


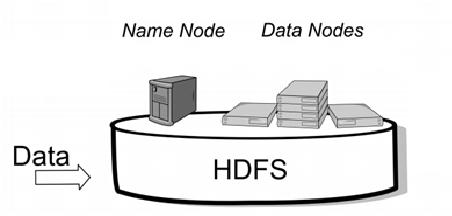
This paper introduces LogLead, a tool designed for efficient log analysis benchmarking. LogLead combines three essential steps in log processing: loading, enhancing, and anomaly detection. The tool leverages Polars, a high-speed DataFrame library. We currently have Loaders for eight systems that are publicly available (HDFS, Hadoop, BGL, Thunderbird, Spirit, Liberty, TrainTicket, and GC Webshop). We have multiple enhancers with three parsers (Drain, Spell, LenMa), Bert embedding creation and other log representation techniques like bag-of-words. LogLead integrates to five supervised and four unsupervised machine learning algorithms for anomaly detection from SKLearn. By integrating diverse datasets, log representation methods and anomaly detectors, LogLead facilitates comprehensive benchmarking in log analysis research. We show that log loading from raw file to dataframe is over 10x faster with LogLead compared to past solutions. We demonstrate roughly 2x improvement in Drain parsing speed by off-loading log message normalization to LogLead. Our brief benchmarking on HDFS indicates that log representations extending beyond the bag-of-words approach offer limited additional benefits. Tool URL: //github.com/EvoTestOps/LogLead
相關內容
Integration:Integration, the VLSI Journal。
Explanation:集成,VLSI雜志。
Publisher:Elsevier。
SIT:
This paper introduces Bespoke Non-Stationary (BNS) Solvers, a solver distillation approach to improve sample efficiency of Diffusion and Flow models. BNS solvers are based on a family of non-stationary solvers that provably subsumes existing numerical ODE solvers and consequently demonstrate considerable improvement in sample approximation (PSNR) over these baselines. Compared to model distillation, BNS solvers benefit from a tiny parameter space ($<$200 parameters), fast optimization (two orders of magnitude faster), maintain diversity of samples, and in contrast to previous solver distillation approaches nearly close the gap from standard distillation methods such as Progressive Distillation in the low-medium NFE regime. For example, BNS solver achieves 45 PSNR / 1.76 FID using 16 NFE in class-conditional ImageNet-64. We experimented with BNS solvers for conditional image generation, text-to-image generation, and text-2-audio generation showing significant improvement in sample approximation (PSNR) in all.
This paper introduces a universal federated learning framework that enables over-the-air computation via digital communications, using a new joint source-channel coding scheme. Without relying on channel state information at devices, this scheme employs lattice codes to both quantize model parameters and exploit interference from the devices. A novel two-layer receiver structure at the server is designed to reliably decode an integer combination of the quantized model parameters as a lattice point for the purpose of aggregation. Numerical experiments validate the effectiveness of the proposed scheme. Even with the challenges posed by channel conditions and device heterogeneity, the proposed scheme markedly surpasses other over-the-air FL strategies.
In this work, we introduce SureFED, a novel framework for byzantine robust federated learning. Unlike many existing defense methods that rely on statistically robust quantities, making them vulnerable to stealthy and colluding attacks, SureFED establishes trust using the local information of benign clients. SureFED utilizes an uncertainty aware model evaluation and introspection to safeguard against poisoning attacks. In particular, each client independently trains a clean local model exclusively using its local dataset, acting as the reference point for evaluating model updates. SureFED leverages Bayesian models that provide model uncertainties and play a crucial role in the model evaluation process. Our framework exhibits robustness even when the majority of clients are compromised, remains agnostic to the number of malicious clients, and is well-suited for non-IID settings. We theoretically prove the robustness of our algorithm against data and model poisoning attacks in a decentralized linear regression setting. Proof-of Concept evaluations on benchmark image classification data demonstrate the superiority of SureFED over the state of the art defense methods under various colluding and non-colluding data and model poisoning attacks.
Background: Modern Code Review (MCR) is a lightweight alternative to traditional code inspections. While secondary studies on MCR exist, it is unknown whether the research community has targeted themes that practitioners consider important. Objectives: The objectives are to provide an overview of MCR research, analyze the practitioners' opinions on the importance of MCR research, investigate the alignment between research and practice, and propose future MCR research avenues. Method: We conducted a systematic mapping study to survey state of the art until and including 2021, employed the Q-Methodology to analyze the practitioners' perception of the relevance of MCR research, and analyzed the primary studies' research impact. Results: We analyzed 244 primary studies, resulting in five themes. As a result of the 1,300 survey data points, we found that the respondents are positive about research investigating the impact of MCR on product quality and MCR process properties. In contrast, they are negative about human factor- and support systems-related research. Conclusion: These results indicate a misalignment between the state of the art and the themes deemed important by most survey respondents. Researchers should focus on solutions that can improve the state of MCR practice. We provide an MCR research agenda that can potentially increase the impact of MCR research.
