
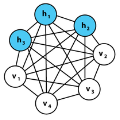

Generative models offer a direct way of modeling complex data. Energy-based models attempt to encode the statistical correlations observed in the data at the level of the Boltzmann weight associated with an energy function in the form of a neural network. We address here the challenge of understanding the physical interpretation of such models. In this study, we propose a simple solution by implementing a direct mapping between the Restricted Boltzmann Machine and an effective Ising spin Hamiltonian. This mapping includes interactions of all possible orders, going beyond the conventional pairwise interactions typically considered in the inverse Ising (or Boltzmann Machine) approach, and allowing the description of complex datasets. Earlier works attempted to achieve this goal, but the proposed mappings were inaccurate for inference applications, did not properly treat the complexity of the problem, or did not provide precise prescriptions for practical application. To validate our method, we performed several controlled inverse numerical experiments in which we trained the RBMs using equilibrium samples of predefined models with local external fields, 2-body and 3-body interactions in different sparse topologies. The results demonstrate the effectiveness of our proposed approach in learning the correct interaction network and pave the way for its application in modeling interesting binary variable datasets. We also evaluate the quality of the inferred model based on different training methods.
相關內容
Robust Markov Decision Processes (RMDPs) are a widely used framework for sequential decision-making under parameter uncertainty. RMDPs have been extensively studied when the objective is to maximize the discounted return, but little is known for average optimality (optimizing the long-run average of the rewards obtained over time) and Blackwell optimality (remaining discount optimal for all discount factors sufficiently close to 1). In this paper, we prove several foundational results for RMDPs beyond the discounted return. We show that average optimal policies can be chosen stationary and deterministic for sa-rectangular RMDPs but, perhaps surprisingly, that history-dependent (Markovian) policies strictly outperform stationary policies for average optimality in s-rectangular RMDPs. We also study Blackwell optimality for sa-rectangular RMDPs, where we show that {\em approximate} Blackwell optimal policies always exist, although Blackwell optimal policies may not exist. We also provide a sufficient condition for their existence, which encompasses virtually any examples from the literature. We then discuss the connection between average and Blackwell optimality, and we describe several algorithms to compute the optimal average return. Interestingly, our approach leverages the connections between RMDPs and stochastic games.
Amidst task-specific learning-based control synthesis frameworks that achieve impressive empirical results, a unified framework that systematically constructs an optimal policy for sufficiently solving a general notion of a task is absent. Hence, we propose a theoretical framework for a task-centered control synthesis leveraging two critical ideas: 1) oracle-guided policy optimization for the non-limiting integration of sub-optimal task-based priors to guide the policy optimization and 2) task-vital multimodality to break down solving a task into executing a sequence of behavioral modes. The proposed approach results in highly agile parkour and diving on a 16-DoF dynamic bipedal robot. The obtained policy advances indefinitely on a track, performing leaps and jumps of varying lengths and heights for the parkour task. Corresponding to the dive task, the policy demonstrates front, back, and side flips from various initial heights. Finally, we introduce a novel latent mode space reachability analysis to study our policies' versatility and generalization by computing a feasible mode set function through which we certify a set of failure-free modes for our policy to perform at any given state.
Accurate modeling of the diverse and dynamic interests of users remains a significant challenge in the design of personalized recommender systems. Existing user modeling methods, like single-point and multi-point representations, have limitations w.r.t. accuracy, diversity, computational cost, and adaptability. To overcome these deficiencies, we introduce density-based user representations (DURs), a novel model that leverages Gaussian process regression for effective multi-interest recommendation and retrieval. Our approach, GPR4DUR, exploits DURs to capture user interest variability without manual tuning, incorporates uncertainty-awareness, and scales well to large numbers of users. Experiments using real-world offline datasets confirm the adaptability and efficiency of GPR4DUR, while online experiments with simulated users demonstrate its ability to address the exploration-exploitation trade-off by effectively utilizing model uncertainty.
