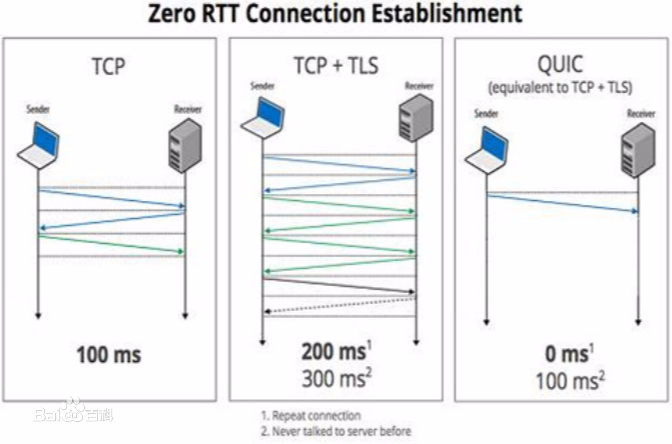

Built on top of UDP, the relatively new QUIC protocol serves as the baseline for modern web protocol stacks. Equipped with a rich feature set, the protocol is defined by a 151 pages strong IETF standard complemented by several additional documents. Enabling fast updates and feature iteration, most QUIC implementations are implemented as user space libraries leading to a large and fragmented ecosystem. This work addresses the research question, "if a complex standard with a large number of different implementations leads to an insecure ecosystem?". The relevant RFC documents were studied and "Security Consideration" items describing conceptional problems were extracted. During the research, 13 popular production ready QUIC implementations were compared by evaluating 10 security considerations from RFC9000. While related studies mostly focused on the functional part of QUIC, this study confirms that available QUIC implementations are not yet mature enough from a security point of view.
相關內容
Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at //github.com/williamliujl/LLMRec.
Existing visual tracking methods typically take an image patch as the reference of the target to perform tracking. However, a single image patch cannot provide a complete and precise concept of the target object as images are limited in their ability to abstract and can be ambiguous, which makes it difficult to track targets with drastic variations. In this paper, we propose the CiteTracker to enhance target modeling and inference in visual tracking by connecting images and text. Specifically, we develop a text generation module to convert the target image patch into a descriptive text containing its class and attribute information, providing a comprehensive reference point for the target. In addition, a dynamic description module is designed to adapt to target variations for more effective target representation. We then associate the target description and the search image using an attention-based correlation module to generate the correlated features for target state reference. Extensive experiments on five diverse datasets are conducted to evaluate the proposed algorithm and the favorable performance against the state-of-the-art methods demonstrates the effectiveness of the proposed tracking method.
Concept Evolution in Deep Learning Training: A Unified Interpretation Framework and Discoveries
We present ConceptEvo, a unified interpretation framework for deep neural networks (DNNs) that reveals the inception and evolution of learned concepts during training. Our work addresses a critical gap in DNN interpretation research, as existing methods primarily focus on post-training interpretation. ConceptEvo introduces two novel technical contributions: (1) an algorithm that generates a unified semantic space, enabling side-by-side comparison of different models during training, and (2) an algorithm that discovers and quantifies important concept evolutions for class predictions. Through a large-scale human evaluation and quantitative experiments, we demonstrate that ConceptEvo successfully identifies concept evolutions across different models, which are not only comprehensible to humans but also crucial for class predictions. ConceptEvo is applicable to both modern DNN architectures, such as ConvNeXt, and classic DNNs, such as VGGs and InceptionV3.
Sequential recommenders have made great strides in capturing a user's preferences. Nevertheless, the cold-start recommendation remains a fundamental challenge as they typically involve limited user-item interactions for personalization. Recently, gradient-based meta-learning approaches have emerged in the sequential recommendation field due to their fast adaptation and easy-to-integrate abilities. The meta-learning algorithms formulate the cold-start recommendation as a few-shot learning problem, where each user is represented as a task to be adapted. While meta-learning algorithms generally assume that task-wise samples are evenly distributed over classes or values, user-item interactions in real-world applications do not conform to such a distribution (e.g., watching favorite videos multiple times, leaving only positive ratings without any negative ones). Consequently, imbalanced user feedback, which accounts for the majority of task training data, may dominate the user adaptation process and prevent meta-learning algorithms from learning meaningful meta-knowledge for personalized recommendations. To alleviate this limitation, we propose a novel sequential recommendation framework based on gradient-based meta-learning that captures the imbalanced rating distribution of each user and computes adaptive loss for user-specific learning. Our work is the first to tackle the impact of imbalanced ratings in cold-start sequential recommendation scenarios. Through extensive experiments conducted on real-world datasets, we demonstrate the effectiveness of our framework.
Natural language understanding (NLU) is integral to various social media applications. However, existing NLU models rely heavily on context for semantic learning, resulting in compromised performance when faced with short and noisy social media content. To address this issue, we leverage in-context learning (ICL), wherein language models learn to make inferences by conditioning on a handful of demonstrations to enrich the context and propose a novel hashtag-driven in-context learning (HICL) framework. Concretely, we pre-train a model #Encoder, which employs #hashtags (user-annotated topic labels) to drive BERT-based pre-training through contrastive learning. Our objective here is to enable #Encoder to gain the ability to incorporate topic-related semantic information, which allows it to retrieve topic-related posts to enrich contexts and enhance social media NLU with noisy contexts. To further integrate the retrieved context with the source text, we employ a gradient-based method to identify trigger terms useful in fusing information from both sources. For empirical studies, we collected 45M tweets to set up an in-context NLU benchmark, and the experimental results on seven downstream tasks show that HICL substantially advances the previous state-of-the-art results. Furthermore, we conducted extensive analyzes and found that: (1) combining source input with a top-retrieved post from #Encoder is more effective than using semantically similar posts; (2) trigger words can largely benefit in merging context from the source and retrieved posts.
