
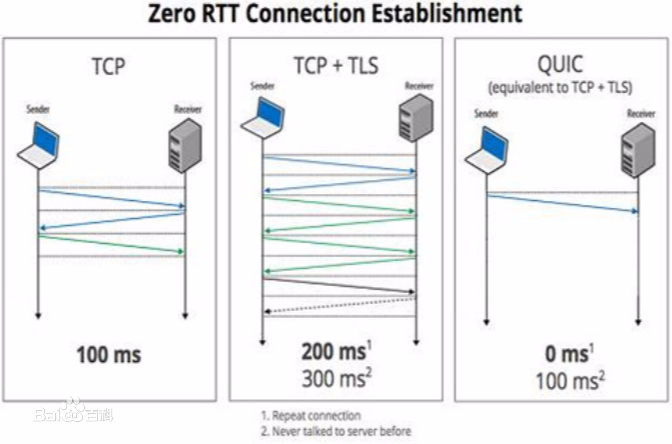

With a standardization process that attracted many interest, QUIC can been seen as the next general-purpose transport protocol. Still, it does not provide true multipath support yet, missing some use cases that MPTCP can address. To fill that gap, the IETF recently adopted a multipath proposal merging all the proposed designs. While it focuses on its core components, there still remains one major design issue in the proposal: the number of packet number spaces that should be used. This paper provides experimental results with two different Multipath QUIC implementations based on NS3 simulations to understand the impact of using one packet number space per path or a single packet number space for the whole connection. Our results suggest that using one packet number space per path makes the Multipath QUIC connection more resilient to the receiver's acknowledgment strategy.
相關內容
In recent years, the accuracy of automatic lyrics alignment methods has increased considerably. Yet, many current approaches employ frameworks designed for automatic speech recognition (ASR) and do not exploit properties specific to music. Pitch is one important musical attribute of singing voice but it is often ignored by current systems as the lyrics content is considered independent of the pitch. In practice, however, there is a temporal correlation between the two as note starts often correlate with phoneme starts. At the same time the pitch is usually annotated with high temporal accuracy in ground truth data while the timing of lyrics is often only available at the line (or word) level. In this paper, we propose a multi-task learning approach for lyrics alignment that incorporates pitch and thus can make use of a new source of highly accurate temporal information. Our results show that the accuracy of the alignment result is indeed improved by our approach. As an additional contribution, we show that integrating boundary detection in the forced-alignment algorithm reduces cross-line errors, which improves the accuracy even further.
This work addresses the task of electric vehicle (EV) charging inlet detection for autonomous EV charging robots. Recently, automated EV charging systems have received huge attention to improve users' experience and to efficiently utilize charging infrastructures and parking lots. However, most related works have focused on system design, robot control, planning, and manipulation. Towards robust EV charging inlet detection, we propose a new dataset (EVCI dataset) and a novel data augmentation method that is based on image-to-image translation where typical image-to-image translation methods synthesize a new image in a different domain given an image. To the best of our knowledge, the EVCI dataset is the first EV charging inlet dataset. For the data augmentation method, we focus on being able to control synthesized images' captured environments (e.g., time, lighting) in an intuitive way. To achieve this, we first propose the environment guide vector that humans can intuitively interpret. We then propose a novel image-to-image translation network that translates a given image towards the environment described by the vector. Accordingly, it aims to synthesize a new image that has the same content as the given image while looking like captured in the provided environment by the environment guide vector. Lastly, we train a detection method using the augmented dataset. Through experiments on the EVCI dataset, we demonstrate that the proposed method outperforms the state-of-the-art methods. We also show that the proposed method is able to control synthesized images using an image and environment guide vectors.
An important preliminary step of optical character recognition systems is the detection of text rows. To address this task in the context of historical data with missing labels, we propose a self-paced learning algorithm capable of improving the row detection performance. We conjecture that pages with more ground-truth bounding boxes are less likely to have missing annotations. Based on this hypothesis, we sort the training examples in descending order with respect to the number of ground-truth bounding boxes, and organize them into k batches. Using our self-paced learning method, we train a row detector over k iterations, progressively adding batches with less ground-truth annotations. At each iteration, we combine the ground-truth bounding boxes with pseudo-bounding boxes (bounding boxes predicted by the model itself) using non-maximum suppression, and we include the resulting annotations at the next training iteration. We demonstrate that our self-paced learning strategy brings significant performance gains on two data sets of historical documents, improving the average precision of YOLOv4 with more than 12% on one data set and 39% on the other.
Conducting experiments with objectives that take significant delays to materialize (e.g. conversions, add-to-cart events, etc.) is challenging. Although the classical "split sample testing" is still valid for the delayed feedback, the experiment will take longer to complete, which also means spending more resources on worse-performing strategies due to their fixed allocation schedules. Alternatively, adaptive approaches such as "multi-armed bandits" are able to effectively reduce the cost of experimentation. But these methods generally cannot handle delayed objectives directly out of the box. This paper presents an adaptive experimentation solution tailored for delayed binary feedback objectives by estimating the real underlying objectives before they materialize and dynamically allocating variants based on the estimates. Experiments show that the proposed method is more efficient for delayed feedback compared to various other approaches and is robust in different settings. In addition, we describe an experimentation product powered by this algorithm. This product is currently deployed in the online experimentation platform of JD.com, a large e-commerce company and a publisher of digital ads.
