
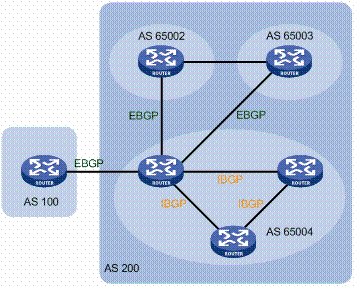

The Internet inter-domain routing system is vulnerable. On the control plane, the de facto Border Gateway Protocol (BGP) does not have built-in mechanisms to authenticate routing announcements, so an adversary can announce virtually arbitrary paths to hijack network traffic; on the data plane, it is difficult to ensure that actual forwarding path complies with the control plane decisions. The community has proposed significant research to secure the routing system. Yet, existing secure BGP protocols (e.g., BGPsec) are not incrementally deployable, and existing path authorization protocols are not compatible with the current Internet routing infrastructure. In this paper, we propose FC-BGP, the first secure Internet inter-domain routing system that can simultaneously authenticate BGP announcements and validate data plane forwarding in an efficient and incrementally-deployable manner. FC-BGP is built upon a novel primitive, name Forwarding Commitment, to certify an AS's routing intent on its directly connected hops. We analyze the security benefits of FC-BGP in the Internet at different deployment rates. Further, we implement a prototype of FC-BGP and extensively evaluate it over a large-scale overlay network with 100 virtual machines deployed globally. The results demonstrate that FC-BGP saves roughly 55% of the overhead required to validate BGP announcements compared with BGPsec, and meanwhile FC-BGP introduces a small overhead for building a globally-consistent view on the desirable forwarding paths.
相關內容
Generative Large Language Models (LLMs) show potential in data analysis, yet their full capabilities remain uncharted. Our work explores the capabilities of LLMs for creating and refining visualizations via conversational interfaces. We used an LLM to conduct a re-analysis of a prior Wizard-of-Oz study examining the use of chatbots for conducting visual analysis. We surfaced the strengths and weaknesses of LLM-driven analytic chatbots, finding that they fell short in supporting progressive visualization refinements. From these findings, we developed AI Threads, a multi-threaded analytic chatbot that enables analysts to proactively manage conversational context and improve the efficacy of its outputs. We evaluate its usability through a crowdsourced study (n=40) and in-depth interviews with expert analysts (n=10). We further demonstrate the capabilities of AI Threads on a dataset outside the LLM's training corpus. Our findings show the potential of LLMs while also surfacing challenges and fruitful avenues for future research.
In this work, we present Transformer-based Powered Descent Guidance (T-PDG), a scalable algorithm for reducing the computational complexity of the direct optimization formulation of the spacecraft powered descent guidance problem. T-PDG uses data from prior runs of trajectory optimization algorithms to train a transformer neural network, which accurately predicts the relationship between problem parameters and the globally optimal solution for the powered descent guidance problem. The solution is encoded as the set of tight constraints corresponding to the constrained minimum-cost trajectory and the optimal final time of landing. By leveraging the attention mechanism of transformer neural networks, large sequences of time series data can be accurately predicted when given only the spacecraft state and landing site parameters. When applied to the real problem of Mars powered descent guidance, T-PDG reduces the time for computing the 3 degree of freedom fuel-optimal trajectory, when compared to lossless convexification, from an order of 1-8 seconds to less than 500 milliseconds. A safe and optimal solution is guaranteed by including a feasibility check in T-PDG before returning the final trajectory.
Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
Low-Rank Markov Decision Processes (MDPs) have recently emerged as a promising framework within the domain of reinforcement learning (RL), as they allow for provably approximately correct (PAC) learning guarantees while also incorporating ML algorithms for representation learning. However, current methods for low-rank MDPs are limited in that they only consider finite action spaces, and give vacuous bounds as $|\mathcal{A}| \to \infty$, which greatly limits their applicability. In this work, we study the problem of extending such methods to settings with continuous actions, and explore multiple concrete approaches for performing this extension. As a case study, we consider the seminal FLAMBE algorithm (Agarwal et al., 2020), which is a reward-agnostic method for PAC RL with low-rank MDPs. We show that, without any modifications to the algorithm, we obtain similar PAC bound when actions are allowed to be continuous. Specifically, when the model for transition functions satisfies a Holder smoothness condition w.r.t. actions, and either the policy class has a uniformly bounded minimum density or the reward function is also Holder smooth, we obtain a polynomial PAC bound that depends on the order of smoothness.
Conventional wheeled robots are unable to traverse scientifically interesting, but dangerous, cave environments. Multi-limbed climbing robot designs, such as ReachBot, are able to grasp irregular surface features and execute climbing motions to overcome obstacles, given suitable grasp locations. To support grasp site identification, we present a method for detecting rock cracks and edges, the SKeleton Intersection Loss (SKIL). SKIL is a loss designed for thin object segmentation that leverages the skeleton of the label. A dataset of rock face images was collected, manually annotated, and augmented with generated data. A new group of metrics, LineAcc, has been proposed for thin object segmentation such that the impact of the object width on the score is minimized. In addition, the metric is less sensitive to translation which can often lead to a score of zero when computing classical metrics such as Dice on thin objects. Our fine-tuned models outperform previous methods on similar thin object segmentation tasks such as blood vessel segmentation and show promise for integration onto a robotic system.
