


With the emergence of edge computing, there is an increasing need for running convolutional neural network based object detection on small form factor edge computing devices with limited compute and thermal budget for applications such as video surveillance. To address this problem, efficient object detection frameworks such as YOLO and SSD were proposed. However, SSD based object detection that uses VGG16 as backend network is insufficient to achieve real time speed on edge devices. To further improve the detection speed, the backend network is replaced by more efficient networks such as SqueezeNet and MobileNet. Although the speed is greatly improved, it comes with a price of lower accuracy. In this paper, we propose an efficient SSD named Fire SSD. Fire SSD achieves 70.7mAP on Pascal VOC 2007 test set. Fire SSD achieves the speed of 30.6FPS on low power mainstream CPU and is about 6 times faster than SSD300 and has about 4 times smaller model size. Fire SSD also achieves 22.2FPS on integrated GPU.
相關內容
Although YOLOv2 approach is extremely fast on object detection; its backbone network has the low ability on feature extraction and fails to make full use of multi-scale local region features, which restricts the improvement of object detection accuracy. Therefore, this paper proposed a DC-SPP-YOLO (Dense Connection and Spatial Pyramid Pooling Based YOLO) approach for ameliorating the object detection accuracy of YOLOv2. Specifically, the dense connection of convolution layers is employed in the backbone network of YOLOv2 to strengthen the feature extraction and alleviate the vanishing-gradient problem. Moreover, an improved spatial pyramid pooling is introduced to pool and concatenate the multi-scale local region features, so that the network can learn the object features more comprehensively. The DC-SPP-YOLO model is established and trained based on a new loss function composed of mean square error and cross entropy, and the object detection is realized. Experiments demonstrate that the mAP (mean Average Precision) of DC-SPP-YOLO proposed on PASCAL VOC datasets and UA-DETRAC datasets is higher than that of YOLOv2; the object detection accuracy of DC-SPP-YOLO is superior to YOLOv2 by strengthening feature extraction and using the multi-scale local region features.
In recent year, tremendous strides have been made in face detection thanks to deep learning. However, most published face detectors deteriorate dramatically as the faces become smaller. In this paper, we present the Small Faces Attention (SFA) face detector to better detect faces with small scale. First, we propose a new scale-invariant face detection architecture which pays more attention to small faces, including 4-branch detection architecture and small faces sensitive anchor design. Second, feature maps fusion strategy is applied in SFA by partially combining high-level features into low-level features to further improve the ability of finding hard faces. Third, we use multi-scale training and testing strategy to enhance face detection performance in practice. Comprehensive experiments show that SFA significantly improves face detection performance, especially on small faces. Our real-time SFA face detector can run at 5 FPS on a single GPU as well as maintain high performance. Besides, our final SFA face detector achieves state-of-the-art detection performance on challenging face detection benchmarks, including WIDER FACE and FDDB datasets, with competitive runtime speed. Both our code and models will be available to the research community.
We'd like to share a simple tweak of Single Shot Multibox Detector (SSD) family of detectors, which is effective in reducing model size while maintaining the same quality. We share box predictors across all scales, and replace convolution between scales with max pooling. This has two advantages over vanilla SSD: (1) it avoids score miscalibration across scales; (2) the shared predictor sees the training data over all scales. Since we reduce the number of predictors to one, and trim all convolutions between them, model size is significantly smaller. We empirically show that these changes do not hurt model quality compared to vanilla SSD.
Accurate Traffic Sign Detection (TSD) can help intelligent systems make better decisions according to the traffic regulations. TSD, regarded as a typical small object detection problem in some way, is fundamental in Advanced Driver Assistance Systems (ADAS) and self-driving. However, although deep neural networks have achieved human even superhuman performance on several tasks, due to their own limitations, small object detection is still an open question. In this paper, we proposed a brain-inspired network, named as KB-RANN, to handle this problem. Attention mechanism is an essential function of our brain, we used a novel recurrent attentive neural network to improve the detection accuracy in a fine-grained manner. Further, we combined domain specific knowledge and intuitive knowledge to improve the efficiency. Experimental result shows that our methods achieved better performance than several popular methods widely used in object detection. More significantly, we transplanted our method on our designed embedded system and deployed on our self-driving car successfully.
