

There has been appreciable progress in unsupervised network representation learning (UNRL) approaches over graphs recently with flexible random-walk approaches, new optimization objectives and deep architectures. However, there is no common ground for systematic comparison of embeddings to understand their behavior for different graphs and tasks. In this paper we theoretically group different approaches under a unifying framework and empirically investigate the effectiveness of different network representation methods. In particular, we argue that most of the UNRL approaches either explicitly or implicit model and exploit context information of a node. Consequently, we propose a framework that casts a variety of approaches -- random walk based, matrix factorization and deep learning based -- into a unified context-based optimization function. We systematically group the methods based on their similarities and differences. We study the differences among these methods in detail which we later use to explain their performance differences (on downstream tasks). We conduct a large-scale empirical study considering 9 popular and recent UNRL techniques and 11 real-world datasets with varying structural properties and two common tasks -- node classification and link prediction. We find that there is no single method that is a clear winner and that the choice of a suitable method is dictated by certain properties of the embedding methods, task and structural properties of the underlying graph. In addition we also report the common pitfalls in evaluation of UNRL methods and come up with suggestions for experimental design and interpretation of results.
相關內容
基(ji)于網(wang)(wang)絡(luo)的(de)(de)(de)表示學習研(yan)(yan)究(jiu)(jiu)旨在探索能夠更好(hao)地研(yan)(yan)究(jiu)(jiu)分析復雜信(xin)(xin)息網(wang)(wang)絡(luo)中(zhong)的(de)(de)(de)節(jie)點(dian)(dian)間(jian)的(de)(de)(de)聯系, 尋找解決信(xin)(xin)息網(wang)(wang)絡(luo)背景下(xia)的(de)(de)(de)各種實(shi)際問(wen)題的(de)(de)(de)普(pu)適(shi)方(fang)法(fa), 有效融合網(wang)(wang)絡(luo)結(jie)構與節(jie)點(dian)(dian)外部信(xin)(xin)息, 形成更具區(qu)分性(xing)的(de)(de)(de)網(wang)(wang)絡(luo)表示. 近(jin)年來(lai), 網(wang)(wang)絡(luo)表示學習問(wen)題吸引了大量的(de)(de)(de)研(yan)(yan)究(jiu)(jiu)者的(de)(de)(de)目(mu)光, 相關的(de)(de)(de)論文工(gong)作(zuo)也層出不窮(qiong)。
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
We present a new method to learn video representations from large-scale unlabeled video data. Ideally, this representation will be generic and transferable, directly usable for new tasks such as action recognition and zero or few-shot learning. We formulate unsupervised representation learning as a multi-modal, multi-task learning problem, where the representations are shared across different modalities via distillation. Further, we introduce the concept of loss function evolution by using an evolutionary search algorithm to automatically find optimal combination of loss functions capturing many (self-supervised) tasks and modalities. Thirdly, we propose an unsupervised representation evaluation metric using distribution matching to a large unlabeled dataset as a prior constraint, based on Zipf's law. This unsupervised constraint, which is not guided by any labeling, produces similar results to weakly-supervised, task-specific ones. The proposed unsupervised representation learning results in a single RGB network and outperforms previous methods. Notably, it is also more effective than several label-based methods (e.g., ImageNet), with the exception of large, fully labeled video datasets.
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
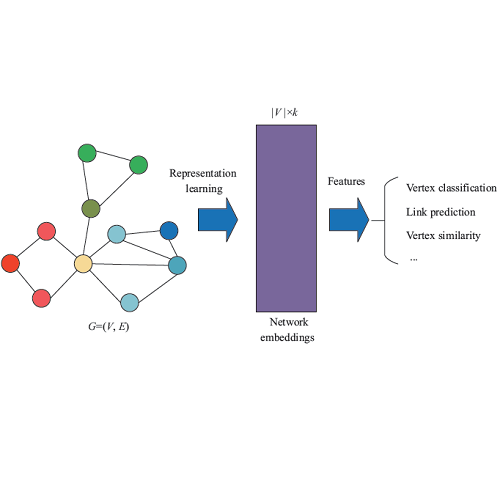
Mining graph data has become a popular research topic in computer science and has been widely studied in both academia and industry given the increasing amount of network data in the recent years. However, the huge amount of network data has posed great challenges for efficient analysis. This motivates the advent of graph representation which maps the graph into a low-dimension vector space, keeping original graph structure and supporting graph inference. The investigation on efficient representation of a graph has profound theoretical significance and important realistic meaning, we therefore introduce some basic ideas in graph representation/network embedding as well as some representative models in this chapter.