Non-IID data present a tough challenge for federated learning. In this paper, we explore a novel idea of facilitating pairwise collaborations between clients with similar data. We propose FedAMP, a new method employing federated attentive message passing to facilitate similar clients to collaborate more. We establish the convergence of FedAMP for both convex and non-convex models, and propose a heuristic method to further improve the performance of FedAMP when clients adopt deep neural networks as personalized models. Our extensive experiments on benchmark data sets demonstrate the superior performance of the proposed methods.
Conventional methods for object detection typically require a substantial amount of training data and preparing such high-quality training data is very labor-intensive. In this paper, we propose a novel few-shot object detection network that aims at detecting objects of unseen categories with only a few annotated examples. Central to our method are our Attention-RPN, Multi-Relation Detector and Contrastive Training strategy, which exploit the similarity between the few shot support set and query set to detect novel objects while suppressing false detection in the background. To train our network, we contribute a new dataset that contains 1000 categories of various objects with high-quality annotations. To the best of our knowledge, this is one of the first datasets specifically designed for few-shot object detection. Once our few-shot network is trained, it can detect objects of unseen categories without further training or fine-tuning. Our method is general and has a wide range of potential applications. We produce a new state-of-the-art performance on different datasets in the few-shot setting. The dataset link is //github.com/fanq15/Few-Shot-Object-Detection-Dataset.
In this paper, we proposed to apply meta learning approach for low-resource automatic speech recognition (ASR). We formulated ASR for different languages as different tasks, and meta-learned the initialization parameters from many pretraining languages to achieve fast adaptation on unseen target language, via recently proposed model-agnostic meta learning algorithm (MAML). We evaluated the proposed approach using six languages as pretraining tasks and four languages as target tasks. Preliminary results showed that the proposed method, MetaASR, significantly outperforms the state-of-the-art multitask pretraining approach on all target languages with different combinations of pretraining languages. In addition, since MAML's model-agnostic property, this paper also opens new research direction of applying meta learning to more speech-related applications.
We introduce a multi-task setup of identifying and classifying entities, relations, and coreference clusters in scientific articles. We create SciERC, a dataset that includes annotations for all three tasks and develop a unified framework called Scientific Information Extractor (SciIE) for with shared span representations. The multi-task setup reduces cascading errors between tasks and leverages cross-sentence relations through coreference links. Experiments show that our multi-task model outperforms previous models in scientific information extraction without using any domain-specific features. We further show that the framework supports construction of a scientific knowledge graph, which we use to analyze information in scientific literature.
Most existing works in visual question answering (VQA) are dedicated to improving the accuracy of predicted answers, while disregarding the explanations. We argue that the explanation for an answer is of the same or even more importance compared with the answer itself, since it makes the question and answering process more understandable and traceable. To this end, we propose a new task of VQA-E (VQA with Explanation), where the computational models are required to generate an explanation with the predicted answer. We first construct a new dataset, and then frame the VQA-E problem in a multi-task learning architecture. Our VQA-E dataset is automatically derived from the VQA v2 dataset by intelligently exploiting the available captions. We have conducted a user study to validate the quality of explanations synthesized by our method. We quantitatively show that the additional supervision from explanations can not only produce insightful textual sentences to justify the answers, but also improve the performance of answer prediction. Our model outperforms the state-of-the-art methods by a clear margin on the VQA v2 dataset.
In this paper, we propose the joint learning attention and recurrent neural network (RNN) models for multi-label classification. While approaches based on the use of either model exist (e.g., for the task of image captioning), training such existing network architectures typically require pre-defined label sequences. For multi-label classification, it would be desirable to have a robust inference process, so that the prediction error would not propagate and thus affect the performance. Our proposed model uniquely integrates attention and Long Short Term Memory (LSTM) models, which not only addresses the above problem but also allows one to identify visual objects of interests with varying sizes without the prior knowledge of particular label ordering. More importantly, label co-occurrence information can be jointly exploited by our LSTM model. Finally, by advancing the technique of beam search, prediction of multiple labels can be efficiently achieved by our proposed network model.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191