


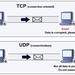
With the rapid development of Internet of Things (IoT) technology, intelligent systems are increasingly integrating into everyday life and people's homes. However, the proliferation of these technologies raises concerns about the security of smart home devices. These devices often face resource constraints and may connect to unreliable networks, posing risks to the data they handle. Securing IoT technology is crucial due to the sensitive data involved. Preventing energy attacks and ensuring the security of IoT infrastructure are key challenges in modern smart homes. Monitoring energy consumption can be an effective approach to detecting abnormal behavior and IoT cyberattacks. Lightweight algorithms are necessary to accommodate the resource limitations of IoT devices. This paper presents a lightweight technique for detecting energy consumption attacks on smart home devices by analyzing received packets. The proposed algorithm considers TCP, UDP, and MQTT protocols, as well as device statuses (Idle, active, under attack). It accounts for resource constraints and promptly alerts administrators upon detecting an attack. The proposed approach effectively identifies energy consumption attacks by measuring packet reception rates for different protocols.
相關內容
Intelligent transportation systems play a crucial role in modern traffic management and optimization, greatly improving traffic efficiency and safety. With the rapid development of generative artificial intelligence (Generative AI) technologies in the fields of image generation and natural language processing, generative AI has also played a crucial role in addressing key issues in intelligent transportation systems, such as data sparsity, difficulty in observing abnormal scenarios, and in modeling data uncertainty. In this review, we systematically investigate the relevant literature on generative AI techniques in addressing key issues in different types of tasks in intelligent transportation systems. First, we introduce the principles of different generative AI techniques, and their potential applications. Then, we classify tasks in intelligent transportation systems into four types: traffic perception, traffic prediction, traffic simulation, and traffic decision-making. We systematically illustrate how generative AI techniques addresses key issues in these four different types of tasks. Finally, we summarize the challenges faced in applying generative AI to intelligent transportation systems, and discuss future research directions based on different application scenarios.
There are now over 20 commercial vector database management systems (VDBMSs), all produced within the past five years. But embedding-based retrieval has been studied for over ten years, and similarity search a staggering half century and more. Driving this shift from algorithms to systems are new data intensive applications, notably large language models, that demand vast stores of unstructured data coupled with reliable, secure, fast, and scalable query processing capability. A variety of new data management techniques now exist for addressing these needs, however there is no comprehensive survey to thoroughly review these techniques and systems. We start by identifying five main obstacles to vector data management, namely vagueness of semantic similarity, large size of vectors, high cost of similarity comparison, lack of natural partitioning that can be used for indexing, and difficulty of efficiently answering hybrid queries that require both attributes and vectors. Overcoming these obstacles has led to new approaches to query processing, storage and indexing, and query optimization and execution. For query processing, a variety of similarity scores and query types are now well understood; for storage and indexing, techniques include vector compression, namely quantization, and partitioning based on randomization, learning partitioning, and navigable partitioning; for query optimization and execution, we describe new operators for hybrid queries, as well as techniques for plan enumeration, plan selection, and hardware accelerated execution. These techniques lead to a variety of VDBMSs across a spectrum of design and runtime characteristics, including native systems specialized for vectors and extended systems that incorporate vector capabilities into existing systems. We then discuss benchmarks, and finally we outline research challenges and point the direction for future work.
Mathematical reasoning is a fundamental aspect of human intelligence and is applicable in various fields, including science, engineering, finance, and everyday life. The development of artificial intelligence (AI) systems capable of solving math problems and proving theorems has garnered significant interest in the fields of machine learning and natural language processing. For example, mathematics serves as a testbed for aspects of reasoning that are challenging for powerful deep learning models, driving new algorithmic and modeling advances. On the other hand, recent advances in large-scale neural language models have opened up new benchmarks and opportunities to use deep learning for mathematical reasoning. In this survey paper, we review the key tasks, datasets, and methods at the intersection of mathematical reasoning and deep learning over the past decade. We also evaluate existing benchmarks and methods, and discuss future research directions in this domain.
Knowledge graphs represent factual knowledge about the world as relationships between concepts and are critical for intelligent decision making in enterprise applications. New knowledge is inferred from the existing facts in the knowledge graphs by encoding the concepts and relations into low-dimensional feature vector representations. The most effective representations for this task, called Knowledge Graph Embeddings (KGE), are learned through neural network architectures. Due to their impressive predictive performance, they are increasingly used in high-impact domains like healthcare, finance and education. However, are the black-box KGE models adversarially robust for use in domains with high stakes? This thesis argues that state-of-the-art KGE models are vulnerable to data poisoning attacks, that is, their predictive performance can be degraded by systematically crafted perturbations to the training knowledge graph. To support this argument, two novel data poisoning attacks are proposed that craft input deletions or additions at training time to subvert the learned model's performance at inference time. These adversarial attacks target the task of predicting the missing facts in knowledge graphs using KGE models, and the evaluation shows that the simpler attacks are competitive with or outperform the computationally expensive ones. The thesis contributions not only highlight and provide an opportunity to fix the security vulnerabilities of KGE models, but also help to understand the black-box predictive behaviour of KGE models.
