


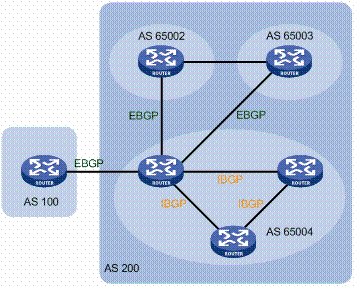
In an interdomain network, autonomous systems (ASes) often establish peering agreements, so that one AS (agreement consumer) can influence the routing policies of the other AS (agreement provider). Peering agreements are implemented in the BGP configuration of the agreement provider. It is crucial to verify their implementation because one error can lead to disastrous consequences. However, the fundamental challenge for peering agreement verification is how to preserve the privacy of both ASes involved in the agreement. To this end, this paper presents IVeri, the first privacy-preserving interdomain agreement verification system. IVeri models the interdomain agreement verification problem as a SAT formula, and develops a novel, efficient, privacy-serving SAT solver, which uses oblivious shuffling and garbled circuits as the key building blocks to let the agreement consumer and provider collaboratively verify the implementation of interdomain peering agreements without exposing their private information. A prototype of IVeri is implemented and evaluated extensively. Results show that IVeri achieves accurate, privacy-preserving interdomain agreement verification with reasonable overhead.
相關內容
SAT是研究者關注命題可滿足性問題的理論與應用的第一次年度會議。除了簡單命題可滿足性外,它還包括布爾優化(如MaxSAT和偽布爾(PB)約束)、量化布爾公式(QBF)、可滿足性模理論(SMT)和約束規劃(CP),用于與布爾級推理有明確聯系的問題。官網鏈接: ·
BGP
·
控制器
·
Networking
·
知識 (knowledge)
·
Current network control plane verification tools cannot scale to large networks, because of the complexity of jointly reasoning about the behaviors of all nodes in the network. In this paper we present a modular approach to control plane verification, whereby end-to-end network properties are verified via a set of purely local checks on individual nodes and edges. The approach targets the verification of safety properties for BGP configurations and provides guarantees in the face of both arbitrary external route announcements from neighbors and arbitrary node/link failures. We have proven the approach correct and also implemented it in a tool called Lightyear. Experimental results show that Lightyear scales dramatically better than prior control plane verifiers. Further, we have used Lightyear to verify three properties of the wide area network of a major cloud provider, containing hundreds of routers and tens of thousands of edges. To our knowledge no prior tool has been demonstrated to provide such guarantees at that scale. Finally, in addition to the scaling benefits, our modular approach to verification makes it easy to localize the causes of configuration errors and to support incremental re-verification as configurations are updated
Large scale adoption of large language models has introduced a new era of convenient knowledge transfer for a slew of natural language processing tasks. However, these models also run the risk of undermining user trust by exposing unwanted information about the data subjects, which may be extracted by a malicious party, e.g. through adversarial attacks. We present an empirical investigation into the extent of the personal information encoded into pre-trained representations by a range of popular models, and we show a positive correlation between the complexity of a model, the amount of data used in pre-training, and data leakage. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular privacy-preserving algorithms, on a large, multi-lingual dataset on sentiment analysis annotated with demographic information (location, age and gender). The results show since larger and more complex models are more prone to leaking private information, use of privacy-preserving methods is highly desirable. We also find that highly privacy-preserving technologies like differential privacy (DP) can have serious model utility effects, which can be ameliorated using hybrid or metric-DP techniques.
The human footprint is having a unique set of ridges unmatched by any other human being, and therefore it can be used in different identity documents for example birth certificate, Indian biometric identification system AADHAR card, driving license, PAN card, and passport. There are many instances of the crime scene where an accused must walk around and left the footwear impressions as well as barefoot prints and therefore, it is very crucial to recovering the footprints from identifying the criminals. Footprint-based biometric is a considerably newer technique for personal identification. Fingerprints, retina, iris and face recognition are the methods most useful for attendance record of the person. This time the world is facing the problem of global terrorism. It is challenging to identify the terrorist because they are living as regular as the citizens do. Their soft target includes the industries of special interests such as defence, silicon and nanotechnology chip manufacturing units, pharmacy sectors. They pretend themselves as religious persons, so temples and other holy places, even in markets is in their targets. These are the places where one can obtain their footprints quickly. The gait itself is sufficient to predict the behaviour of the suspects. The present research is driven to identify the usefulness of footprint and gait as an alternative to personal identification.
The long-tailed distribution datasets poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balacing strategies or transfer learing from head- to tail-classes or use two-stages learning strategy to re-train the classifier. However, the existing methods are difficult to solve the low quality problem when images are obtained by SAR. To address this problem, we establish a novel three-stages training strategy, which has excellent results for processing SAR image datasets with long-tailed distribution. Specifically, we divide training procedure into three stages. The first stage is to use all kinds of images for rough-training, so as to get the rough-training model with rich content. The second stage is to make the rough model learn the feature expression by using the residual dataset with the class 0 removed. The third stage is to fine tune the model using class-balanced datasets with all 10 classes (including the overall model fine tuning and classifier re-optimization). Through this new training strategy, we only use the information of SAR image dataset and the network model with very small parameters to achieve the top 1 accuracy of 22.34 in development phase.