Multiplying matrices is among the most fundamental and compute-intensive operations in machine learning. Consequently, there has been significant work on efficiently approximating matrix multiplies. We introduce a learning-based algorithm for this task that greatly outperforms existing methods. Experiments using hundreds of matrices from diverse domains show that it often runs $100\times$ faster than exact matrix products and $10\times$ faster than current approximate methods. In the common case that one matrix is known ahead of time, our method also has the interesting property that it requires zero multiply-adds. These results suggest that a mixture of hashing, averaging, and byte shuffling$-$the core operations of our method$-$could be a more promising building block for machine learning than the sparsified, factorized, and/or scalar quantized matrix products that have recently been the focus of substantial research and hardware investment.
Importance sampling is one of the most widely used variance reduction strategies in Monte Carlo rendering. In this paper, we propose a novel importance sampling technique that uses a neural network to learn how to sample from a desired density represented by a set of samples. Our approach considers an existing Monte Carlo rendering algorithm as a black box. During a scene-dependent training phase, we learn to generate samples with a desired density in the primary sample space of the rendering algorithm using maximum likelihood estimation. We leverage a recent neural network architecture that was designed to represent real-valued non-volume preserving ('Real NVP') transformations in high dimensional spaces. We use Real NVP to non-linearly warp primary sample space and obtain desired densities. In addition, Real NVP efficiently computes the determinant of the Jacobian of the warp, which is required to implement the change of integration variables implied by the warp. A main advantage of our approach is that it is agnostic of underlying light transport effects, and can be combined with many existing rendering techniques by treating them as a black box. We show that our approach leads to effective variance reduction in several practical scenarios.
This paper proposes a Reinforcement Learning (RL) algorithm to synthesize policies for a Markov Decision Process (MDP), such that a linear time property is satisfied. We convert the property into a Limit Deterministic Buchi Automaton (LDBA), then construct a product MDP between the automaton and the original MDP. A reward function is then assigned to the states of the product automaton, according to accepting conditions of the LDBA. With this reward function, our algorithm synthesizes a policy that satisfies the linear time property: as such, the policy synthesis procedure is "constrained" by the given specification. Additionally, we show that the RL procedure sets up an online value iteration method to calculate the maximum probability of satisfying the given property, at any given state of the MDP - a convergence proof for the procedure is provided. Finally, the performance of the algorithm is evaluated via a set of numerical examples. We observe an improvement of one order of magnitude in the number of iterations required for the synthesis compared to existing approaches.
In a weakly-supervised scenario object detectors need to be trained using image-level annotation alone. Since bounding-box-level ground truth is not available, most of the solutions proposed so far are based on an iterative, Multiple Instance Learning framework in which the current classifier is used to select the highest-confidence boxes in each image, which are treated as pseudo-ground truth in the next training iteration. However, the errors of an immature classifier can make the process drift, usually introducing many of false positives in the training dataset. To alleviate this problem, we propose in this paper a training protocol based on the self-paced learning paradigm. The main idea is to iteratively select a subset of images and boxes that are the most reliable, and use them for training. While in the past few years similar strategies have been adopted for SVMs and other classifiers, we are the first showing that a self-paced approach can be used with deep-network-based classifiers in an end-to-end training pipeline. The method we propose is built on the fully-supervised Fast-RCNN architecture and can be applied to similar architectures which represent the input image as a bag of boxes. We show state-of-the-art results on Pascal VOC 2007, Pascal VOC 2010 and ILSVRC 2013. On ILSVRC 2013 our results based on a low-capacity AlexNet network outperform even those weakly-supervised approaches which are based on much higher-capacity networks.
Image segmentation is an important component of many image understanding systems. It aims to group pixels in a spatially and perceptually coherent manner. Typically, these algorithms have a collection of parameters that control the degree of over-segmentation produced. It still remains a challenge to properly select such parameters for human-like perceptual grouping. In this work, we exploit the diversity of segments produced by different choices of parameters. We scan the segmentation parameter space and generate a collection of image segmentation hypotheses (from highly over-segmented to under-segmented). These are fed into a cost minimization framework that produces the final segmentation by selecting segments that: (1) better describe the natural contours of the image, and (2) are more stable and persistent among all the segmentation hypotheses. We compare our algorithm's performance with state-of-the-art algorithms, showing that we can achieve improved results. We also show that our framework is robust to the choice of segmentation kernel that produces the initial set of hypotheses.
Like any large software system, a full-fledged DBMS offers an overwhelming amount of configuration knobs. These range from static initialisation parameters like buffer sizes, degree of concurrency, or level of replication to complex runtime decisions like creating a secondary index on a particular column or reorganising the physical layout of the store. To simplify the configuration, industry grade DBMSs are usually shipped with various advisory tools, that provide recommendations for given workloads and machines. However, reality shows that the actual configuration, tuning, and maintenance is usually still done by a human administrator, relying on intuition and experience. Recent work on deep reinforcement learning has shown very promising results in solving problems, that require such a sense of intuition. For instance, it has been applied very successfully in learning how to play complicated games with enormous search spaces. Motivated by these achievements, in this work we explore how deep reinforcement learning can be used to administer a DBMS. First, we will describe how deep reinforcement learning can be used to automatically tune an arbitrary software system like a DBMS by defining a problem environment. Second, we showcase our concept of NoDBA at the concrete example of index selection and evaluate how well it recommends indexes for given workloads.



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191