


Score-based diffusion models learn to reverse a stochastic differential equation that maps data to noise. However, for complex tasks, numerical error can compound and result in highly unnatural samples. Previous work mitigates this drift with thresholding, which projects to the natural data domain (such as pixel space for images) after each diffusion step, but this leads to a mismatch between the training and generative processes. To incorporate data constraints in a principled manner, we present Reflected Diffusion Models, which instead reverse a reflected stochastic differential equation evolving on the support of the data. Our approach learns the perturbed score function through a generalize score matching loss and extends key components of standard diffusion models including diffusion guidance, likelihood-based training, and ODE sampling. We also bridge the theoretical gap with thresholding: such schemes are just discretizations of reflected SDEs. On standard image benchmarks, our method is competitive with or surpasses the state of the art and, for classifier-free guidance, our approach enables fast exact sampling with ODEs and produces more faithful samples under high guidance weight.
相關內容
There have been wide spread claims in the literature about the emergent reasoning capabilities of Pretrained Large Language Models. However, recent studies, have found that their ability to plan remains questionable. Through our experiments using GPT-2, we empirically demonstrate that the performance of a finetuned baseline remains poor because it violates pre-conditions of actions in the plans that it generates. To improve the planning capabilities of a finetuned LLM, we train a verifier, which can classify actions as being valid or invalid in a particular state. By randomly sampling actions from the same dataset, we generate examples of invalid actions which are then used to train a verifier which can check for action applicability. In the presence of diverse sampling from a generator and a verifier which can prune invalid trajectories, we show significant gains in the success rate on the Blocksworld domain. Additionally, we show that finetuning the GPT-2 generator itself to create the verifier generalizes better than finetuning the base GPT-2. Lastly, we investigate the role of the sampling temperature which can be used to control the exploration-exploitation tradeoff.
Levin Tree Search (LTS) is a search algorithm that makes use of a policy (a probability distribution over actions) and comes with a theoretical guarantee on the number of expansions before reaching a goal node, depending on the quality of the policy. This guarantee can be used as a loss function, which we call the LTS loss, to optimize neural networks representing the policy (LTS+NN). In this work we show that the neural network can be substituted with parameterized context models originating from the online compression literature (LTS+CM). We show that the LTS loss is convex under this new model, which allows for using standard convex optimization tools, and obtain convergence guarantees to the optimal parameters in an online setting for a given set of solution trajectories -- guarantees that cannot be provided for neural networks. The new LTS+CM algorithm compares favorably against LTS+NN on several benchmarks: Sokoban (Boxoban), The Witness, and the 24-Sliding Tile puzzle (STP). The difference is particularly large on STP, where LTS+NN fails to solve most of the test instances while LTS+CM solves each test instance in a fraction of a second. Furthermore, we show that LTS+CM is able to learn a policy that solves the Rubik's cube in only a few hundred expansions, which considerably improves upon previous machine learning techniques.
Denoising Diffusion Probabilistic Models (DDPM) have shown remarkable efficacy in the synthesis of high-quality images. However, their inference process characteristically requires numerous, potentially hundreds, of iterative steps, which could lead to the problem of exposure bias due to the accumulation of prediction errors over iterations. Previous work has attempted to mitigate this issue by perturbing inputs during training, which consequently mandates the retraining of the DDPM. In this work, we conduct a systematic study of exposure bias in diffusion models and, intriguingly, we find that the exposure bias could be alleviated with a new sampling method, without retraining the model. We empirically and theoretically show that, during inference, for each backward time step $t$ and corresponding state $\hat{x}_t$, there might exist another time step $t_s$ which exhibits superior coupling with $\hat{x}_t$. Based on this finding, we introduce an inference method named Time-Shift Sampler. Our framework can be seamlessly integrated with existing sampling algorithms, such as DDIM or DDPM, inducing merely minimal additional computations. Experimental results show that our proposed framework can effectively enhance the quality of images generated by existing sampling algorithms.
Text-to-image (T2I) research has grown explosively in the past year, owing to the large-scale pre-trained diffusion models and many emerging personalization and editing approaches. Yet, one pain point persists: the text prompt engineering, and searching high-quality text prompts for customized results is more art than science. Moreover, as commonly argued: "an image is worth a thousand words" - the attempt to describe a desired image with texts often ends up being ambiguous and cannot comprehensively cover delicate visual details, hence necessitating more additional controls from the visual domain. In this paper, we take a bold step forward: taking "Text" out of a pre-trained T2I diffusion model, to reduce the burdensome prompt engineering efforts for users. Our proposed framework, Prompt-Free Diffusion, relies on only visual inputs to generate new images: it takes a reference image as "context", an optional image structural conditioning, and an initial noise, with absolutely no text prompt. The core architecture behind the scene is Semantic Context Encoder (SeeCoder), substituting the commonly used CLIP-based or LLM-based text encoder. The reusability of SeeCoder also makes it a convenient drop-in component: one can also pre-train a SeeCoder in one T2I model and reuse it for another. Through extensive experiments, Prompt-Free Diffusion is experimentally found to (i) outperform prior exemplar-based image synthesis approaches; (ii) perform on par with state-of-the-art T2I models using prompts following the best practice; and (iii) be naturally extensible to other downstream applications such as anime figure generation and virtual try-on, with promising quality. Our code and models are open-sourced at //github.com/SHI-Labs/Prompt-Free-Diffusion.