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
This work tackles the problem of semi-supervised learning of image classifiers. Our main insight is that the field of semi-supervised learning can benefit from the quickly advancing field of self-supervised visual representation learning. Unifying these two approaches, we propose the framework of self-supervised semi-supervised learning ($S^4L$) and use it to derive two novel semi-supervised image classification methods. We demonstrate the effectiveness of these methods in comparison to both carefully tuned baselines, and existing semi-supervised learning methods. We then show that $S^4L$ and existing semi-supervised methods can be jointly trained, yielding a new state-of-the-art result on semi-supervised ILSVRC-2012 with 10% of labels.
There has been appreciable progress in unsupervised network representation learning (UNRL) approaches over graphs recently with flexible random-walk approaches, new optimization objectives and deep architectures. However, there is no common ground for systematic comparison of embeddings to understand their behavior for different graphs and tasks. In this paper we theoretically group different approaches under a unifying framework and empirically investigate the effectiveness of different network representation methods. In particular, we argue that most of the UNRL approaches either explicitly or implicit model and exploit context information of a node. Consequently, we propose a framework that casts a variety of approaches -- random walk based, matrix factorization and deep learning based -- into a unified context-based optimization function. We systematically group the methods based on their similarities and differences. We study the differences among these methods in detail which we later use to explain their performance differences (on downstream tasks). We conduct a large-scale empirical study considering 9 popular and recent UNRL techniques and 11 real-world datasets with varying structural properties and two common tasks -- node classification and link prediction. We find that there is no single method that is a clear winner and that the choice of a suitable method is dictated by certain properties of the embedding methods, task and structural properties of the underlying graph. In addition we also report the common pitfalls in evaluation of UNRL methods and come up with suggestions for experimental design and interpretation of results.
Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at //pathak22.github.io/large-scale-curiosity/
Recently, graph neural networks (GNNs) have revolutionized the field of graph representation learning through effectively learned node embeddings, and achieved state-of-the-art results in tasks such as node classification and link prediction. However, current GNN methods are inherently flat and do not learn hierarchical representations of graphs---a limitation that is especially problematic for the task of graph classification, where the goal is to predict the label associated with an entire graph. Here we propose DiffPool, a differentiable graph pooling module that can generate hierarchical representations of graphs and can be combined with various graph neural network architectures in an end-to-end fashion. DiffPool learns a differentiable soft cluster assignment for nodes at each layer of a deep GNN, mapping nodes to a set of clusters, which then form the coarsened input for the next GNN layer. Our experimental results show that combining existing GNN methods with DiffPool yields an average improvement of 5-10% accuracy on graph classification benchmarks, compared to all existing pooling approaches, achieving a new state-of-the-art on four out of five benchmark data sets.
A major goal of unsupervised learning is to discover data representations that are useful for subsequent tasks, without access to supervised labels during training. Typically, this goal is approached by minimizing a surrogate objective, such as the negative log likelihood of a generative model, with the hope that representations useful for subsequent tasks will arise incidentally. In this work, we propose instead to directly target a later desired task by meta-learning an unsupervised learning rule, which leads to representations useful for that task. Here, our desired task (meta-objective) is the performance of the representation on semi-supervised classification, and we meta-learn an algorithm -- an unsupervised weight update rule -- that produces representations that perform well under this meta-objective. Additionally, we constrain our unsupervised update rule to a be a biologically-motivated, neuron-local function, which enables it to generalize to novel neural network architectures. We show that the meta-learned update rule produces useful features and sometimes outperforms existing unsupervised learning techniques. We further show that the meta-learned unsupervised update rule generalizes to train networks with different widths, depths, and nonlinearities. It also generalizes to train on data with randomly permuted input dimensions and even generalizes from image datasets to a text task.
小貼士
登錄享
相關主題




注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191