Topic models are a popular tool for clustering and analyzing textual data. They allow texts to be classified on the basis of their affiliation to the previously calculated topics. Despite their widespread use in research and application, an in-depth analysis of topic models is still an open research topic. State-of-the-art methods for interpreting topic models are based on simple visualizations, such as similarity matrices, top-term lists or embeddings, which are limited to a maximum of three dimensions. In this paper, we propose an incidence-geometric method for deriving an ordinal structure from flat topic models, such as non-negative matrix factorization. These enable the analysis of the topic model in a higher (order) dimension and the possibility of extracting conceptual relationships between several topics at once. Due to the use of conceptual scaling, our approach does not introduce any artificial topical relationships, such as artifacts of feature compression. Based on our findings, we present a new visualization paradigm for concept hierarchies based on ordinal motifs. These allow for a top-down view on topic spaces. We introduce and demonstrate the applicability of our approach based on a topic model derived from a corpus of scientific papers taken from 32 top machine learning venues.
Foundational models benefit from pre-training on large amounts of unlabeled data and enable strong performance in a wide variety of applications with a small amount of labeled data. Such models can be particularly effective in analyzing brain signals, as this field encompasses numerous application scenarios, and it is costly to perform large-scale annotation. In this work, we present the largest foundation model in brain signals, Brant-2. Compared to Brant, a foundation model designed for intracranial neural signals, Brant-2 not only exhibits robustness towards data variations and modeling scales but also can be applied to a broader range of brain neural data. By experimenting on an extensive range of tasks, we demonstrate that Brant-2 is adaptive to various application scenarios in brain signals. Further analyses reveal the scalability of the Brant-2, validate each component's effectiveness, and showcase our model's ability to maintain performance in scenarios with scarce labels. The source code and pre-trained weights are available at: //github.com/yzz673/Brant-2.
Sequential design of experiments for optimizing a reward function in causal systems can be effectively modeled by the sequential design of interventions in causal bandits (CBs). In the existing literature on CBs, a critical assumption is that the causal models remain constant over time. However, this assumption does not necessarily hold in complex systems, which constantly undergo temporal model fluctuations. This paper addresses the robustness of CBs to such model fluctuations. The focus is on causal systems with linear structural equation models (SEMs). The SEMs and the time-varying pre- and post-interventional statistical models are all unknown. Cumulative regret is adopted as the design criteria, based on which the objective is to design a sequence of interventions that incur the smallest cumulative regret with respect to an oracle aware of the entire causal model and its fluctuations. First, it is established that the existing approaches fail to maintain regret sub-linearity with even a few instances of model deviation. Specifically, when the number of instances with model deviation is as few as $T^\frac{1}{2L}$, where $T$ is the time horizon and $L$ is the longest causal path in the graph, the existing algorithms will have linear regret in $T$. Next, a robust CB algorithm is designed, and its regret is analyzed, where upper and information-theoretic lower bounds on the regret are established. Specifically, in a graph with $N$ nodes and maximum degree $d$, under a general measure of model deviation $C$, the cumulative regret is upper bounded by $\tilde{\mathcal{O}}(d^{L-\frac{1}{2}}(\sqrt{NT} + NC))$ and lower bounded by $\Omega(d^{\frac{L}{2}-2}\max\{\sqrt{T},d^2C\})$. Comparing these bounds establishes that the proposed algorithm achieves nearly optimal $\tilde{\mathcal{O}}(\sqrt{T})$ regret when $C$ is $o(\sqrt{T})$ and maintains sub-linear regret for a broader range of $C$.
Addressing the intricate challenge of modeling and re-rendering dynamic scenes, most recent approaches have sought to simplify these complexities using plane-based explicit representations, overcoming the slow training time issues associated with methods like Neural Radiance Fields (NeRF) and implicit representations. However, the straightforward decomposition of 4D dynamic scenes into multiple 2D plane-based representations proves insufficient for re-rendering high-fidelity scenes with complex motions. In response, we present a novel direction-aware representation (DaRe) approach that captures scene dynamics from six different directions. This learned representation undergoes an inverse dual-tree complex wavelet transformation (DTCWT) to recover plane-based information. DaReNeRF computes features for each space-time point by fusing vectors from these recovered planes. Combining DaReNeRF with a tiny MLP for color regression and leveraging volume rendering in training yield state-of-the-art performance in novel view synthesis for complex dynamic scenes. Notably, to address redundancy introduced by the six real and six imaginary direction-aware wavelet coefficients, we introduce a trainable masking approach, mitigating storage issues without significant performance decline. Moreover, DaReNeRF maintains a 2x reduction in training time compared to prior art while delivering superior performance.
