-training and fine-tuning. Comprehensive experiments on multiple downstream tasks demonstrate that the proposed methods can effectively combine auxiliary tasks with the target task and significantly improve the performance compared to state-of-the-art methods.
It has been shown that deep neural networks are prone to overfitting on biased training data. Towards addressing this issue, meta-learning employs a meta model for correcting the training bias. Despite the promising performances, super slow training is currently the bottleneck in the meta learning approaches. In this paper, we introduce a novel Faster Meta Update Strategy (FaMUS) to replace the most expensive step in the meta gradient computation with a faster layer-wise approximation. We empirically find that FaMUS yields not only a reasonably accurate but also a low-variance approximation of the meta gradient. We conduct extensive experiments to verify the proposed method on two tasks. We show our method is able to save two-thirds of the training time while still maintaining the comparable or achieving even better generalization performance. In particular, our method achieves the state-of-the-art performance on both synthetic and realistic noisy labels, and obtains promising performance on long-tailed recognition on standard benchmarks.
Knowledge graph embedding, which aims to represent entities and relations as low dimensional vectors (or matrices, tensors, etc.), has been shown to be a powerful technique for predicting missing links in knowledge graphs. Existing knowledge graph embedding models mainly focus on modeling relation patterns such as symmetry/antisymmetry, inversion, and composition. However, many existing approaches fail to model semantic hierarchies, which are common in real-world applications. To address this challenge, we propose a novel knowledge graph embedding model---namely, Hierarchy-Aware Knowledge Graph Embedding (HAKE)---which maps entities into the polar coordinate system. HAKE is inspired by the fact that concentric circles in the polar coordinate system can naturally reflect the hierarchy. Specifically, the radial coordinate aims to model entities at different levels of the hierarchy, and entities with smaller radii are expected to be at higher levels; the angular coordinate aims to distinguish entities at the same level of the hierarchy, and these entities are expected to have roughly the same radii but different angles. Experiments demonstrate that HAKE can effectively model the semantic hierarchies in knowledge graphs, and significantly outperforms existing state-of-the-art methods on benchmark datasets for the link prediction task.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191