

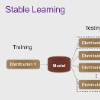
Deep learning techniques for medical image analysis usually suffer from the domain shift between source and target data. Most existing works focus on unsupervised domain adaptation (UDA). However, in practical applications, privacy issues are much more severe. For example, the data of different hospitals have domain shifts due to equipment problems, and data of the two domains cannot be available simultaneously because of privacy. In this challenge defined as Source-Free UDA, the previous UDA medical methods are limited. Although a variety of medical source-free unsupervised domain adaption (MSFUDA) methods have been proposed, we found they fall into an over-fitting dilemma called "longer training, worse performance." Therefore, we propose the Stable Learning (SL) strategy to address the dilemma. SL is a scalable method and can be integrated with other research, which consists of Weight Consolidation and Entropy Increase. First, we apply Weight Consolidation to retain domain-invariant knowledge and then we design Entropy Increase to avoid over-learning. Comparative experiments prove the effectiveness of SL. We also have done extensive ablation experiments. Besides, We will release codes including a variety of MSFUDA methods.
相關內容
Inverse rendering methods aim to estimate geometry, materials and illumination from multi-view RGB images. In order to achieve better decomposition, recent approaches attempt to model indirect illuminations reflected from different materials via Spherical Gaussians (SG), which, however, tends to blur the high-frequency reflection details. In this paper, we propose an end-to-end inverse rendering pipeline that decomposes materials and illumination from multi-view images, while considering near-field indirect illumination. In a nutshell, we introduce the Monte Carlo sampling based path tracing and cache the indirect illumination as neural radiance, enabling a physics-faithful and easy-to-optimize inverse rendering method. To enhance efficiency and practicality, we leverage SG to represent the smooth environment illuminations and apply importance sampling techniques. To supervise indirect illuminations from unobserved directions, we develop a novel radiance consistency constraint between implicit neural radiance and path tracing results of unobserved rays along with the joint optimization of materials and illuminations, thus significantly improving the decomposition performance. Extensive experiments demonstrate that our method outperforms the state-of-the-art on multiple synthetic and real datasets, especially in terms of inter-reflection decomposition.Our code and data are available at //woolseyyy.github.io/nefii/.
The accuracy of learning-based optical flow estimation models heavily relies on the realism of the training datasets. Current approaches for generating such datasets either employ synthetic data or generate images with limited realism. However, the domain gap of these data with real-world scenes constrains the generalization of the trained model to real-world applications. To address this issue, we investigate generating realistic optical flow datasets from real-world images. Firstly, to generate highly realistic new images, we construct a layered depth representation, known as multiplane images (MPI), from single-view images. This allows us to generate novel view images that are highly realistic. To generate optical flow maps that correspond accurately to the new image, we calculate the optical flows of each plane using the camera matrix and plane depths. We then project these layered optical flows into the output optical flow map with volume rendering. Secondly, to ensure the realism of motion, we present an independent object motion module that can separate the camera and dynamic object motion in MPI. This module addresses the deficiency in MPI-based single-view methods, where optical flow is generated only by camera motion and does not account for any object movement. We additionally devise a depth-aware inpainting module to merge new images with dynamic objects and address unnatural motion occlusions. We show the superior performance of our method through extensive experiments on real-world datasets. Moreover, our approach achieves state-of-the-art performance in both unsupervised and supervised training of learning-based models. The code will be made publicly available at: \url{//github.com/Sharpiless/MPI-Flow}.
Machine learning in medical imaging often faces a fundamental dilemma, namely the small sample size problem. Many recent studies suggest using multi-domain data pooled from different acquisition sites/datasets to improve statistical power. However, medical images from different sites cannot be easily shared to build large datasets for model training due to privacy protection reasons. As a promising solution, federated learning, which enables collaborative training of machine learning models based on data from different sites without cross-site data sharing, has attracted considerable attention recently. In this paper, we conduct a comprehensive survey of the recent development of federated learning methods in medical image analysis. We first introduce the background and motivation of federated learning for dealing with privacy protection and collaborative learning issues in medical imaging. We then present a comprehensive review of recent advances in federated learning methods for medical image analysis. Specifically, existing methods are categorized based on three critical aspects of a federated learning system, including client end, server end, and communication techniques. In each category, we summarize the existing federated learning methods according to specific research problems in medical image analysis and also provide insights into the motivations of different approaches. In addition, we provide a review of existing benchmark medical imaging datasets and software platforms for current federated learning research. We also conduct an experimental study to empirically evaluate typical federated learning methods for medical image analysis. This survey can help to better understand the current research status, challenges and potential research opportunities in this promising research field.
Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
The incredible development of federated learning (FL) has benefited various tasks in the domains of computer vision and natural language processing, and the existing frameworks such as TFF and FATE has made the deployment easy in real-world applications. However, federated graph learning (FGL), even though graph data are prevalent, has not been well supported due to its unique characteristics and requirements. The lack of FGL-related framework increases the efforts for accomplishing reproducible research and deploying in real-world applications. Motivated by such strong demand, in this paper, we first discuss the challenges in creating an easy-to-use FGL package and accordingly present our implemented package FederatedScope-GNN (FS-G), which provides (1) a unified view for modularizing and expressing FGL algorithms; (2) comprehensive DataZoo and ModelZoo for out-of-the-box FGL capability; (3) an efficient model auto-tuning component; and (4) off-the-shelf privacy attack and defense abilities. We validate the effectiveness of FS-G by conducting extensive experiments, which simultaneously gains many valuable insights about FGL for the community. Moreover, we employ FS-G to serve the FGL application in real-world E-commerce scenarios, where the attained improvements indicate great potential business benefits. We publicly release FS-G, as submodules of FederatedScope, at //github.com/alibaba/FederatedScope to promote FGL's research and enable broad applications that would otherwise be infeasible due to the lack of a dedicated package.
As an effective strategy, data augmentation (DA) alleviates data scarcity scenarios where deep learning techniques may fail. It is widely applied in computer vision then introduced to natural language processing and achieves improvements in many tasks. One of the main focuses of the DA methods is to improve the diversity of training data, thereby helping the model to better generalize to unseen testing data. In this survey, we frame DA methods into three categories based on the diversity of augmented data, including paraphrasing, noising, and sampling. Our paper sets out to analyze DA methods in detail according to the above categories. Further, we also introduce their applications in NLP tasks as well as the challenges.
Deep learning has become the dominant approach in coping with various tasks in Natural LanguageProcessing (NLP). Although text inputs are typically represented as a sequence of tokens, there isa rich variety of NLP problems that can be best expressed with a graph structure. As a result, thereis a surge of interests in developing new deep learning techniques on graphs for a large numberof NLP tasks. In this survey, we present a comprehensive overview onGraph Neural Networks(GNNs) for Natural Language Processing. We propose a new taxonomy of GNNs for NLP, whichsystematically organizes existing research of GNNs for NLP along three axes: graph construction,graph representation learning, and graph based encoder-decoder models. We further introducea large number of NLP applications that are exploiting the power of GNNs and summarize thecorresponding benchmark datasets, evaluation metrics, and open-source codes. Finally, we discussvarious outstanding challenges for making the full use of GNNs for NLP as well as future researchdirections. To the best of our knowledge, this is the first comprehensive overview of Graph NeuralNetworks for Natural Language Processing.
Multiple instance learning (MIL) is a powerful tool to solve the weakly supervised classification in whole slide image (WSI) based pathology diagnosis. However, the current MIL methods are usually based on independent and identical distribution hypothesis, thus neglect the correlation among different instances. To address this problem, we proposed a new framework, called correlated MIL, and provided a proof for convergence. Based on this framework, we devised a Transformer based MIL (TransMIL), which explored both morphological and spatial information. The proposed TransMIL can effectively deal with unbalanced/balanced and binary/multiple classification with great visualization and interpretability. We conducted various experiments for three different computational pathology problems and achieved better performance and faster convergence compared with state-of-the-art methods. The test AUC for the binary tumor classification can be up to 93.09% over CAMELYON16 dataset. And the AUC over the cancer subtypes classification can be up to 96.03% and 98.82% over TCGA-NSCLC dataset and TCGA-RCC dataset, respectively.
The potential of graph convolutional neural networks for the task of zero-shot learning has been demonstrated recently. These models are highly sample efficient as related concepts in the graph structure share statistical strength allowing generalization to new classes when faced with a lack of data. However, knowledge from distant nodes can get diluted when propagating through intermediate nodes, because current approaches to zero-shot learning use graph propagation schemes that perform Laplacian smoothing at each layer. We show that extensive smoothing does not help the task of regressing classifier weights in zero-shot learning. In order to still incorporate information from distant nodes and utilize the graph structure, we propose an Attentive Dense Graph Propagation Module (ADGPM). ADGPM allows us to exploit the hierarchical graph structure of the knowledge graph through additional connections. These connections are added based on a node's relationship to its ancestors and descendants and an attention scheme is further used to weigh their contribution depending on the distance to the node. Finally, we illustrate that finetuning of the feature representation after training the ADGPM leads to considerable improvements. Our method achieves competitive results, outperforming previous zero-shot learning approaches.
Distant supervision can effectively label data for relation extraction, but suffers from the noise labeling problem. Recent works mainly perform soft bag-level noise reduction strategies to find the relatively better samples in a sentence bag, which is suboptimal compared with making a hard decision of false positive samples in sentence level. In this paper, we introduce an adversarial learning framework, which we named DSGAN, to learn a sentence-level true-positive generator. Inspired by Generative Adversarial Networks, we regard the positive samples generated by the generator as the negative samples to train the discriminator. The optimal generator is obtained until the discrimination ability of the discriminator has the greatest decline. We adopt the generator to filter distant supervision training dataset and redistribute the false positive instances into the negative set, in which way to provide a cleaned dataset for relation classification. The experimental results show that the proposed strategy significantly improves the performance of distant supervision relation extraction comparing to state-of-the-art systems.
小貼士
登錄享
相關主題
注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191