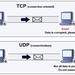

We show how to establish TLS connections using one less round trip. In our approach, which we call TurboTLS, the initial client-to-server and server-to-client flows of the TLS handshake are sent over UDP rather than TCP. At the same time, in the same flights, the three-way TCP handshake is carried out. Once the TCP connection is established, the client and server can complete the final flight of the TLS handshake over the TCP connection and continue using it for application data. No changes are made to the contents of the TLS handshake protocol, only its delivery mechanism. We avoid problems with UDP fragmentation by using request-based fragmentation, in which the client sends in advance enough UDP requests to provide sufficient room for the server to fit its response with one response packet per request packet. Clients can detect which servers support this without an additional round trip, if the server advertises its support in a DNS HTTPS resource record. Experiments using our software implementation show substantial latency improvements. On reliable connections, we effectively eliminate a round trip without any noticeable cost. To ensure adequate performance on unreliable connections, we use lightweight packet ordering and buffering; we can have a client wait a very small time to receive a potentially lost packet (e.g., a fraction of the RTT observed for the first fragment) before falling back to TCP without any further delay, since the TCP connection was already in the process of being established. This approach offers substantial performance improvements with low complexity, even in heterogeneous network environments with poorly configured middleboxes.
相關內容
A block Markov chain is a Markov chain whose state space can be partitioned into a finite number of clusters such that the transition probabilities only depend on the clusters. Block Markov chains thus serve as a model for Markov chains with communities. This paper establishes limiting laws for the singular value distributions of the empirical transition matrix and empirical frequency matrix associated to a sample path of the block Markov chain whenever the length of the sample path is $\Theta(n^2)$ with $n$ the size of the state space. The proof approach is split into two parts. First, we introduce a class of symmetric random matrices with dependent entries called approximately uncorrelated random matrices with variance profile. We establish their limiting eigenvalue distributions by means of the moment method. Second, we develop a coupling argument to show that this general-purpose result applies to the singular value distributions associated with the block Markov chain.
This paper describes a purely functional library for computing level-$p$-complexity of Boolean functions, and applies it to two-level iterated majority. Boolean functions are simply functions from $n$ bits to one bit, and they can describe digital circuits, voting systems, etc. An example of a Boolean function is majority, which returns the value that has majority among the $n$ input bits for odd $n$. The complexity of a Boolean function $f$ measures the cost of evaluating it: how many bits of the input are needed to be certain about the result of $f$. There are many competing complexity measures but we focus on level-$p$-complexity -- a function of the probability $p$ that a bit is 1. The level-$p$-complexity $D_p(f)$ is the minimum expected cost when the input bits are independent and identically distributed with Bernoulli($p$) distribution. We specify the problem as choosing the minimum expected cost of all possible decision trees -- which directly translates to a clearly correct, but very inefficient implementation. The library uses thinning and memoization for efficiency and type classes for separation of concerns. The complexity is represented using polynomials, and the order relation used for thinning is implemented using polynomial factorisation and root-counting. Finally we compute the complexity for two-level iterated majority and improve on an earlier result by J.~Jansson.
In many real world situations, like minor traffic offenses in big cities, a central authority is tasked with periodic administering punishments to a large number of individuals. Common practice is to give each individual a chance to suffer a smaller fine and be guaranteed to avoid the legal process with probable considerably larger punishment. However, thanks to the large number of offenders and a limited capacity of the central authority, the individual risk is typically small and a rational individual will not choose to pay the fine. Here we show that if the central authority processes the offenders in a publicly known order, it properly incentives the offenders to pay the fine. We show analytically and on realistic experiments that our mechanism promotes non-cooperation and incentives individuals to pay. Moreover, the same holds for an arbitrary coalition. We quantify the expected total payment the central authority receives, and show it increases considerably.
Over the past few years, the rapid development of deep learning technologies for computer vision has greatly promoted the performance of medical image segmentation (MedISeg). However, the recent MedISeg publications usually focus on presentations of the major contributions (e.g., network architectures, training strategies, and loss functions) while unwittingly ignoring some marginal implementation details (also known as "tricks"), leading to a potential problem of the unfair experimental result comparisons. In this paper, we collect a series of MedISeg tricks for different model implementation phases (i.e., pre-training model, data pre-processing, data augmentation, model implementation, model inference, and result post-processing), and experimentally explore the effectiveness of these tricks on the consistent baseline models. Compared to paper-driven surveys that only blandly focus on the advantages and limitation analyses of segmentation models, our work provides a large number of solid experiments and is more technically operable. With the extensive experimental results on both the representative 2D and 3D medical image datasets, we explicitly clarify the effect of these tricks. Moreover, based on the surveyed tricks, we also open-sourced a strong MedISeg repository, where each of its components has the advantage of plug-and-play. We believe that this milestone work not only completes a comprehensive and complementary survey of the state-of-the-art MedISeg approaches, but also offers a practical guide for addressing the future medical image processing challenges including but not limited to small dataset learning, class imbalance learning, multi-modality learning, and domain adaptation. The code has been released at: //github.com/hust-linyi/MedISeg
Multimodal learning helps to comprehensively understand the world, by integrating different senses. Accordingly, multiple input modalities are expected to boost model performance, but we actually find that they are not fully exploited even when the multimodal model outperforms its uni-modal counterpart. Specifically, in this paper we point out that existing multimodal discriminative models, in which uniform objective is designed for all modalities, could remain under-optimized uni-modal representations, caused by another dominated modality in some scenarios, e.g., sound in blowing wind event, vision in drawing picture event, etc. To alleviate this optimization imbalance, we propose on-the-fly gradient modulation to adaptively control the optimization of each modality, via monitoring the discrepancy of their contribution towards the learning objective. Further, an extra Gaussian noise that changes dynamically is introduced to avoid possible generalization drop caused by gradient modulation. As a result, we achieve considerable improvement over common fusion methods on different multimodal tasks, and this simple strategy can also boost existing multimodal methods, which illustrates its efficacy and versatility. The source code is available at \url{//github.com/GeWu-Lab/OGM-GE_CVPR2022}.
