

In this paper, we give a spectral approximation result for the Laplacian on submanifolds of Euclidean spaces with singularities by the $\epsilon$-neighborhood graph constructed from random points on the submanifold. Our convergence rate for the eigenvalue of the Laplacian is $O\left(\left(\log n/n\right)^{1/(m+2)}\right)$, where $m$ and $n$ denote the dimension of the manifold and the sample size, respectively.
相關內容
Path-following algorithms are frequently used in composite optimization problems where a series of subproblems, with varying regularization hyperparameters, are solved sequentially. By reusing the previous solutions as initialization, better convergence speeds have been observed numerically. This makes it a rather useful heuristic to speed up the execution of optimization algorithms in machine learning. We present a primal dual analysis of the path-following algorithm and explore how to design its hyperparameters as well as determining how accurately each subproblem should be solved to guarantee a linear convergence rate on a target problem. Furthermore, considering optimization with a sparsity-inducing penalty, we analyze the change of the active sets with respect to the regularization parameter. The latter can then be adaptively calibrated to finely determine the number of features that will be selected along the solution path. This leads to simple heuristics for calibrating hyperparameters of active set approaches to reduce their complexity and improve their execution time.
In this paper, we study linear forms $\lambda = \beta_1{\mathrm{e}}^{\alpha_1}+\cdots+\beta_m{\mathrm{e}}^{\alpha_m}$, where $\alpha_i$ and $\beta_i$ are algebraic numbers. An explicit lower bound for $|\lambda|$ is proved, which is derived from "th\'eor\`eme de Lindemann--Weierstrass effectif" via constructive methods in algebraic computation. Besides, an explicit upper bound for the minimal $|\lambda|$ is established on systematic results of counting algebraic numbers.
We investigate the complexity of computing the Zariski closure of a finitely generated group of matrices. The Zariski closure was previously shown to be computable by Derksen, Jeandel, and Koiran, but the termination argument for their algorithm appears not to yield any complexity bound. In this paper we follow a different approach and obtain a bound on the degree of the polynomials that define the closure. Our bound shows that the closure can be computed in elementary time. We also obtain upper bounds on the length of chains of linear algebraic groups, where all the groups are generated over a fixed number field.
Performing exact Bayesian inference for complex models is computationally intractable. Markov chain Monte Carlo (MCMC) algorithms can provide reliable approximations of the posterior distribution but are expensive for large datasets and high-dimensional models. A standard approach to mitigate this complexity consists in using subsampling techniques or distributing the data across a cluster. However, these approaches are typically unreliable in high-dimensional scenarios. We focus here on a recent alternative class of MCMC schemes exploiting a splitting strategy akin to the one used by the celebrated alternating direction of multipliers (ADMM) optimization algorithm. These methods appear to provide empirically state-of-the-art performance but their theoretical behavior in high dimension is currently unknown. In this paper, we propose a detailed theoretical study of one of these algorithms known as the split Gibbs sampler. Under regularity conditions, we establish explicit convergence rates for this scheme using Ricci curvature and coupling ideas. We support our theory with numerical illustrations.
A solution manifold is the collection of points in a $d$-dimensional space satisfying a system of $s$ equations with $s<d$. Solution manifolds occur in several statistical problems including hypothesis testing, curved-exponential families, constrained mixture models, partial identifications, and nonparametric set estimation. We analyze solution manifolds both theoretically and algorithmically. In terms of theory, we derive five useful results: the smoothness theorem, the stability theorem (which implies the consistency of a plug-in estimator), the convergence of a gradient flow, the local center manifold theorem and the convergence of the gradient descent algorithm. To numerically approximate a solution manifold, we propose a Monte Carlo gradient descent algorithm. In the case of likelihood inference, we design a manifold constraint maximization procedure to find the maximum likelihood estimator on the manifold. We also develop a method to approximate a posterior distribution defined on a solution manifold.
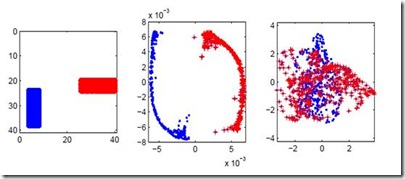
When analyzing parametric statistical models, a useful approach consists in modeling geometrically the parameter space. However, even for very simple and commonly used hierarchical models like statistical mixtures or stochastic deep neural networks, the smoothness assumption of manifolds is violated at singular points which exhibit non-smooth neighborhoods in the parameter space. These singular models have been analyzed in the context of learning dynamics, where singularities can act as attractors on the learning trajectory and, therefore, negatively influence the convergence speed of models. We propose a general approach to circumvent the problem arising from singularities by using stratifolds, a concept from algebraic topology, to formally model singular parameter spaces. We use the property that specific stratifolds are equipped with a resolution method to construct a smooth manifold approximation of the singular space. We empirically show that using (natural) gradient descent on the smooth manifold approximation instead of the singular space allows us to avoid the attractor behavior and therefore improve the convergence speed in learning.
