
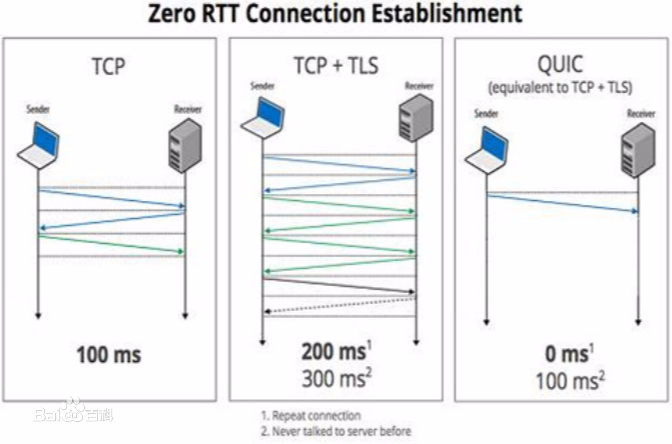

The Tactile Internet paradigm is set to revolutionize human society by enabling skill-set delivery and haptic communication over ultra-reliable, low-latency networks. The emerging sixth-generation (6G) mobile communication systems are envisioned to underpin this Tactile Internet ecosystem at the network edge by providing ubiquitous global connectivity. However, apart from a multitude of opportunities of the Tactile Internet, security and privacy challenges emerge at the forefront. We believe that the recently standardized QUIC protocol, characterized by end-to-end encryption and reduced round-trip delay would serve as the backbone of Tactile Internet. In this article, we envision a futuristic scenario where a QUIC-enabled network uses the underlying 6G communication infrastructure to achieve the requirements for Tactile Internet. Interestingly this requires a deeper investigation of a wide range of security and privacy challenges in QUIC, that need to be mitigated for its adoption in Tactile Internet. Henceforth, this article reviews the existing security and privacy attacks in QUIC and their implication on users. Followed by that, we discuss state-of-the-art attack mitigation strategies and investigate some of their drawbacks with possible directions for future work
相關內容
Aligning language models to human expectations, e.g., being helpful and harmless, has become a pressing challenge for large language models. A typical alignment procedure consists of supervised fine-tuning and preference learning. Most preference learning methods, such as RLHF and DPO, depend on pairwise preference data, which inadequately address scenarios where human feedback is point-wise, leading to potential information loss and suboptimal performance. Addressing this gap, we introduce Point-wise Direct Preference Optimization, a novel preference learning method designed to harness point-wise feedback effectively. Our work also uncovers a novel connection between supervised fine-tuning and point-wise preference learning, culminating in Unified Language Model Alignment, a single-step method that unifies the alignment with human demonstrations and point-wise preferences. Extensive experiments on point-wise preference datasets with binary or continuous labels validate the effectiveness of our methods. Our code and a new dataset with high-quality demonstration samples on harmlessness are released.
Large language models (LLM) have recently attracted surging interest due to their outstanding capabilities across various domains. However, enabling efficient LLM inference is challenging due to its autoregressive decoding that generates tokens only one at a time. Although research works apply pruning or quantization to speed up LLM inference, they typically require fine-tuning the LLM, incurring significant time and economic costs. Meanwhile, speculative decoding has been proposed to use small speculative models (SSMs) to accelerate the inference of LLM. However, the low acceptance rate of SSM and the high verification cost of LLM prohibit further performance improvement of inference. In this paper, we propose Minions, an LLM inference system that accelerates LLM inference with a collective and adaptive speculative generation. Specifically, Minions proposes a majority-voted mechanism to leverage multiple SSMs to jointly speculate the outputs of LLM, which improves the inference performance without introducing prohibitive computation costs for LLM. To better trade off the number of tokens speculated from SSM and the verification cost of LLM, Minions proposes an adaptive mechanism to dynamically determine the optimal speculation length of SSM, which can achieve better inference performance across different models, datasets, and hyper-parameters. In addition, Minions decouples the SSM decoding and LLM verification efficiently and adopts a pipelined execution mechanism to further improve the inference performance of LLM. By comparing with the state-of-the-art LLM inference systems, we demonstrate that Minions can achieve higher inference throughput and lower inference time.
The growing integration of large language models (LLMs) into social operations amplifies their impact on decisions in crucial areas such as economics, law, education, and healthcare, raising public concerns about these models' discrimination-related safety and reliability. However, prior discrimination measuring frameworks solely assess the average discriminatory behavior of LLMs, often proving inadequate due to the overlook of an additional discrimination-leading factor, i.e., the LLMs' prediction variation across diverse contexts. In this work, we present the Prejudice-Caprice Framework (PCF) that comprehensively measures discrimination in LLMs by considering both their consistently biased preference and preference variation across diverse contexts. Specifically, we mathematically dissect the aggregated contextualized discrimination risk of LLMs into prejudice risk, originating from LLMs' persistent prejudice, and caprice risk, stemming from their generation inconsistency. In addition, we utilize a data-mining approach to gather preference-detecting probes from sentence skeletons, devoid of attribute indications, to approximate LLMs' applied contexts. While initially intended for assessing discrimination in LLMs, our proposed PCF facilitates the comprehensive and flexible measurement of any inductive biases, including knowledge alongside prejudice, across various modality models. We apply our discrimination-measuring framework to 12 common LLMs, yielding intriguing findings: i) modern LLMs demonstrate significant pro-male stereotypes, ii) LLMs' exhibited discrimination correlates with several social and economic factors, iii) prejudice risk dominates the overall discrimination risk and follows a normal distribution, and iv) caprice risk contributes minimally to the overall risk but follows a fat-tailed distribution, suggesting that it is wild risk requiring enhanced surveillance.
