


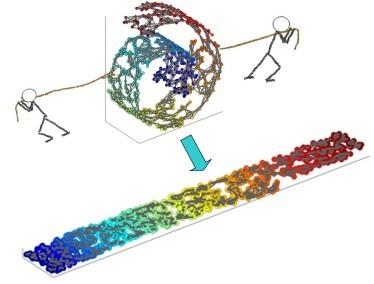
As a pivotal approach in machine learning and data science, manifold learning aims to uncover the intrinsic low-dimensional structure within complex nonlinear manifolds in high-dimensional space. By exploiting the manifold hypothesis, various techniques for nonlinear dimension reduction have been developed to facilitate visualization, classification, clustering, and gaining key insights. Although existing manifold learning methods have achieved remarkable successes, they still suffer from extensive distortions incurred in the global structure, which hinders the understanding of underlying patterns. Scalability issues also limit their applicability for handling large-scale data. Here, we propose a scalable manifold learning (scML) method that can manipulate large-scale and high-dimensional data in an efficient manner. It starts by seeking a set of landmarks to construct the low-dimensional skeleton of the entire data, and then incorporates the non-landmarks into the learned space based on the constrained locally linear embedding (CLLE). We empirically validated the effectiveness of scML on synthetic datasets and real-world benchmarks of different types, and applied it to analyze the single-cell transcriptomics and detect anomalies in electrocardiogram (ECG) signals. scML scales well with increasing data sizes and embedding dimensions, and exhibits promising performance in preserving the global structure. The experiments demonstrate notable robustness in embedding quality as the sample rate decreases.
相關內容
The number of sampling methods could be daunting for a practitioner looking to cast powerful machine learning methods to their specific problem. This paper takes a theoretical stance to review and organize many sampling approaches in the ``generative modeling'' setting, where one wants to generate new data that are similar to some training examples. By revealing links between existing methods, it might prove useful to overcome some of the current challenges in sampling with diffusion models, such as long inference time due to diffusion simulation, or the lack of diversity in generated samples.
We present a fully-integrated lattice Boltzmann (LB) method for fluid--structure interaction (FSI) simulations that efficiently models deformable solids in complex suspensions and active systems. Our Eulerian method (LBRMT) couples finite-strain solids to the LB fluid on the same fixed computational grid with the reference map technique (RMT). An integral part of the LBRMT is a new LB boundary condition for moving deformable interfaces across different densities. With this fully Eulerian solid--fluid coupling, the LBRMT is well-suited for parallelization and simulating multi-body contact without remeshing or extra meshes. We validate its accuracy via a benchmark of a deformable solid in a lid-driven cavity, then showcase its versatility through examples of soft solids rotating and settling. With simulations of complex suspensions mixing, we highlight potentials of the LBRMT for studying collective behavior in soft matter and biofluid dynamics.
In theoretical neuroscience, recent work leverages deep learning tools to explore how some network attributes critically influence its learning dynamics. Notably, initial weight distributions with small (resp. large) variance may yield a rich (resp. lazy) regime, where significant (resp. minor) changes to network states and representation are observed over the course of learning. However, in biology, neural circuit connectivity could exhibit a low-rank structure and therefore differs markedly from the random initializations generally used for these studies. As such, here we investigate how the structure of the initial weights -- in particular their effective rank -- influences the network learning regime. Through both empirical and theoretical analyses, we discover that high-rank initializations typically yield smaller network changes indicative of lazier learning, a finding we also confirm with experimentally-driven initial connectivity in recurrent neural networks. Conversely, low-rank initialization biases learning towards richer learning. Importantly, however, as an exception to this rule, we find lazier learning can still occur with a low-rank initialization that aligns with task and data statistics. Our research highlights the pivotal role of initial weight structures in shaping learning regimes, with implications for metabolic costs of plasticity and risks of catastrophic forgetting.