Model Predictive Control (MPC) is a popular strategy for controlling robots but is difficult for systems with contact due to the complex nature of hybrid dynamics. To implement MPC for systems with contact, dynamic models are often simplified or contact sequences fixed in time in order to plan trajectories efficiently. In this work, we extend Hybrid iterative Linear Quadratic Regulator to work in a MPC fashion (HiLQR MPC) by 1) modifying how the cost function is computed when contact modes do not align, 2) utilizing parallelizations when simulating rigid body dynamics, and 3) using efficient analytical derivative computations of the rigid body dynamics. The result is a system that can modify the contact sequence of the reference behavior and plan whole body motions cohesively -- which is crucial when dealing with large perturbations. HiLQR MPC is tested on two systems: first, the hybrid cost modification is validated on a simple actuated bouncing ball hybrid system. Then HiLQR MPC is compared against methods that utilize centroidal dynamic assumptions on a quadruped robot (Unitree A1). HiLQR MPC outperforms the centroidal methods in both simulation and hardware tests.
As a dedicated quantum device, Ising machines could solve large-scale binary optimization problems in milliseconds. There is emerging interest in utilizing Ising machines to train feedforward neural networks due to the prosperity of generative artificial intelligence. However, existing methods can only train single-layer feedforward networks because of the complex nonlinear network topology. This paper proposes an Ising learning algorithm to train quantized neural network (QNN), by incorporating two essential techinques, namely binary representation of topological network and order reduction of loss function. As far as we know, this is the first algorithm to train multi-layer feedforward networks on Ising machines, providing an alternative to gradient-based backpropagation. Firstly, training QNN is formulated as a quadratic constrained binary optimization (QCBO) problem by representing neuron connection and activation function as equality constraints. All quantized variables are encoded by binary bits based on binary encoding protocol. Secondly, QCBO is converted to a quadratic unconstrained binary optimization (QUBO) problem, that can be efficiently solved on Ising machines. The conversion leverages both penalty function and Rosenberg order reduction, who together eliminate equality constraints and reduce high-order loss function into a quadratic one. With some assumptions, theoretical analysis shows the space complexity of our algorithm is $\mathcal{O}(H^2L + HLN\log H)$, quantifying the required number of Ising spins. Finally, the algorithm effectiveness is validated with a simulated Ising machine on MNIST dataset. After annealing 700 ms, the classification accuracy achieves 98.3%. Among 100 runs, the success probability of finding the optimal solution is 72%. Along with the increasing number of spins on Ising machine, our algorithm has the potential to train deeper neural networks.
Graph Neural Networks (GNNs) have shown promising results on a broad spectrum of applications. Most empirical studies of GNNs directly take the observed graph as input, assuming the observed structure perfectly depicts the accurate and complete relations between nodes. However, graphs in the real world are inevitably noisy or incomplete, which could even exacerbate the quality of graph representations. In this work, we propose a novel Variational Information Bottleneck guided Graph Structure Learning framework, namely VIB-GSL, in the perspective of information theory. VIB-GSL advances the Information Bottleneck (IB) principle for graph structure learning, providing a more elegant and universal framework for mining underlying task-relevant relations. VIB-GSL learns an informative and compressive graph structure to distill the actionable information for specific downstream tasks. VIB-GSL deduces a variational approximation for irregular graph data to form a tractable IB objective function, which facilitates training stability. Extensive experimental results demonstrate that the superior effectiveness and robustness of VIB-GSL.
Graph Convolution Networks (GCNs) manifest great potential in recommendation. This is attributed to their capability on learning good user and item embeddings by exploiting the collaborative signals from the high-order neighbors. Like other GCN models, the GCN based recommendation models also suffer from the notorious over-smoothing problem - when stacking more layers, node embeddings become more similar and eventually indistinguishable, resulted in performance degradation. The recently proposed LightGCN and LR-GCN alleviate this problem to some extent, however, we argue that they overlook an important factor for the over-smoothing problem in recommendation, that is, high-order neighboring users with no common interests of a user can be also involved in the user's embedding learning in the graph convolution operation. As a result, the multi-layer graph convolution will make users with dissimilar interests have similar embeddings. In this paper, we propose a novel Interest-aware Message-Passing GCN (IMP-GCN) recommendation model, which performs high-order graph convolution inside subgraphs. The subgraph consists of users with similar interests and their interacted items. To form the subgraphs, we design an unsupervised subgraph generation module, which can effectively identify users with common interests by exploiting both user feature and graph structure. To this end, our model can avoid propagating negative information from high-order neighbors into embedding learning. Experimental results on three large-scale benchmark datasets show that our model can gain performance improvement by stacking more layers and outperform the state-of-the-art GCN-based recommendation models significantly.
Graph Convolutional Network (GCN) has been widely applied in transportation demand prediction due to its excellent ability to capture non-Euclidean spatial dependence among station-level or regional transportation demands. However, in most of the existing research, the graph convolution was implemented on a heuristically generated adjacency matrix, which could neither reflect the real spatial relationships of stations accurately, nor capture the multi-level spatial dependence of demands adaptively. To cope with the above problems, this paper provides a novel graph convolutional network for transportation demand prediction. Firstly, a novel graph convolution architecture is proposed, which has different adjacency matrices in different layers and all the adjacency matrices are self-learned during the training process. Secondly, a layer-wise coupling mechanism is provided, which associates the upper-level adjacency matrix with the lower-level one. It also reduces the scale of parameters in our model. Lastly, a unitary network is constructed to give the final prediction result by integrating the hidden spatial states with gated recurrent unit, which could capture the multi-level spatial dependence and temporal dynamics simultaneously. Experiments have been conducted on two real-world datasets, NYC Citi Bike and NYC Taxi, and the results demonstrate the superiority of our model over the state-of-the-art ones.
小貼士
登錄享
相關主題



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191