In pace with developments in the research field of artificial intelligence, knowledge graphs (KGs) have attracted a surge of interest from both academia and industry. As a representation of semantic relations between entities, KGs have proven to be particularly relevant for natural language processing (NLP), experiencing a rapid spread and wide adoption within recent years. Given the increasing amount of research work in this area, several KG-related approaches have been surveyed in the NLP research community. However, a comprehensive study that categorizes established topics and reviews the maturity of individual research streams remains absent to this day. Contributing to closing this gap, we systematically analyzed 507 papers from the literature on KGs in NLP. Our survey encompasses a multifaceted review of tasks, research types, and contributions. As a result, we present a structured overview of the research landscape, provide a taxonomy of tasks, summarize our findings, and highlight directions for future work.
With the advent of 5G commercialization, the need for more reliable, faster, and intelligent telecommunication systems are envisaged for the next generation beyond 5G (B5G) radio access technologies. Artificial Intelligence (AI) and Machine Learning (ML) are not just immensely popular in the service layer applications but also have been proposed as essential enablers in many aspects of B5G networks, from IoT devices and edge computing to cloud-based infrastructures. However, most of the existing surveys in B5G security focus on the performance of AI/ML models and their accuracy, but they often overlook the accountability and trustworthiness of the models' decisions. Explainable AI (XAI) methods are promising techniques that would allow system developers to identify the internal workings of AI/ML black-box models. The goal of using XAI in the security domain of B5G is to allow the decision-making processes of the security of systems to be transparent and comprehensible to stakeholders making the systems accountable for automated actions. In every facet of the forthcoming B5G era, including B5G technologies such as RAN, zero-touch network management, E2E slicing, this survey emphasizes the role of XAI in them and the use cases that the general users would ultimately enjoy. Furthermore, we presented the lessons learned from recent efforts and future research directions on top of the currently conducted projects involving XAI.
As soon as abstract mathematical computations were adapted to computation on digital computers, the problem of efficient representation, manipulation, and communication of the numerical values in those computations arose. Strongly related to the problem of numerical representation is the problem of quantization: in what manner should a set of continuous real-valued numbers be distributed over a fixed discrete set of numbers to minimize the number of bits required and also to maximize the accuracy of the attendant computations? This perennial problem of quantization is particularly relevant whenever memory and/or computational resources are severely restricted, and it has come to the forefront in recent years due to the remarkable performance of Neural Network models in computer vision, natural language processing, and related areas. Moving from floating-point representations to low-precision fixed integer values represented in four bits or less holds the potential to reduce the memory footprint and latency by a factor of 16x; and, in fact, reductions of 4x to 8x are often realized in practice in these applications. Thus, it is not surprising that quantization has emerged recently as an important and very active sub-area of research in the efficient implementation of computations associated with Neural Networks. In this article, we survey approaches to the problem of quantizing the numerical values in deep Neural Network computations, covering the advantages/disadvantages of current methods. With this survey and its organization, we hope to have presented a useful snapshot of the current research in quantization for Neural Networks and to have given an intelligent organization to ease the evaluation of future research in this area.
Deep neural networks (DNNs) are successful in many computer vision tasks. However, the most accurate DNNs require millions of parameters and operations, making them energy, computation and memory intensive. This impedes the deployment of large DNNs in low-power devices with limited compute resources. Recent research improves DNN models by reducing the memory requirement, energy consumption, and number of operations without significantly decreasing the accuracy. This paper surveys the progress of low-power deep learning and computer vision, specifically in regards to inference, and discusses the methods for compacting and accelerating DNN models. The techniques can be divided into four major categories: (1) parameter quantization and pruning, (2) compressed convolutional filters and matrix factorization, (3) network architecture search, and (4) knowledge distillation. We analyze the accuracy, advantages, disadvantages, and potential solutions to the problems with the techniques in each category. We also discuss new evaluation metrics as a guideline for future research.
Deep convolutional neural networks (CNNs) have recently achieved great success in many visual recognition tasks. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance. During the past few years, tremendous progress has been made in this area. In this paper, we survey the recent advanced techniques for compacting and accelerating CNNs model developed. These techniques are roughly categorized into four schemes: parameter pruning and sharing, low-rank factorization, transferred/compact convolutional filters, and knowledge distillation. Methods of parameter pruning and sharing will be described at the beginning, after that the other techniques will be introduced. For each scheme, we provide insightful analysis regarding the performance, related applications, advantages, and drawbacks etc. Then we will go through a few very recent additional successful methods, for example, dynamic capacity networks and stochastic depths networks. After that, we survey the evaluation matrix, the main datasets used for evaluating the model performance and recent benchmarking efforts. Finally, we conclude this paper, discuss remaining challenges and possible directions on this topic.
Machine learning techniques have deeply rooted in our everyday life. However, since it is knowledge- and labor-intensive to pursue good learning performance, human experts are heavily involved in every aspect of machine learning. In order to make machine learning techniques easier to apply and reduce the demand for experienced human experts, automated machine learning (AutoML) has emerged as a hot topic with both industrial and academic interest. In this paper, we provide an up to date survey on AutoML. First, we introduce and define the AutoML problem, with inspiration from both realms of automation and machine learning. Then, we propose a general AutoML framework that not only covers most existing approaches to date but also can guide the design for new methods. Subsequently, we categorize and review the existing works from two aspects, i.e., the problem setup and the employed techniques. Finally, we provide a detailed analysis of AutoML approaches and explain the reasons underneath their successful applications. We hope this survey can serve as not only an insightful guideline for AutoML beginners but also an inspiration for future research.
小貼士
登錄享
相關主題



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191