Understanding the internal representations learned by neural networks is a cornerstone challenge in the science of machine learning. While there have been significant recent strides in some cases towards understanding how neural networks implement specific target functions, this paper explores a complementary question -- why do networks arrive at particular computational strategies? Our inquiry focuses on the algebraic learning tasks of modular addition, sparse parities, and finite group operations. Our primary theoretical findings analytically characterize the features learned by stylized neural networks for these algebraic tasks. Notably, our main technique demonstrates how the principle of margin maximization alone can be used to fully specify the features learned by the network. Specifically, we prove that the trained networks utilize Fourier features to perform modular addition and employ features corresponding to irreducible group-theoretic representations to perform compositions in general groups, aligning closely with the empirical observations of Nanda et al. and Chughtai et al. More generally, we hope our techniques can help to foster a deeper understanding of why neural networks adopt specific computational strategies.
We propose center-outward superquantile and expected shortfall functions, with applications to multivariate risk measurements, extending the standard notion of value at risk and conditional value at risk from the real line to $\mathbb{R}^d$. Our new concepts are built upon the recent definition of Monge-Kantorovich quantiles based on the theory of optimal transport, and they provide a natural way to characterize multivariate tail probabilities and central areas of point clouds. They preserve the univariate interpretation of a typical observation that lies beyond or ahead a quantile, but in a meaningful multivariate way. We show that they characterize random vectors and their convergence in distribution, which underlines their importance. Our new concepts are illustrated on both simulated and real datasets.
We present an algorithm for the exact computer-aided construction of the Voronoi cells of lattices with known symmetry group. Our algorithm scales better than linearly with the total number of faces and is applicable to dimensions beyond 12, which previous methods could not achieve. The new algorithm is applied to the Coxeter-Todd lattice $K_{12}$ as well as to a family of lattices obtained from laminating $K_{12}$. By optimizing this family, we obtain a new best 13-dimensional lattice quantizer (among the lattices with published exact quantizer constants).
We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly log-concave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
Artificial neural networks thrive in solving the classification problem for a particular rigid task, acquiring knowledge through generalized learning behaviour from a distinct training phase. The resulting network resembles a static entity of knowledge, with endeavours to extend this knowledge without targeting the original task resulting in a catastrophic forgetting. Continual learning shifts this paradigm towards networks that can continually accumulate knowledge over different tasks without the need to retrain from scratch. We focus on task incremental classification, where tasks arrive sequentially and are delineated by clear boundaries. Our main contributions concern 1) a taxonomy and extensive overview of the state-of-the-art, 2) a novel framework to continually determine the stability-plasticity trade-off of the continual learner, 3) a comprehensive experimental comparison of 11 state-of-the-art continual learning methods and 4 baselines. We empirically scrutinize method strengths and weaknesses on three benchmarks, considering Tiny Imagenet and large-scale unbalanced iNaturalist and a sequence of recognition datasets. We study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented, and qualitatively compare methods in terms of required memory, computation time, and storage.
Deep learning is usually described as an experiment-driven field under continuous criticizes of lacking theoretical foundations. This problem has been partially fixed by a large volume of literature which has so far not been well organized. This paper reviews and organizes the recent advances in deep learning theory. The literature is categorized in six groups: (1) complexity and capacity-based approaches for analyzing the generalizability of deep learning; (2) stochastic differential equations and their dynamic systems for modelling stochastic gradient descent and its variants, which characterize the optimization and generalization of deep learning, partially inspired by Bayesian inference; (3) the geometrical structures of the loss landscape that drives the trajectories of the dynamic systems; (4) the roles of over-parameterization of deep neural networks from both positive and negative perspectives; (5) theoretical foundations of several special structures in network architectures; and (6) the increasingly intensive concerns in ethics and security and their relationships with generalizability.
Deep learning constitutes a recent, modern technique for image processing and data analysis, with promising results and large potential. As deep learning has been successfully applied in various domains, it has recently entered also the domain of agriculture. In this paper, we perform a survey of 40 research efforts that employ deep learning techniques, applied to various agricultural and food production challenges. We examine the particular agricultural problems under study, the specific models and frameworks employed, the sources, nature and pre-processing of data used, and the overall performance achieved according to the metrics used at each work under study. Moreover, we study comparisons of deep learning with other existing popular techniques, in respect to differences in classification or regression performance. Our findings indicate that deep learning provides high accuracy, outperforming existing commonly used image processing techniques.

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191