

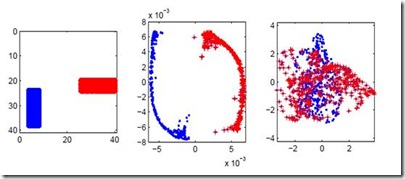
We propose a method to detect outliers in empirically observed trajectories on a discrete or discretized manifold modeled by a simplicial complex. Our approach is similar to spectral embeddings such as diffusion-maps and Laplacian eigenmaps, that construct vertex embeddings from the eigenvectors of the graph Laplacian associated with low eigenvalues. Here we consider trajectories as edge-flow vectors defined on a simplicial complex, a higher-order generalization of graphs, and use the Hodge 1-Laplacian of the simplicial complex to derive embeddings of these edge-flows. By projecting trajectory vectors onto the eigenspace of the Hodge 1-Laplacian associated to small eigenvalues, we can characterize the behavior of the trajectories relative to the homology of the complex, which corresponds to holes in the underlying space. This enables us to classify trajectories based on simply interpretable, low-dimensional statistics. We show how this technique can single out trajectories that behave (topologically) different compared to typical trajectories, and illustrate the performance of our approach with both synthetic and empirical data.
相關內容
This paper presents DRE-CUSUM, an unsupervised density-ratio estimation (DRE) based approach to determine statistical changes in time-series data when no knowledge of the pre-and post-change distributions are available. The core idea behind the proposed approach is to split the time-series at an arbitrary point and estimate the ratio of densities of distribution (using a parametric model such as a neural network) before and after the split point. The DRE-CUSUM change detection statistic is then derived from the cumulative sum (CUSUM) of the logarithm of the estimated density ratio. We present a theoretical justification as well as accuracy guarantees which show that the proposed statistic can reliably detect statistical changes, irrespective of the split point. While there have been prior works on using density ratio based methods for change detection, to the best of our knowledge, this is the first unsupervised change detection approach with a theoretical justification and accuracy guarantees. The simplicity of the proposed framework makes it readily applicable in various practical settings (including high-dimensional time-series data); we also discuss generalizations for online change detection. We experimentally show the superiority of DRE-CUSUM using both synthetic and real-world datasets over existing state-of-the-art unsupervised algorithms (such as Bayesian online change detection, its variants as well as several other heuristic methods).

In this paper, we present how Bell's Palsy, a neurological disorder, can be detected just from a subject's eyes in a video. We notice that Bell's Palsy patients often struggle to blink their eyes on the affected side. As a result, we can observe a clear contrast between the blinking patterns of the two eyes. Although previous works did utilize images/videos to detect this disorder, none have explicitly focused on the eyes. Most of them require the entire face. One obvious advantage of having an eye-focused detection system is that subjects' anonymity is not at risk. Also, our AI decisions based on simple blinking patterns make them explainable and straightforward. Specifically, we develop a novel feature called blink similarity, which measures the similarity between the two blinking patterns. Our extensive experiments demonstrate that the proposed feature is quite robust, for it helps in Bell's Palsy detection even with very few labels. Our proposed eye-focused detection system is not only cheaper but also more convenient than several existing methods.
Recent advances in sensor and mobile devices have enabled an unprecedented increase in the availability and collection of urban trajectory data, thus increasing the demand for more efficient ways to manage and analyze the data being produced. In this survey, we comprehensively review recent research trends in trajectory data management, ranging from trajectory pre-processing, storage, common trajectory analytic tools, such as querying spatial-only and spatial-textual trajectory data, and trajectory clustering. We also explore four closely related analytical tasks commonly used with trajectory data in interactive or real-time processing. Deep trajectory learning is also reviewed for the first time. Finally, we outline the essential qualities that a trajectory management system should possess in order to maximize flexibility.
Outlier detection is an important topic in machine learning and has been used in a wide range of applications. In this paper, we approach outlier detection as a binary-classification issue by sampling potential outliers from a uniform reference distribution. However, due to the sparsity of data in high-dimensional space, a limited number of potential outliers may fail to provide sufficient information to assist the classifier in describing a boundary that can separate outliers from normal data effectively. To address this, we propose a novel Single-Objective Generative Adversarial Active Learning (SO-GAAL) method for outlier detection, which can directly generate informative potential outliers based on the mini-max game between a generator and a discriminator. Moreover, to prevent the generator from falling into the mode collapsing problem, the stop node of training should be determined when SO-GAAL is able to provide sufficient information. But without any prior information, it is extremely difficult for SO-GAAL. Therefore, we expand the network structure of SO-GAAL from a single generator to multiple generators with different objectives (MO-GAAL), which can generate a reasonable reference distribution for the whole dataset. We empirically compare the proposed approach with several state-of-the-art outlier detection methods on both synthetic and real-world datasets. The results show that MO-GAAL outperforms its competitors in the majority of cases, especially for datasets with various cluster types or high irrelevant variable ratio.
