

Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at //github.com/Fanghua-Yu/OSRT.
相關內容
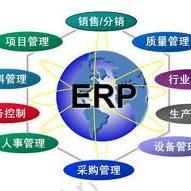
ERP 是(shi) Enterprise Resource Planning(企(qi)業(ye)資(zi)(zi)源計劃(hua))的簡稱。
ERP是(shi)針對(dui)物(wu)(wu)資(zi)(zi)資(zi)(zi)源管(guan)理(li)(li)(li)(li)(物(wu)(wu)流)、人(ren)力資(zi)(zi)源管(guan)理(li)(li)(li)(li)(人(ren)才流)、財(cai)務(wu)資(zi)(zi)源管(guan)理(li)(li)(li)(li)(財(cai)流)、信息資(zi)(zi)源管(guan)理(li)(li)(li)(li)(信息流)集(ji)成一體化的企(qi)業(ye)管(guan)理(li)(li)(li)(li)系(xi)統。
Featured by a bottleneck structure, autoencoder (AE) and its variants have been largely applied in various medical image analysis tasks, such as segmentation, reconstruction and de-noising. Despite of their promising performances in aforementioned tasks, in this paper, we claim that AE models are not applicable to single image super-resolution (SISR) for 3D CT data. Our hypothesis is that the bottleneck architecture that resizes feature maps in AE models degrades the details of input images, thus can sabotage the performance of super-resolution. Although U-Net proposed skip connections that merge information from different levels, we claim that the degrading impact of feature resizing operations could hardly be removed by skip connections. By conducting large-scale ablation experiments and comparing the performance between models with and without the bottleneck design on a public CT lung dataset , we have discovered that AE models, including U-Net, have failed to achieve a compatible SISR result ($p<0.05$ by Student's t-test) compared to the baseline model. Our work is the first comparative study investigating the suitability of AE architecture for 3D CT SISR tasks and brings a rationale for researchers to re-think the choice of model architectures especially for 3D CT SISR tasks. The full implementation and trained models can be found at: //github.com/Roldbach/Autoencoder-3D-CT-SISR
Imputation of missing images via source-to-target modality translation can improve diversity in medical imaging protocols. A pervasive approach for synthesizing target images involves one-shot mapping through generative adversarial networks (GAN). Yet, GAN models that implicitly characterize the image distribution can suffer from limited sample fidelity. Here, we propose a novel method based on adversarial diffusion modeling, SynDiff, for improved performance in medical image translation. To capture a direct correlate of the image distribution, SynDiff leverages a conditional diffusion process that progressively maps noise and source images onto the target image. For fast and accurate image sampling during inference, large diffusion steps are taken with adversarial projections in the reverse diffusion direction. To enable training on unpaired datasets, a cycle-consistent architecture is devised with coupled diffusive and non-diffusive modules that bilaterally translate between two modalities. Extensive assessments are reported on the utility of SynDiff against competing GAN and diffusion models in multi-contrast MRI and MRI-CT translation. Our demonstrations indicate that SynDiff offers quantitatively and qualitatively superior performance against competing baselines.
Medical image segmentation is considered as the basic step for medical image analysis and surgical intervention. And many previous works attempted to incorporate shape priors for designing segmentation models, which is beneficial to attain finer masks with anatomical shape information. Here in our work, we detailedly discuss three types of segmentation models with shape priors, which consist of atlas-based models, statistical-based models and UNet-based models. On the ground that the former two kinds of methods show a poor generalization ability, UNet-based models have dominated the field of medical image segmentation in recent years. However, existing UNet-based models tend to employ implicit shape priors, which do not have a good interpretability and generalization ability on different organs with distinctive shapes. Thus, we proposed a novel shape prior module (SPM), which could explicitly introduce shape priors to promote the segmentation performance of UNet-based models. To evaluate the effectiveness of SPM, we conduct experiments on three challenging public datasets. And our proposed model achieves state-of-the-art performance. Furthermore, SPM shows an outstanding generalization ability on different classic convolution-neural-networks (CNNs) and recent Transformer-based backbones, which can serve as a plug-and-play structure for the segmentation task of different datasets.
Recent studies show that models trained by continual learning can achieve the comparable performances as the standard supervised learning and the learning flexibility of continual learning models enables their wide applications in the real world. Deep learning models, however, are shown to be vulnerable to adversarial attacks. Though there are many studies on the model robustness in the context of standard supervised learning, protecting continual learning from adversarial attacks has not yet been investigated. To fill in this research gap, we are the first to study adversarial robustness in continual learning and propose a novel method called \textbf{T}ask-\textbf{A}ware \textbf{B}oundary \textbf{A}ugmentation (TABA) to boost the robustness of continual learning models. With extensive experiments on CIFAR-10 and CIFAR-100, we show the efficacy of adversarial training and TABA in defending adversarial attacks.