Particle-based deep generative models, such as gradient flows and score-based diffusion models, have recently gained traction thanks to their striking performance. Their principle of displacing particle distributions by differential equations is conventionally seen as opposed to the previously widespread generative adversarial networks (GANs), which involve training a pushforward generator network. In this paper, we challenge this interpretation and propose a novel framework that unifies particle and adversarial generative models by framing generator training as a generalization of particle models. This suggests that a generator is an optional addition to any such generative model. Consequently, integrating a generator into a score-based diffusion model and training a GAN without a generator naturally emerge from our framework. We empirically test the viability of these original models as proofs of concepts of potential applications of our framework.
Cooperative multi-agent reinforcement learning (MARL) is a challenging task, as agents must learn complex and diverse individual strategies from a shared team reward. However, existing methods struggle to distinguish and exploit important individual experiences, as they lack an effective way to decompose the team reward into individual rewards. To address this challenge, we propose DIFFER, a powerful theoretical framework for decomposing individual rewards to enable fair experience replay in MARL. By enforcing the invariance of network gradients, we establish a partial differential equation whose solution yields the underlying individual reward function. The individual TD-error can then be computed from the solved closed-form individual rewards, indicating the importance of each piece of experience in the learning task and guiding the training process. Our method elegantly achieves an equivalence to the original learning framework when individual experiences are homogeneous, while also adapting to achieve more muscular efficiency and fairness when diversity is observed.Our extensive experiments on popular benchmarks validate the effectiveness of our theory and method, demonstrating significant improvements in learning efficiency and fairness.
Solving ill-posed inverse problems requires careful formulation of prior beliefs over the signals of interest and an accurate description of their manifestation into noisy measurements. Handcrafted signal priors based on e.g. sparsity are increasingly replaced by data-driven deep generative models, and several groups have recently shown that state-of-the-art score-based diffusion models yield particularly strong performance and flexibility. In this paper, we show that the powerful paradigm of posterior sampling with diffusion models can be extended to include rich, structured, noise models. To that end, we propose a joint conditional reverse diffusion process with learned scores for the noise and signal-generating distribution. We demonstrate strong performance gains across various inverse problems with structured noise, outperforming competitive baselines that use normalizing flows and adversarial networks. This opens up new opportunities and relevant practical applications of diffusion modeling for inverse problems in the context of non-Gaussian measurement models.
Denoising diffusion models represent a recent emerging topic in computer vision, demonstrating remarkable results in the area of generative modeling. A diffusion model is a deep generative model that is based on two stages, a forward diffusion stage and a reverse diffusion stage. In the forward diffusion stage, the input data is gradually perturbed over several steps by adding Gaussian noise. In the reverse stage, a model is tasked at recovering the original input data by learning to gradually reverse the diffusion process, step by step. Diffusion models are widely appreciated for the quality and diversity of the generated samples, despite their known computational burdens, i.e. low speeds due to the high number of steps involved during sampling. In this survey, we provide a comprehensive review of articles on denoising diffusion models applied in vision, comprising both theoretical and practical contributions in the field. First, we identify and present three generic diffusion modeling frameworks, which are based on denoising diffusion probabilistic models, noise conditioned score networks, and stochastic differential equations. We further discuss the relations between diffusion models and other deep generative models, including variational auto-encoders, generative adversarial networks, energy-based models, autoregressive models and normalizing flows. Then, we introduce a multi-perspective categorization of diffusion models applied in computer vision. Finally, we illustrate the current limitations of diffusion models and envision some interesting directions for future research.
Diffusion models have shown incredible capabilities as generative models; indeed, they power the current state-of-the-art models on text-conditioned image generation such as Imagen and DALL-E 2. In this work we review, demystify, and unify the understanding of diffusion models across both variational and score-based perspectives. We first derive Variational Diffusion Models (VDM) as a special case of a Markovian Hierarchical Variational Autoencoder, where three key assumptions enable tractable computation and scalable optimization of the ELBO. We then prove that optimizing a VDM boils down to learning a neural network to predict one of three potential objectives: the original source input from any arbitrary noisification of it, the original source noise from any arbitrarily noisified input, or the score function of a noisified input at any arbitrary noise level. We then dive deeper into what it means to learn the score function, and connect the variational perspective of a diffusion model explicitly with the Score-based Generative Modeling perspective through Tweedie's Formula. Lastly, we cover how to learn a conditional distribution using diffusion models via guidance.
Residual networks (ResNets) have displayed impressive results in pattern recognition and, recently, have garnered considerable theoretical interest due to a perceived link with neural ordinary differential equations (neural ODEs). This link relies on the convergence of network weights to a smooth function as the number of layers increases. We investigate the properties of weights trained by stochastic gradient descent and their scaling with network depth through detailed numerical experiments. We observe the existence of scaling regimes markedly different from those assumed in neural ODE literature. Depending on certain features of the network architecture, such as the smoothness of the activation function, one may obtain an alternative ODE limit, a stochastic differential equation or neither of these. These findings cast doubts on the validity of the neural ODE model as an adequate asymptotic description of deep ResNets and point to an alternative class of differential equations as a better description of the deep network limit.
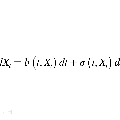

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191