Although Neural Radiance Fields (NeRF) is popular in the computer vision community recently, registering multiple NeRFs has yet to gain much attention. Unlike the existing work, NeRF2NeRF, which is based on traditional optimization methods and needs human annotated keypoints, we propose DReg-NeRF to solve the NeRF registration problem on object-centric scenes without human intervention. After training NeRF models, our DReg-NeRF first extracts features from the occupancy grid in NeRF. Subsequently, our DReg-NeRF utilizes a transformer architecture with self-attention and cross-attention layers to learn the relations between pairwise NeRF blocks. In contrast to state-of-the-art (SOTA) point cloud registration methods, the decoupled correspondences are supervised by surface fields without any ground truth overlapping labels. We construct a novel view synthesis dataset with 1,700+ 3D objects obtained from Objaverse to train our network. When evaluated on the test set, our proposed method beats the SOTA point cloud registration methods by a large margin, with a mean $\text{RPE}=9.67^{\circ}$ and a mean $\text{RTE}=0.038$. Our code is available at //github.com/AIBluefisher/DReg-NeRF.
Shuffle is one of the most expensive communication primitives in distributed data processing and is difficult to scale. Prior work addresses the scalability challenges of shuffle by building monolithic shuffle systems. These systems are costly to develop, and they are tightly integrated with batch processing frameworks that offer only high-level APIs such as SQL. New applications, such as ML training, require more flexibility and finer-grained interoperability with shuffle. They are often unable to leverage existing shuffle optimizations. We propose an extensible shuffle architecture. We present Exoshuffle, a library for distributed shuffle that offers competitive performance and scalability as well as greater flexibility than monolithic shuffle systems. We design an architecture that decouples the shuffle control plane from the data plane without sacrificing performance. We build Exoshuffle on Ray, a distributed futures system for data and ML applications, and demonstrate that we can: (1) rewrite previous shuffle optimizations as application-level libraries with an order of magnitude less code, (2) achieve shuffle performance and scalability competitive with monolithic shuffle systems, and break the CloudSort record as the world's most cost-efficient sorting system, and (3) enable new applications such as ML training to easily leverage scalable shuffle.
ModSecurity is widely recognized as the standard open-source Web Application Firewall (WAF), maintained by the OWASP Foundation. It detects malicious requests by matching them against the Core Rule Set, identifying well-known attack patterns. Each rule in the CRS is manually assigned a weight, based on the severity of the corresponding attack, and a request is detected as malicious if the sum of the weights of the firing rules exceeds a given threshold. In this work, we show that this simple strategy is largely ineffective for detecting SQL injection (SQLi) attacks, as it tends to block many legitimate requests, while also being vulnerable to adversarial SQLi attacks, i.e., attacks intentionally manipulated to evade detection. To overcome these issues, we design a robust machine learning model, named AdvModSec, which uses the CRS rules as input features, and it is trained to detect adversarial SQLi attacks. Our experiments show that AdvModSec, being trained on the traffic directed towards the protected web services, achieves a better trade-off between detection and false positive rates, improving the detection rate of the vanilla version of ModSecurity with CRS by 21%. Moreover, our approach is able to improve its adversarial robustness against adversarial SQLi attacks by 42%, thereby taking a step forward towards building more robust and trustworthy WAFs.
Sequential recommendation (SR) is to accurately recommend a list of items for a user based on her current accessed ones. While new-coming users continuously arrive in the real world, one crucial task is to have inductive SR that can produce embeddings of users and items without re-training. Given user-item interactions can be extremely sparse, another critical task is to have transferable SR that can transfer the knowledge derived from one domain with rich data to another domain. In this work, we aim to present the holistic SR that simultaneously accommodates conventional, inductive, and transferable settings. We propose a novel deep learning-based model, Relational Temporal Attentive Graph Neural Networks (RetaGNN), for holistic SR. The main idea of RetaGNN is three-fold. First, to have inductive and transferable capabilities, we train a relational attentive GNN on the local subgraph extracted from a user-item pair, in which the learnable weight matrices are on various relations among users, items, and attributes, rather than nodes or edges. Second, long-term and short-term temporal patterns of user preferences are encoded by a proposed sequential self-attention mechanism. Third, a relation-aware regularization term is devised for better training of RetaGNN. Experiments conducted on MovieLens, Instagram, and Book-Crossing datasets exhibit that RetaGNN can outperform state-of-the-art methods under conventional, inductive, and transferable settings. The derived attention weights also bring model explainability.

The problem of Multiple Object Tracking (MOT) consists in following the trajectory of different objects in a sequence, usually a video. In recent years, with the rise of Deep Learning, the algorithms that provide a solution to this problem have benefited from the representational power of deep models. This paper provides a comprehensive survey on works that employ Deep Learning models to solve the task of MOT on single-camera videos. Four main steps in MOT algorithms are identified, and an in-depth review of how Deep Learning was employed in each one of these stages is presented. A complete experimental comparison of the presented works on the three MOTChallenge datasets is also provided, identifying a number of similarities among the top-performing methods and presenting some possible future research directions.



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191