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.
Unsupervised domain adaptation (UDA) methods for person re-identification (re-ID) aim at transferring re-ID knowledge from labeled source data to unlabeled target data. Although achieving great success, most of them only use limited data from a single-source domain for model pre-training, making the rich labeled data insufficiently exploited. To make full use of the valuable labeled data, we introduce the multi-source concept into UDA person re-ID field, where multiple source datasets are used during training. However, because of domain gaps, simply combining different datasets only brings limited improvement. In this paper, we try to address this problem from two perspectives, \ie{} domain-specific view and domain-fusion view. Two constructive modules are proposed, and they are compatible with each other. First, a rectification domain-specific batch normalization (RDSBN) module is explored to simultaneously reduce domain-specific characteristics and increase the distinctiveness of person features. Second, a graph convolutional network (GCN) based multi-domain information fusion (MDIF) module is developed, which minimizes domain distances by fusing features of different domains. The proposed method outperforms state-of-the-art UDA person re-ID methods by a large margin, and even achieves comparable performance to the supervised approaches without any post-processing techniques.
With the rapid increase of large-scale, real-world datasets, it becomes critical to address the problem of long-tailed data distribution (i.e., a few classes account for most of the data, while most classes are under-represented). Existing solutions typically adopt class re-balancing strategies such as re-sampling and re-weighting based on the number of observations for each class. In this work, we argue that as the number of samples increases, the additional benefit of a newly added data point will diminish. We introduce a novel theoretical framework to measure data overlap by associating with each sample a small neighboring region rather than a single point. The effective number of samples is defined as the volume of samples and can be calculated by a simple formula $(1-\beta^{n})/(1-\beta)$, where $n$ is the number of samples and $\beta \in [0,1)$ is a hyperparameter. We design a re-weighting scheme that uses the effective number of samples for each class to re-balance the loss, thereby yielding a class-balanced loss. Comprehensive experiments are conducted on artificially induced long-tailed CIFAR datasets and large-scale datasets including ImageNet and iNaturalist. Our results show that when trained with the proposed class-balanced loss, the network is able to achieve significant performance gains on long-tailed datasets.

Recent advances in 3D fully convolutional networks (FCN) have made it feasible to produce dense voxel-wise predictions of volumetric images. In this work, we show that a multi-class 3D FCN trained on manually labeled CT scans of several anatomical structures (ranging from the large organs to thin vessels) can achieve competitive segmentation results, while avoiding the need for handcrafting features or training class-specific models. To this end, we propose a two-stage, coarse-to-fine approach that will first use a 3D FCN to roughly define a candidate region, which will then be used as input to a second 3D FCN. This reduces the number of voxels the second FCN has to classify to ~10% and allows it to focus on more detailed segmentation of the organs and vessels. We utilize training and validation sets consisting of 331 clinical CT images and test our models on a completely unseen data collection acquired at a different hospital that includes 150 CT scans, targeting three anatomical organs (liver, spleen, and pancreas). In challenging organs such as the pancreas, our cascaded approach improves the mean Dice score from 68.5 to 82.2%, achieving the highest reported average score on this dataset. We compare with a 2D FCN method on a separate dataset of 240 CT scans with 18 classes and achieve a significantly higher performance in small organs and vessels. Furthermore, we explore fine-tuning our models to different datasets. Our experiments illustrate the promise and robustness of current 3D FCN based semantic segmentation of medical images, achieving state-of-the-art results. Our code and trained models are available for download: //github.com/holgerroth/3Dunet_abdomen_cascade.
Image segmentation is considered to be one of the critical tasks in hyperspectral remote sensing image processing. Recently, convolutional neural network (CNN) has established itself as a powerful model in segmentation and classification by demonstrating excellent performances. The use of a graphical model such as a conditional random field (CRF) contributes further in capturing contextual information and thus improving the segmentation performance. In this paper, we propose a method to segment hyperspectral images by considering both spectral and spatial information via a combined framework consisting of CNN and CRF. We use multiple spectral cubes to learn deep features using CNN, and then formulate deep CRF with CNN-based unary and pairwise potential functions to effectively extract the semantic correlations between patches consisting of three-dimensional data cubes. Effective piecewise training is applied in order to avoid the computationally expensive iterative CRF inference. Furthermore, we introduce a deep deconvolution network that improves the segmentation masks. We also introduce a new dataset and experimented our proposed method on it along with several widely adopted benchmark datasets to evaluate the effectiveness of our method. By comparing our results with those from several state-of-the-art models, we show the promising potential of our method.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191