Randomized field experiments are the gold standard for evaluating the impact of software changes on customers. In the online domain, randomization has been the main tool to ensure exchangeability. However, due to the different deployment conditions and the high dependence on the surrounding environment, designing experiments for automotive software needs to consider a higher number of restricted variables to ensure conditional exchangeability. In this paper, we show how at Volvo Cars we utilize causal graphical models to design experiments and explicitly communicate the assumptions of experiments. These graphical models are used to further assess the experiment validity, compute direct and indirect causal effects, and reason on the transportability of the causal conclusions.
The emerging public awareness and government regulations of data privacy motivate new paradigms of collecting and analyzing data that are transparent and acceptable to data owners. We present a new concept of privacy and corresponding data formats, mechanisms, and theories for privatizing data during data collection. The privacy, named Interval Privacy, enforces the raw data conditional distribution on the privatized data to be the same as its unconditional distribution over a nontrivial support set. Correspondingly, the proposed privacy mechanism will record each data value as a random interval (or, more generally, a range) containing it. The proposed interval privacy mechanisms can be easily deployed through survey-based data collection interfaces, e.g., by asking a respondent whether its data value is within a randomly generated range. Another unique feature of interval mechanisms is that they obfuscate the truth but do not perturb it. Using narrowed range to convey information is complementary to the popular paradigm of perturbing data. Also, the interval mechanisms can generate progressively refined information at the discretion of individuals, naturally leading to privacy-adaptive data collection. We develop different aspects of theory such as composition, robustness, distribution estimation, and regression learning from interval-valued data. Interval privacy provides a new perspective of human-centric data privacy where individuals have a perceptible, transparent, and simple way of sharing sensitive data.
The Mixture-of-Experts (MoE) technique can scale up the model size of Transformers with an affordable computational overhead. We point out that existing learning-to-route MoE methods suffer from the routing fluctuation issue, i.e., the target expert of the same input may change along with training, but only one expert will be activated for the input during inference. The routing fluctuation tends to harm sample efficiency because the same input updates different experts but only one is finally used. In this paper, we propose StableMoE with two training stages to address the routing fluctuation problem. In the first training stage, we learn a balanced and cohesive routing strategy and distill it into a lightweight router decoupled from the backbone model. In the second training stage, we utilize the distilled router to determine the token-to-expert assignment and freeze it for a stable routing strategy. We validate our method on language modeling and multilingual machine translation. The results show that StableMoE outperforms existing MoE methods in terms of both convergence speed and performance.
Medical data is often highly sensitive in terms of data privacy and security concerns. Federated learning, one type of machine learning techniques, has been started to use for the improvement of the privacy and security of medical data. In the federated learning, the training data is distributed across multiple machines, and the learning process is performed in a collaborative manner. There are several privacy attacks on deep learning (DL) models to get the sensitive information by attackers. Therefore, the DL model itself should be protected from the adversarial attack, especially for applications using medical data. One of the solutions for this problem is homomorphic encryption-based model protection from the adversary collaborator. This paper proposes a privacy-preserving federated learning algorithm for medical data using homomorphic encryption. The proposed algorithm uses a secure multi-party computation protocol to protect the deep learning model from the adversaries. In this study, the proposed algorithm using a real-world medical dataset is evaluated in terms of the model performance.
Brain-computer interface (BCI) is challenging to use in practice due to the inter/intra-subject variability of electroencephalography (EEG). The BCI system, in general, necessitates a calibration technique to obtain subject/session-specific data in order to tune the model each time the system is utilized. This issue is acknowledged as a key hindrance to BCI, and a new strategy based on domain generalization has recently evolved to address it. In light of this, we've concentrated on developing an EEG classification framework that can be applied directly to data from unknown domains (i.e. subjects), using only data acquired from separate subjects previously. For this purpose, in this paper, we proposed a framework that employs the open-set recognition technique as an auxiliary task to learn subject-specific style features from the source dataset while helping the shared feature extractor with mapping the features of the unseen target dataset as a new unseen domain. Our aim is to impose cross-instance style in-variance in the same domain and reduce the open space risk on the potential unseen subject in order to improve the generalization ability of the shared feature extractor. Our experiments showed that using the domain information as an auxiliary network increases the generalization performance.
Federated learning with differential privacy, or private federated learning, provides a strategy to train machine learning models while respecting users' privacy. However, differential privacy can disproportionately degrade the performance of the models on under-represented groups, as these parts of the distribution are difficult to learn in the presence of noise. Existing approaches for enforcing fairness in machine learning models have considered the centralized setting, in which the algorithm has access to the users' data. This paper introduces an algorithm to enforce group fairness in private federated learning, where users' data does not leave their devices. First, the paper extends the modified method of differential multipliers to empirical risk minimization with fairness constraints, thus providing an algorithm to enforce fairness in the central setting. Then, this algorithm is extended to the private federated learning setting. The proposed algorithm, \texttt{FPFL}, is tested on a federated version of the Adult dataset and an "unfair" version of the FEMNIST dataset. The experiments on these datasets show how private federated learning accentuates unfairness in the trained models, and how FPFL is able to mitigate such unfairness.
小貼士
登錄享
相關主題



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191