


The functional interpretation of language-related ERP components has been a central debate in psycholinguistics for decades. We advance an information-theoretic model of human language processing in the brain in which incoming linguistic input is processed at first shallowly and later with more depth, with these two kinds of information processing corresponding to distinct electroencephalographic signatures. Formally, we show that the information content (surprisal) of a word in context can be decomposed into two quantities: (A) shallow surprisal, which signals shallow processing difficulty for a word, and corresponds with the N400 signal; and (B) deep surprisal, which reflects the discrepancy between shallow and deep representations, and corresponds to the P600 signal and other late positivities. Both of these quantities can be estimated straightforwardly using modern NLP models. We validate our theory by successfully simulating ERP patterns elicited by a variety of linguistic manipulations in previously-reported experimental data from six experiments, with successful novel qualitative and quantitative predictions. Our theory is compatible with traditional cognitive theories assuming a `good-enough' shallow representation stage, but with a precise information-theoretic formulation. The model provides an information-theoretic model of ERP components grounded on cognitive processes, and brings us closer to a fully-specified neuro-computational model of language processing.
相關內容
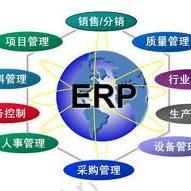
Processing 是一門開(kai)源(yuan)編程語(yu)言(yan)和與之(zhi)配套(tao)的集成(cheng)開(kai)發環境(IDE)的名稱。Processing 在電(dian)子藝(yi)術(shu)和視覺設計社區被(bei)用(yong)來教授編程基礎,并運用(yong)于大量的新(xin)媒體(ti)和互(hu)動藝(yi)術(shu)作品中。
Incorporating prior knowledge into pre-trained language models has proven to be effective for knowledge-driven NLP tasks, such as entity typing and relation extraction. Current pre-training procedures usually inject external knowledge into models by using knowledge masking, knowledge fusion and knowledge replacement. However, factual information contained in the input sentences have not been fully mined, and the external knowledge for injecting have not been strictly checked. As a result, the context information cannot be fully exploited and extra noise will be introduced or the amount of knowledge injected is limited. To address these issues, we propose MLRIP, which modifies the knowledge masking strategies proposed by ERNIE-Baidu, and introduce a two-stage entity replacement strategy. Extensive experiments with comprehensive analyses illustrate the superiority of MLRIP over BERT-based models in military knowledge-driven NLP tasks.
This dissertation studies a fundamental open challenge in deep learning theory: why do deep networks generalize well even while being overparameterized, unregularized and fitting the training data to zero error? In the first part of the thesis, we will empirically study how training deep networks via stochastic gradient descent implicitly controls the networks' capacity. Subsequently, to show how this leads to better generalization, we will derive {\em data-dependent} {\em uniform-convergence-based} generalization bounds with improved dependencies on the parameter count. Uniform convergence has in fact been the most widely used tool in deep learning literature, thanks to its simplicity and generality. Given its popularity, in this thesis, we will also take a step back to identify the fundamental limits of uniform convergence as a tool to explain generalization. In particular, we will show that in some example overparameterized settings, {\em any} uniform convergence bound will provide only a vacuous generalization bound. With this realization in mind, in the last part of the thesis, we will change course and introduce an {\em empirical} technique to estimate generalization using unlabeled data. Our technique does not rely on any notion of uniform-convergece-based complexity and is remarkably precise. We will theoretically show why our technique enjoys such precision. We will conclude by discussing how future work could explore novel ways to incorporate distributional assumptions in generalization bounds (such as in the form of unlabeled data) and explore other tools to derive bounds, perhaps by modifying uniform convergence or by developing completely new tools altogether.
We present ResMLP, an architecture built entirely upon multi-layer perceptrons for image classification. It is a simple residual network that alternates (i) a linear layer in which image patches interact, independently and identically across channels, and (ii) a two-layer feed-forward network in which channels interact independently per patch. When trained with a modern training strategy using heavy data-augmentation and optionally distillation, it attains surprisingly good accuracy/complexity trade-offs on ImageNet. We will share our code based on the Timm library and pre-trained models.
Artificial neural networks thrive in solving the classification problem for a particular rigid task, acquiring knowledge through generalized learning behaviour from a distinct training phase. The resulting network resembles a static entity of knowledge, with endeavours to extend this knowledge without targeting the original task resulting in a catastrophic forgetting. Continual learning shifts this paradigm towards networks that can continually accumulate knowledge over different tasks without the need to retrain from scratch. We focus on task incremental classification, where tasks arrive sequentially and are delineated by clear boundaries. Our main contributions concern 1) a taxonomy and extensive overview of the state-of-the-art, 2) a novel framework to continually determine the stability-plasticity trade-off of the continual learner, 3) a comprehensive experimental comparison of 11 state-of-the-art continual learning methods and 4 baselines. We empirically scrutinize method strengths and weaknesses on three benchmarks, considering Tiny Imagenet and large-scale unbalanced iNaturalist and a sequence of recognition datasets. We study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented, and qualitatively compare methods in terms of required memory, computation time, and storage.