When the regression function belongs to the standard smooth classes consisting of univariate functions with derivatives up to the $(\gamma+1)$th order bounded by a common constant everywhere or a.e., it is well known that the minimax optimal rate of convergence in mean squared error (MSE) is $\left(\frac{\sigma^{2}}{n}\right)^{\frac{2\gamma+2}{2\gamma+3}}$ when $\gamma$ is finite and the sample size $n\rightarrow\infty$. From a nonasymptotic viewpoint that considers finite $n$, this paper shows that: for the standard H\"older and Sobolev classes, the minimax optimal rate is $\frac{\sigma^{2}\left(\gamma\vee1\right)}{n}$ when $\frac{n}{\sigma^{2}}\precsim\left(\gamma\vee1\right)^{2\gamma+3}$ and $\left(\frac{\sigma^{2}}{n}\right)^{\frac{2\gamma+2}{2\gamma+3}}$ when $\frac{n}{\sigma^{2}}\succsim\left(\gamma\vee1\right)^{2\gamma+3}$. To establish these results, we derive upper and lower bounds on the covering and packing numbers for the generalized H\"older class where the $k$th ($k=0,...,\gamma$) derivative is bounded from above by a parameter $R_{k}$ and the $\gamma$th derivative is $R_{\gamma+1}-$Lipschitz (and also for the generalized ellipsoid class of smooth functions). Our bounds sharpen the classical metric entropy results for the standard classes, and give the general dependence on $\gamma$ and $R_{k}$. By deriving the minimax optimal MSE rates under $R_{k}=1$, $R_{k}\leq\left(k-1\right)!$ and $R_{k}=k!$ (with the latter two cases motivated in our introduction) with the help of our new entropy bounds, we show a couple of interesting results that cannot be shown with the existing entropy bounds in the literature. For the H\"older class of $d-$variate functions, our result suggests that the classical asymptotic rate $\left(\frac{\sigma^{2}}{n}\right)^{\frac{2\gamma+2}{2\gamma+2+d}}$ could be an underestimate of the MSE in finite samples.
We analyze the problem of simultaneous support recovery and estimation of the coefficient vector ($\beta^*$) in a linear model with independent and identically distributed Normal errors. We apply the penalized least square estimator based on non-linear penalties of stochastic gates (STG) [YLNK20] to estimate the coefficients. Considering Gaussian design matrices we show that under reasonable conditions on dimension and sparsity of $\beta^*$ the STG based estimator converges to the true data generating coefficient vector and also detects its support set with high probability. We propose a new projection based algorithm for linear models setup to improve upon the existing STG estimator that was originally designed for general non-linear models. Our new procedure outperforms many classical estimators for support recovery in synthetic data analysis.
Neural field models are nonlinear integro-differential equations for the evolution of neuronal activity, and they are a prototypical large-scale, coarse-grained neuronal model in continuum cortices. Neural fields are often simulated heuristically and, in spite of their popularity in mathematical neuroscience, their numerical analysis is not yet fully established. We introduce generic projection methods for neural fields, and derive a-priori error bounds for these schemes. We extend an existing framework for stationary integral equations to the time-dependent case, which is relevant for neuroscience applications. We find that the convergence rate of a projection scheme for a neural field is determined to a great extent by the convergence rate of the projection operator. This abstract analysis, which unifies the treatment of collocation and Galerkin schemes, is carried out in operator form, without resorting to quadrature rules for the integral term, which are introduced only at a later stage, and whose choice is enslaved by the choice of the projector. Using an elementary timestepper as an example, we demonstrate that the error in a time stepper has two separate contributions: one from the projector, and one from the time discretisation. We give examples of concrete projection methods: two collocation schemes (piecewise-linear and spectral collocation) and two Galerkin schemes (finite elements and spectral Galerkin); for each of them we derive error bounds from the general theory, introduce several discrete variants, provide implementation details, and present reproducible convergence tests.
Sampling methods (e.g., node-wise, layer-wise, or subgraph) has become an indispensable strategy to speed up training large-scale Graph Neural Networks (GNNs). However, existing sampling methods are mostly based on the graph structural information and ignore the dynamicity of optimization, which leads to high variance in estimating the stochastic gradients. The high variance issue can be very pronounced in extremely large graphs, where it results in slow convergence and poor generalization. In this paper, we theoretically analyze the variance of sampling methods and show that, due to the composite structure of empirical risk, the variance of any sampling method can be decomposed into \textit{embedding approximation variance} in the forward stage and \textit{stochastic gradient variance} in the backward stage that necessities mitigating both types of variance to obtain faster convergence rate. We propose a decoupled variance reduction strategy that employs (approximate) gradient information to adaptively sample nodes with minimal variance, and explicitly reduces the variance introduced by embedding approximation. We show theoretically and empirically that the proposed method, even with smaller mini-batch sizes, enjoys a faster convergence rate and entails a better generalization compared to the existing methods.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191