Abnormal event detection in video is a challenging vision problem. Most existing approaches formulate abnormal event detection as an outlier detection task, due to the scarcity of anomalous data during training. Because of the lack of prior information regarding abnormal events, these methods are not fully-equipped to differentiate between normal and abnormal events. In this work, we formalize abnormal event detection as a one-versus-rest binary classification problem. Our contribution is two-fold. First, we introduce an unsupervised feature learning framework based on object-centric convolutional auto-encoders to encode both motion and appearance information. Second, we propose a supervised classification approach based on clustering the training samples into normality clusters. A one-versus-rest abnormal event classifier is then employed to separate each normality cluster from the rest. For the purpose of training the classifier, the other clusters act as dummy anomalies. During inference, an object is labeled as abnormal if the highest classification score assigned by the one-versus-rest classifiers is negative. Comprehensive experiments are performed on four benchmarks: Avenue, ShanghaiTech, UCSD and UMN. Our approach provides superior results on all four data sets. On the large-scale ShanghaiTech data set, our method provides an absolute gain of 12.1% in terms of frame-level AUC compared to the state-of-the-art method [Liu et al., CVPR 2018].
With the growth of mobile devices and applications, the number of malicious software, or malware, is rapidly increasing in recent years, which calls for the development of advanced and effective malware detection approaches. Traditional methods such as signature-based ones cannot defend users from an increasing number of new types of malware or rapid malware behavior changes. In this paper, we propose a new Android malware detection approach based on deep learning and static analysis. Instead of using Application Programming Interfaces (APIs) only, we further analyze the source code of Android applications and create their higher-level graphical semantics, which makes it harder for attackers to evade detection. In particular, we use a call graph from method invocations in an Android application to represent the application, and further analyze method attributes to form a structured Program Representation Graph (PRG) with node attributes. Then, we use a graph convolutional network (GCN) to yield a graph representation of the application by embedding the entire graph into a dense vector, and classify whether it is a malware or not. To efficiently train such a graph convolutional network, we propose a batch training scheme that allows multiple heterogeneous graphs to be input as a batch. To the best of our knowledge, this is the first work to use graph representation learning for malware detection. We conduct extensive experiments from real-world sample collections and demonstrate that our developed system outperforms multiple other existing malware detection techniques.
Accurate detection and tracking of objects is vital for effective video understanding. In previous work, the two tasks have been combined in a way that tracking is based heavily on detection, but the detection benefits marginally from the tracking. To increase synergy, we propose to more tightly integrate the tasks by conditioning the object detection in the current frame on tracklets computed in prior frames. With this approach, the object detection results not only have high detection responses, but also improved coherence with the existing tracklets. This greater coherence leads to estimated object trajectories that are smoother and more stable than the jittered paths obtained without tracklet-conditioned detection. Over extensive experiments, this approach is shown to achieve state-of-the-art performance in terms of both detection and tracking accuracy, as well as noticeable improvements in tracking stability.
Latest deep learning methods for object detection provide remarkable performance, but have limits when used in robotic applications. One of the most relevant issues is the long training time, which is due to the large size and imbalance of the associated training sets, characterized by few positive and a large number of negative examples (i.e. background). Proposed approaches are based on end-to-end learning by back-propagation [22] or kernel methods trained with Hard Negatives Mining on top of deep features [8]. These solutions are effective, but prohibitively slow for on-line applications. In this paper we propose a novel pipeline for object detection that overcomes this problem and provides comparable performance, with a 60x training speedup. Our pipeline combines (i) the Region Proposal Network and the deep feature extractor from [22] to efficiently select candidate RoIs and encode them into powerful representations, with (ii) the FALKON [23] algorithm, a novel kernel-based method that allows fast training on large scale problems (millions of points). We address the size and imbalance of training data by exploiting the stochastic subsampling intrinsic into the method and a novel, fast, bootstrapping approach. We assess the effectiveness of the approach on a standard Computer Vision dataset (PASCAL VOC 2007 [5]) and demonstrate its applicability to a real robotic scenario with the iCubWorld Transformations [18] dataset.
We introduce and tackle the problem of zero-shot object detection (ZSD), which aims to detect object classes which are not observed during training. We work with a challenging set of object classes, not restricting ourselves to similar and/or fine-grained categories as in prior works on zero-shot classification. We present a principled approach by first adapting visual-semantic embeddings for ZSD. We then discuss the problems associated with selecting a background class and motivate two background-aware approaches for learning robust detectors. One of these models uses a fixed background class and the other is based on iterative latent assignments. We also outline the challenge associated with using a limited number of training classes and propose a solution based on dense sampling of the semantic label space using auxiliary data with a large number of categories. We propose novel splits of two standard detection datasets - MSCOCO and VisualGenome, and present extensive empirical results in both the traditional and generalized zero-shot settings to highlight the benefits of the proposed methods. We provide useful insights into the algorithm and conclude by posing some open questions to encourage further research.
Existing visual tracking methods usually localize a target object with a bounding box, in which the performance of the foreground object trackers or detectors is often affected by the inclusion of background clutter. To handle this problem, we learn a patch-based graph representation for visual tracking. The tracked object is modeled by with a graph by taking a set of non-overlapping image patches as nodes, in which the weight of each node indicates how likely it belongs to the foreground and edges are weighted for indicating the appearance compatibility of two neighboring nodes. This graph is dynamically learned and applied in object tracking and model updating. During the tracking process, the proposed algorithm performs three main steps in each frame. First, the graph is initialized by assigning binary weights of some image patches to indicate the object and background patches according to the predicted bounding box. Second, the graph is optimized to refine the patch weights by using a novel alternating direction method of multipliers. Third, the object feature representation is updated by imposing the weights of patches on the extracted image features. The object location is predicted by maximizing the classification score in the structured support vector machine. Extensive experiments show that the proposed tracking algorithm performs well against the state-of-the-art methods on large-scale benchmark datasets.
小貼士
登錄享
注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191