The remarkable practical success of deep learning has revealed some major surprises from a theoretical perspective. In particular, simple gradient methods easily find near-optimal solutions to non-convex optimization problems, and despite giving a near-perfect fit to training data without any explicit effort to control model complexity, these methods exhibit excellent predictive accuracy. We conjecture that specific principles underlie these phenomena: that overparametrization allows gradient methods to find interpolating solutions, that these methods implicitly impose regularization, and that overparametrization leads to benign overfitting. We survey recent theoretical progress that provides examples illustrating these principles in simpler settings. We first review classical uniform convergence results and why they fall short of explaining aspects of the behavior of deep learning methods. We give examples of implicit regularization in simple settings, where gradient methods lead to minimal norm functions that perfectly fit the training data. Then we review prediction methods that exhibit benign overfitting, focusing on regression problems with quadratic loss. For these methods, we can decompose the prediction rule into a simple component that is useful for prediction and a spiky component that is useful for overfitting but, in a favorable setting, does not harm prediction accuracy. We focus specifically on the linear regime for neural networks, where the network can be approximated by a linear model. In this regime, we demonstrate the success of gradient flow, and we consider benign overfitting with two-layer networks, giving an exact asymptotic analysis that precisely demonstrates the impact of overparametrization. We conclude by highlighting the key challenges that arise in extending these insights to realistic deep learning settings.
Meta-learning, or learning to learn, has gained renewed interest in recent years within the artificial intelligence community. However, meta-learning is incredibly prevalent within nature, has deep roots in cognitive science and psychology, and is currently studied in various forms within neuroscience. The aim of this review is to recast previous lines of research in the study of biological intelligence within the lens of meta-learning, placing these works into a common framework. More recent points of interaction between AI and neuroscience will be discussed, as well as interesting new directions that arise under this perspective.
Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources
For languages with no annotated resources, transferring knowledge from rich-resource languages is an effective solution for named entity recognition (NER). While all existing methods directly transfer from source-learned model to a target language, in this paper, we propose to fine-tune the learned model with a few similar examples given a test case, which could benefit the prediction by leveraging the structural and semantic information conveyed in such similar examples. To this end, we present a meta-learning algorithm to find a good model parameter initialization that could fast adapt to the given test case and propose to construct multiple pseudo-NER tasks for meta-training by computing sentence similarities. To further improve the model's generalization ability across different languages, we introduce a masking scheme and augment the loss function with an additional maximum term during meta-training. We conduct extensive experiments on cross-lingual named entity recognition with minimal resources over five target languages. The results show that our approach significantly outperforms existing state-of-the-art methods across the board.
Graph representation learning for hypergraphs can be used to extract patterns among higher-order interactions that are critically important in many real world problems. Current approaches designed for hypergraphs, however, are unable to handle different types of hypergraphs and are typically not generic for various learning tasks. Indeed, models that can predict variable-sized heterogeneous hyperedges have not been available. Here we develop a new self-attention based graph neural network called Hyper-SAGNN applicable to homogeneous and heterogeneous hypergraphs with variable hyperedge sizes. We perform extensive evaluations on multiple datasets, including four benchmark network datasets and two single-cell Hi-C datasets in genomics. We demonstrate that Hyper-SAGNN significantly outperforms the state-of-the-art methods on traditional tasks while also achieving great performance on a new task called outsider identification. Hyper-SAGNN will be useful for graph representation learning to uncover complex higher-order interactions in different applications.
In recent years, object detection has experienced impressive progress. Despite these improvements, there is still a significant gap in the performance between the detection of small and large objects. We analyze the current state-of-the-art model, Mask-RCNN, on a challenging dataset, MS COCO. We show that the overlap between small ground-truth objects and the predicted anchors is much lower than the expected IoU threshold. We conjecture this is due to two factors; (1) only a few images are containing small objects, and (2) small objects do not appear enough even within each image containing them. We thus propose to oversample those images with small objects and augment each of those images by copy-pasting small objects many times. It allows us to trade off the quality of the detector on large objects with that on small objects. We evaluate different pasting augmentation strategies, and ultimately, we achieve 9.7\% relative improvement on the instance segmentation and 7.1\% on the object detection of small objects, compared to the current state of the art method on MS COCO.
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
小貼士
登錄享



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191