Information retrieval models have witnessed a paradigm shift from unsupervised statistical approaches to feature-based supervised approaches to completely data-driven ones that make use of the pre-training of large language models. While the increasing complexity of the search models have been able to demonstrate improvements in effectiveness (measured in terms of relevance of top-retrieved results), a question worthy of a thorough inspection is - "how explainable are these models?", which is what this paper aims to evaluate. In particular, we propose a common evaluation platform to systematically evaluate the explainability of any ranking model (the explanation algorithm being identical for all the models that are to be evaluated). In our proposed framework, each model, in addition to returning a ranked list of documents, also requires to return a list of explanation units or rationales for each document. This meta-information from each document is then used to measure how locally consistent these rationales are as an intrinsic measure of interpretability - one that does not require manual relevance assessments. Additionally, as an extrinsic measure, we compute how relevant these rationales are by leveraging sub-document level relevance assessments. Our findings show a number of interesting observations, such as sentence-level rationales are more consistent, an increase in complexity mostly leads to less consistent explanations, and that interpretability measures offer a complementary dimension of evaluation of IR systems because consistency is not well-correlated with nDCG at top ranks.
Foundation models pretrained on large-scale datasets via self-supervised learning demonstrate exceptional versatility across various tasks. Due to the heterogeneity and hard-to-collect medical data, this approach is especially beneficial for medical image analysis and neuroscience research, as it streamlines broad downstream tasks without the need for numerous costly annotations. However, there has been limited investigation into brain network foundation models, limiting their adaptability and generalizability for broad neuroscience studies. In this study, we aim to bridge this gap. In particular, (1) we curated a comprehensive dataset by collating images from 30 datasets, which comprises 70,781 samples of 46,686 participants. Moreover, we introduce pseudo-functional connectivity (pFC) to further generates millions of augmented brain networks by randomly dropping certain timepoints of the BOLD signal. (2) We propose the BrainMass framework for brain network self-supervised learning via mask modeling and feature alignment. BrainMass employs Mask-ROI Modeling (MRM) to bolster intra-network dependencies and regional specificity. Furthermore, Latent Representation Alignment (LRA) module is utilized to regularize augmented brain networks of the same participant with similar topological properties to yield similar latent representations by aligning their latent embeddings. Extensive experiments on eight internal tasks and seven external brain disorder diagnosis tasks show BrainMass's superior performance, highlighting its significant generalizability and adaptability. Nonetheless, BrainMass demonstrates powerful few/zero-shot learning abilities and exhibits meaningful interpretation to various diseases, showcasing its potential use for clinical applications.
Diffusion models have emerged as a prominent class of generative models, surpassing previous methods regarding sample quality and training stability. Recent works have shown the advantages of diffusion models in improving reinforcement learning (RL) solutions, including as trajectory planners, expressive policy classes, data synthesizers, etc. This survey aims to provide an overview of the advancements in this emerging field and hopes to inspire new avenues of research. First, we examine several challenges encountered by current RL algorithms. Then, we present a taxonomy of existing methods based on the roles played by diffusion models in RL and explore how the existing challenges are addressed. We further outline successful applications of diffusion models in various RL-related tasks while discussing the limitations of current approaches. Finally, we conclude the survey and offer insights into future research directions, focusing on enhancing model performance and applying diffusion models to broader tasks. We are actively maintaining a GitHub repository for papers and other related resources in applying diffusion models in RL: //github.com/apexrl/Diff4RLSurvey .




注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191