

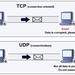
Existing network stacks tackle performance and scalability aspects by relying on multiple receive queues. However, at software level, each queue is processed by a single thread, which prevents simultaneous work on the same queue and limits performance in terms of tail latency. To overcome this limitation, we introduce COREC, the first software implementation of a concurrent non-blocking single-queue receive driver. By sharing a single queue among multiple threads, workload distribution is improved, leading to a work-conserving policy for network stacks. On the technical side, instead of relying on traditional critical sections - which would sequentialize the operations by threads - COREC coordinates the threads that concurrently access the same receive queue in non-blocking manner via atomic machine instructions from the Read-Modify-Write (RMW) class. These instructions allow threads to access and update memory locations atomically, based on specific conditions, such as the matching of a target value selected by the thread. Also, they enable making any update globally visible in the memory hierarchy, bypassing interference on memory consistency caused by the CPU store buffers. Extensive evaluation results demonstrate that the possible additional reordering, which our approach may occasionally cause, is non-critical and has minimal impact on performance, even in the worst-case scenario of a single large TCP flow, with performance impairments accounting to at most 2-3 percent. Conversely, substantial latency gains are achieved when handling UDP traffic, real-world traffic mix, and multiple shorter TCP flows.
相關內容
Unsupervised Anomaly Detection (UAD) techniques aim to identify and localize anomalies without relying on annotations, only leveraging a model trained on a dataset known to be free of anomalies. Diffusion models learn to modify inputs $x$ to increase the probability of it belonging to a desired distribution, i.e., they model the score function $\nabla_x \log p(x)$. Such a score function is potentially relevant for UAD, since $\nabla_x \log p(x)$ is itself a pixel-wise anomaly score. However, diffusion models are trained to invert a corruption process based on Gaussian noise and the learned score function is unlikely to generalize to medical anomalies. This work addresses the problem of how to learn a score function relevant for UAD and proposes DISYRE: Diffusion-Inspired SYnthetic REstoration. We retain the diffusion-like pipeline but replace the Gaussian noise corruption with a gradual, synthetic anomaly corruption so the learned score function generalizes to medical, naturally occurring anomalies. We evaluate DISYRE on three common Brain MRI UAD benchmarks and substantially outperform other methods in two out of the three tasks.
The security of cloud field-programmable gate arrays (FPGAs) faces challenges from untrusted users attempting fault and side-channel attacks through malicious circuit configurations. Fault injection attacks can result in denial of service, disrupting functionality or leaking secret information. This threat is further amplified in multi-tenancy scenarios. Detecting such threats before loading onto the FPGA is crucial, but existing methods face difficulty identifying sophisticated attacks. We present MaliGNNoma, a machine learning-based solution that accurately identifies malicious FPGA configurations. Serving as a netlist scanning mechanism, it can be employed by cloud service providers as an initial security layer within a necessary multi-tiered security system. By leveraging the inherent graph representation of FPGA netlists, MaliGNNoma employs a graph neural network (GNN) to learn distinctive malicious features, surpassing current approaches. To enhance transparency, MaliGNNoma utilizes a parameterized explainer for the GNN, labeling the FPGA configuration and pinpointing the sub-circuit responsible for the malicious classification. Through extensive experimentation on the ZCU102 board with a Xilinx UltraScale+ FPGA, we validate the effectiveness of MaliGNNoma in detecting malicious configurations, including sophisticated attacks, such as those based on benign modules, like cryptography accelerators. MaliGNNoma achieves a classification accuracy and precision of 98.24% and 97.88%, respectively, surpassing state-of-the-art. We compare MaliGNNoma with five state-of-the-art scanning methods, revealing that not all attack vectors detected by MaliGNNoma are recognized by existing solutions, further emphasizing its effectiveness. Additionally, we make MaliGNNoma and its associated dataset publicly available.
Despite the impressive capabilities of large language models (LLMs) across diverse applications, they still suffer from trustworthiness issues, such as hallucinations and misalignments. Retrieval-augmented language models (RAG) have been proposed to enhance the credibility of generations by grounding external knowledge, but the theoretical understandings of their generation risks remains unexplored. In this paper, we answer: 1) whether RAG can indeed lead to low generation risks, 2) how to provide provable guarantees on the generation risks of RAG and vanilla LLMs, and 3) what sufficient conditions enable RAG models to reduce generation risks. We propose C-RAG, the first framework to certify generation risks for RAG models. Specifically, we provide conformal risk analysis for RAG models and certify an upper confidence bound of generation risks, which we refer to as conformal generation risk. We also provide theoretical guarantees on conformal generation risks for general bounded risk functions under test distribution shifts. We prove that RAG achieves a lower conformal generation risk than that of a single LLM when the quality of the retrieval model and transformer is non-trivial. Our intensive empirical results demonstrate the soundness and tightness of our conformal generation risk guarantees across four widely-used NLP datasets on four state-of-the-art retrieval models.
For scientific software, especially those used for large-scale simulations, achieving good performance and efficiently using the available hardware resources is essential. It is important to regularly perform benchmarks to ensure the efficient use of hardware and software when systems are changing and the software evolves. However, this can become quickly very tedious when many options for parameters, solvers, and hardware architectures are available. We present a continuous benchmarking strategy that automates benchmarking new code changes on high-performance computing clusters. This makes it possible to track how each code change affects the performance and how it evolves.