This paper introduces an online model for object detection in videos designed to run in real-time on low-powered mobile and embedded devices. Our approach combines fast single-image object detection with convolutional long short term memory (LSTM) layers to create an interweaved recurrent-convolutional architecture. Additionally, we propose an efficient Bottleneck-LSTM layer that significantly reduces computational cost compared to regular LSTMs. Our network achieves temporal awareness by using Bottleneck-LSTMs to refine and propagate feature maps across frames. This approach is substantially faster than existing detection methods in video, outperforming the fastest single-frame models in model size and computational cost while attaining accuracy comparable to much more expensive single-frame models on the Imagenet VID 2015 dataset. Our model reaches a real-time inference speed of up to 15 FPS on a mobile CPU.
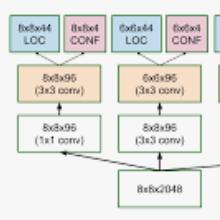
Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
Single Shot MultiBox Detector (SSD) is one of the fastest algorithms in the current object detection field, which uses fully convolutional neural network to detect all scaled objects in an image. Deconvolutional Single Shot Detector (DSSD) is an approach which introduces more context information by adding the deconvolution module to SSD. And the mean Average Precision (mAP) of DSSD on PASCAL VOC2007 is improved from SSD's 77.5% to 78.6%. Although DSSD obtains higher mAP than SSD by 1.1%, the frames per second (FPS) decreases from 46 to 11.8. In this paper, we propose a single stage end-to-end image detection model called ESSD to overcome this dilemma. Our solution to this problem is to cleverly extend better context information for the shallow layers of the best single stage (e.g. SSD) detectors. Experimental results show that our model can reach 79.4% mAP, which is higher than DSSD and SSD by 0.8 and 1.9 points respectively. Meanwhile, our testing speed is 25 FPS in Titan X GPU which is more than double the original DSSD.
SSD (Single Shot Multibox Detetor) is one of the best object detection algorithms with both high accuracy and fast speed. However, SSD's feature pyramid detection method makes it hard to fuse the features from different scales. In this paper, we proposed FSSD (Feature Fusion Single Shot Multibox Detector), an enhanced SSD with a novel and lightweight feature fusion module which can improve the performance significantly over SSD with just a little speed drop. In the feature fusion module, features from different layers with different scales are concatenated together, followed by some down-sampling blocks to generate new feature pyramid, which will be fed to multibox detectors to predict the final detection results. On the Pascal VOC 2007 test, our network can achieve 82.7 mAP (mean average precision) at the speed of 65.8 FPS (frame per second) with the input size 300$\times$300 using a single Nvidia 1080Ti GPU. In addition, our result on COCO is also better than the conventional SSD with a large margin. Our FSSD outperforms a lot of state-of-the-art object detection algorithms in both aspects of accuracy and speed. Code is available at //github.com/lzx1413/CAFFE_SSD/tree/fssd.
Object detection is considered one of the most challenging problems in this field of computer vision, as it involves the combination of object classification and object localization within a scene. Recently, deep neural networks (DNNs) have been demonstrated to achieve superior object detection performance compared to other approaches, with YOLOv2 (an improved You Only Look Once model) being one of the state-of-the-art in DNN-based object detection methods in terms of both speed and accuracy. Although YOLOv2 can achieve real-time performance on a powerful GPU, it still remains very challenging for leveraging this approach for real-time object detection in video on embedded computing devices with limited computational power and limited memory. In this paper, we propose a new framework called Fast YOLO, a fast You Only Look Once framework which accelerates YOLOv2 to be able to perform object detection in video on embedded devices in a real-time manner. First, we leverage the evolutionary deep intelligence framework to evolve the YOLOv2 network architecture and produce an optimized architecture (referred to as O-YOLOv2 here) that has 2.8X fewer parameters with just a ~2% IOU drop. To further reduce power consumption on embedded devices while maintaining performance, a motion-adaptive inference method is introduced into the proposed Fast YOLO framework to reduce the frequency of deep inference with O-YOLOv2 based on temporal motion characteristics. Experimental results show that the proposed Fast YOLO framework can reduce the number of deep inferences by an average of 38.13%, and an average speedup of ~3.3X for objection detection in video compared to the original YOLOv2, leading Fast YOLO to run an average of ~18FPS on a Nvidia Jetson TX1 embedded system.
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. Our SSD model is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stage and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component. Experimental results on the PASCAL VOC, MS COCO, and ILSVRC datasets confirm that SSD has comparable accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference. Compared to other single stage methods, SSD has much better accuracy, even with a smaller input image size. For $300\times 300$ input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia Titan X and for $500\times 500$ input, SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model. Code is available at //github.com/weiliu89/caffe/tree/ssd .
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191