Large language models (LLMs) have made significant strides in reasoning capabilities, with ongoing efforts to refine their reasoning through self-correction. However, recent studies suggest that self-correction can be limited or even counterproductive without external accurate knowledge, raising questions about the limits and effectiveness of self-correction. In this paper, we aim to enhance LLM's self-checking capabilities by meticulously designing training data, thereby improving the accuracy of self-correction. We conduct a detailed analysis of error types in mathematical reasoning and develop a tailored prompt, termed "Step CoT Check". Then we construct a checking-correction dataset for training models. After integrating the original CoT data and checking-correction data for training, we observe that models could improve their self-checking capabilities, thereby enhancing their self-correction capacity and eliminating the need for external feedback or ground truth labels to ascertain the endpoint of correction. We compare the performance of models fine-tuned with the "Step CoT Check" prompt against those refined using other promps within the context of checking-correction data. The "Step CoT Check" outperforms the other two check formats in model with lager parameters, providing more precise feedback thus achieving a higher rate of correctness. For reproducibility, all the datasets and codes are provided in //github.com/bammt/Learn-to-check.
Retrieval-augmented language models (RALMs) have demonstrated significant potential in refining and expanding their internal memory by retrieving evidence from external sources. However, RALMs will inevitably encounter knowledge conflicts when integrating their internal memory with external sources. Knowledge conflicts can ensnare RALMs in a tug-of-war between knowledge, limiting their practical applicability. In this paper, we focus on exploring and resolving knowledge conflicts in RALMs. First, we present an evaluation framework for assessing knowledge conflicts across various dimensions. Then, we investigate the behavior and preference of RALMs from the following two perspectives: (1) Conflicts between internal memory and external sources: We find that stronger RALMs emerge with the Dunning-Kruger effect, persistently favoring their faulty internal memory even when correct evidence is provided. Besides, RALMs exhibit an availability bias towards common knowledge; (2) Conflicts between truthful, irrelevant and misleading evidence: We reveal that RALMs follow the principle of majority rule, leaning towards placing trust in evidence that appears more frequently. Moreover, we find that RALMs exhibit confirmation bias, and are more willing to choose evidence that is consistent with their internal memory. To solve the challenge of knowledge conflicts, we propose a method called Conflict-Disentangle Contrastive Decoding (CD2) to better calibrate the model's confidence. Experimental results demonstrate that our CD2 can effectively resolve knowledge conflicts in RALMs.
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine's Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture--observation, planning, and reflection--each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
Multimodality Representation Learning, as a technique of learning to embed information from different modalities and their correlations, has achieved remarkable success on a variety of applications, such as Visual Question Answering (VQA), Natural Language for Visual Reasoning (NLVR), and Vision Language Retrieval (VLR). Among these applications, cross-modal interaction and complementary information from different modalities are crucial for advanced models to perform any multimodal task, e.g., understand, recognize, retrieve, or generate optimally. Researchers have proposed diverse methods to address these tasks. The different variants of transformer-based architectures performed extraordinarily on multiple modalities. This survey presents the comprehensive literature on the evolution and enhancement of deep learning multimodal architectures to deal with textual, visual and audio features for diverse cross-modal and modern multimodal tasks. This study summarizes the (i) recent task-specific deep learning methodologies, (ii) the pretraining types and multimodal pretraining objectives, (iii) from state-of-the-art pretrained multimodal approaches to unifying architectures, and (iv) multimodal task categories and possible future improvements that can be devised for better multimodal learning. Moreover, we prepare a dataset section for new researchers that covers most of the benchmarks for pretraining and finetuning. Finally, major challenges, gaps, and potential research topics are explored. A constantly-updated paperlist related to our survey is maintained at //github.com/marslanm/multimodality-representation-learning.
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated in one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey specific to attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and open questions related to attention mechanism in general. Finally, we recommend possible future research directions for deep attention.
Automatic KB completion for commonsense knowledge graphs (e.g., ATOMIC and ConceptNet) poses unique challenges compared to the much studied conventional knowledge bases (e.g., Freebase). Commonsense knowledge graphs use free-form text to represent nodes, resulting in orders of magnitude more nodes compared to conventional KBs (18x more nodes in ATOMIC compared to Freebase (FB15K-237)). Importantly, this implies significantly sparser graph structures - a major challenge for existing KB completion methods that assume densely connected graphs over a relatively smaller set of nodes. In this paper, we present novel KB completion models that can address these challenges by exploiting the structural and semantic context of nodes. Specifically, we investigate two key ideas: (1) learning from local graph structure, using graph convolutional networks and automatic graph densification and (2) transfer learning from pre-trained language models to knowledge graphs for enhanced contextual representation of knowledge. We describe our method to incorporate information from both these sources in a joint model and provide the first empirical results for KB completion on ATOMIC and evaluation with ranking metrics on ConceptNet. Our results demonstrate the effectiveness of language model representations in boosting link prediction performance and the advantages of learning from local graph structure (+1.5 points in MRR for ConceptNet) when training on subgraphs for computational efficiency. Further analysis on model predictions shines light on the types of commonsense knowledge that language models capture well.
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191