The growing system complexity from microservice architectures and the bilateral enhancement of artificial intelligence (AI) for both attackers and defenders presents increasing security challenges for cloud-native operations. In particular, cloud-native operators require a holistic view of the dynamic security posture for the cloud-native environment from a defense aspect. Additionally, both attackers and defenders can adopt advanced AI technologies. This makes the dynamic interaction and benchmark among different intelligent offense and defense strategies more crucial. Hence, following the multi-agent deep reinforcement learning (RL) paradigm, this research develops an agent-based intelligent security service framework (ISSF) for cloud-native operation. It includes a dynamic access graph model to represent the cloud-native environment and an action model to represent offense and defense actions. Then we develop an approach to enable the training, publishing, and evaluating of intelligent security services using diverse deep RL algorithms and training strategies, facilitating their systematic development and benchmark. The experiments demonstrate that our framework can sufficiently model the security posture of a cloud-native system for defenders, effectively develop and quantitatively benchmark different services for both attackers and defenders and guide further service optimization.
Network security analysts gather data from diverse sources, from high-level summaries of network flow and traffic volumes to low-level details such as service logs from servers and the contents of individual packets. They validate and check this data against traffic patterns and historical indicators of compromise. Based on the results of this analysis, a decision is made to either automatically manage the traffic or report it to an analyst for further investigation. Unfortunately, due rapidly increasing traffic volumes, there are far more events to check than operational teams can handle for effective forensic analysis. However, just as packets are grouped into flows that share a commonality, we argue that a high-level construct for grouping network flows into a set a flows that share a hypothesis is needed to significantly improve the quality of operational network response by increasing Events Per Analysts Hour (EPAH). In this paper, we propose a formalism for describing a superflow construct, which we characterize as an aggregation of one or more flows based on an analyst-specific hypothesis about traffic behavior. We demonstrate simple superflow constructions and representations, and perform a case study to explain how the formalism can be used to reduce the volume of data for forensic analysis.
Large deep learning models have achieved impressive performance across a range of applications. However, their large memory requirements, including parameter memory and activation memory, have become a significant challenge for their practical serving. While existing methods mainly address parameter memory, the importance of activation memory has been overlooked. Especially for long input sequences, activation memory is expected to experience a significant exponential growth as the length of sequences increases. In this approach, we propose AutoChunk, an automatic and adaptive compiler system that efficiently reduces activation memory for long sequence inference by chunk strategies. The proposed system generates chunk plans by optimizing through multiple stages. In each stage, the chunk search pass explores all possible chunk candidates and the chunk selection pass identifies the optimal one. At runtime, AutoChunk employs code generation to automatically apply chunk strategies. The experiments demonstrate that AutoChunk can reduce over 80\% of activation memory while maintaining speed loss within 10%, extend max sequence length by 3.2x to 11.7x, and outperform state-of-the-art methods by a large margin.
We introduce CyberDemo, a novel approach to robotic imitation learning that leverages simulated human demonstrations for real-world tasks. By incorporating extensive data augmentation in a simulated environment, CyberDemo outperforms traditional in-domain real-world demonstrations when transferred to the real world, handling diverse physical and visual conditions. Regardless of its affordability and convenience in data collection, CyberDemo outperforms baseline methods in terms of success rates across various tasks and exhibits generalizability with previously unseen objects. For example, it can rotate novel tetra-valve and penta-valve, despite human demonstrations only involving tri-valves. Our research demonstrates the significant potential of simulated human demonstrations for real-world dexterous manipulation tasks. More details can be found at //cyber-demo.github.io
We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on //github.com/microsoft/UFO.
Deep neural network (DNN) typically involves convolutions, pooling, and activation function. Due to the growing concern about privacy, privacy-preserving DNN becomes a hot research topic. Generally, the convolution and pooling operations can be supported by additive homomorphic and secure comparison, but the secure implementation of activation functions is not so straightforward for the requirements of accuracy and efficiency, especially for the non-linear ones such as exponential, sigmoid, and tanh functions. This paper pays a special attention to the implementation of such non-linear functions in semi-honest model with two-party settings, for which SIRNN is the current state-of-the-art. Different from previous works, we proposed improved implementations for these functions by using their intrinsic features as well as worthy tiny tricks. At first, we propose a novel and efficient protocol for exponential function by using a divide-and-conquer strategy with most of the computations executed locally. Exponential protocol is widely used in machine learning tasks such as Poisson regression, and is also a key component of sigmoid and tanh functions. Next, we take advantage of the symmetry of sigmoid and Tanh, and fine-tune the inputs to reduce the 2PC building blocks, which helps to save overhead and improve performance. As a result, we implement these functions with fewer fundamental building blocks. The comprehensive evaluations show that our protocols achieve state-of-the-art precision while reducing run-time by approximately 57%, 44%, and 42% for exponential (with only negative inputs), sigmoid, and Tanh functions, respectively.
小貼士
登錄享



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191