We describe ACE0, a lightweight platform for evaluating the suitability and viability of AI methods for behaviour discovery in multiagent simulations. Specifically, ACE0 was designed to explore AI methods for multi-agent simulations used in operations research studies related to new technologies such as autonomous aircraft. Simulation environments used in production are often high-fidelity, complex, require significant domain knowledge and as a result have high R&D costs. Minimal and lightweight simulation environments can help researchers and engineers evaluate the viability of new AI technologies for behaviour discovery in a more agile and potentially cost effective manner. In this paper we describe the motivation for the development of ACE0.We provide a technical overview of the system architecture, describe a case study of behaviour discovery in the aerospace domain, and provide a qualitative evaluation of the system. The evaluation includes a brief description of collaborative research projects with academic partners, exploring different AI behaviour discovery methods.
Hashing has been widely used in approximate nearest search for large-scale database retrieval for its computation and storage efficiency. Deep hashing, which devises convolutional neural network architecture to exploit and extract the semantic information or feature of images, has received increasing attention recently. In this survey, several deep supervised hashing methods for image retrieval are evaluated and I conclude three main different directions for deep supervised hashing methods. Several comments are made at the end. Moreover, to break through the bottleneck of the existing hashing methods, I propose a Shadow Recurrent Hashing(SRH) method as a try. Specifically, I devise a CNN architecture to extract the semantic features of images and design a loss function to encourage similar images projected close. To this end, I propose a concept: shadow of the CNN output. During optimization process, the CNN output and its shadow are guiding each other so as to achieve the optimal solution as much as possible. Several experiments on dataset CIFAR-10 show the satisfying performance of SRH.
Convolutional neural networks (CNNs) have shown dramatic improvements in single image super-resolution (SISR) by using large-scale external samples. Despite their remarkable performance based on the external dataset, they cannot exploit internal information within a specific image. Another problem is that they are applicable only to the specific condition of data that they are supervised. For instance, the low-resolution (LR) image should be a "bicubic" downsampled noise-free image from a high-resolution (HR) one. To address both issues, zero-shot super-resolution (ZSSR) has been proposed for flexible internal learning. However, they require thousands of gradient updates, i.e., long inference time. In this paper, we present Meta-Transfer Learning for Zero-Shot Super-Resolution (MZSR), which leverages ZSSR. Precisely, it is based on finding a generic initial parameter that is suitable for internal learning. Thus, we can exploit both external and internal information, where one single gradient update can yield quite considerable results. (See Figure 1). With our method, the network can quickly adapt to a given image condition. In this respect, our method can be applied to a large spectrum of image conditions within a fast adaptation process.
We consider the problem of referring image segmentation. Given an input image and a natural language expression, the goal is to segment the object referred by the language expression in the image. Existing works in this area treat the language expression and the input image separately in their representations. They do not sufficiently capture long-range correlations between these two modalities. In this paper, we propose a cross-modal self-attention (CMSA) module that effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the input image. In addition, we propose a gated multi-level fusion module to selectively integrate self-attentive cross-modal features corresponding to different levels in the image. This module controls the information flow of features at different levels. We validate the proposed approach on four evaluation datasets. Our proposed approach consistently outperforms existing state-of-the-art methods.
Multivariate time series forecasting is extensively studied throughout the years with ubiquitous applications in areas such as finance, traffic, environment, etc. Still, concerns have been raised on traditional methods for incapable of modeling complex patterns or dependencies lying in real word data. To address such concerns, various deep learning models, mainly Recurrent Neural Network (RNN) based methods, are proposed. Nevertheless, capturing extremely long-term patterns while effectively incorporating information from other variables remains a challenge for time-series forecasting. Furthermore, lack-of-explainability remains one serious drawback for deep neural network models. Inspired by Memory Network proposed for solving the question-answering task, we propose a deep learning based model named Memory Time-series network (MTNet) for time series forecasting. MTNet consists of a large memory component, three separate encoders, and an autoregressive component to train jointly. Additionally, the attention mechanism designed enable MTNet to be highly interpretable. We can easily tell which part of the historic data is referenced the most.
Recurrent neural nets (RNN) and convolutional neural nets (CNN) are widely used on NLP tasks to capture the long-term and local dependencies, respectively. Attention mechanisms have recently attracted enormous interest due to their highly parallelizable computation, significantly less training time, and flexibility in modeling dependencies. We propose a novel attention mechanism in which the attention between elements from input sequence(s) is directional and multi-dimensional (i.e., feature-wise). A light-weight neural net, "Directional Self-Attention Network (DiSAN)", is then proposed to learn sentence embedding, based solely on the proposed attention without any RNN/CNN structure. DiSAN is only composed of a directional self-attention with temporal order encoded, followed by a multi-dimensional attention that compresses the sequence into a vector representation. Despite its simple form, DiSAN outperforms complicated RNN models on both prediction quality and time efficiency. It achieves the best test accuracy among all sentence encoding methods and improves the most recent best result by 1.02% on the Stanford Natural Language Inference (SNLI) dataset, and shows state-of-the-art test accuracy on the Stanford Sentiment Treebank (SST), Multi-Genre natural language inference (MultiNLI), Sentences Involving Compositional Knowledge (SICK), Customer Review, MPQA, TREC question-type classification and Subjectivity (SUBJ) datasets.
小貼士
登錄享



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191