


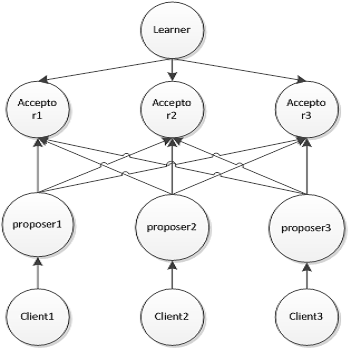
Session types are formal specifications of communication protocols, allowing protocol implementations to be verified by typechecking. Up to now, session type disciplines have assumed that the communication medium is reliable, with no loss of messages. However, unreliable broadcast communication is common in a wide class of distributed systems such as ad-hoc and wireless sensor networks. Often such systems have structured communication patterns that should be amenable to analysis by means of session types, but the necessary theory has not previously been developed. We introduce the Unreliable Broadcast Session Calculus, a process calculus with unreliable broadcast communication, and equip it with a session type system that we show is sound. We capture two common operations, broadcast and gather, inhabiting dual session types. Message loss may lead to non-synchronised session endpoints. To further account for unreliability we provide with an autonomous recovery mechanism that does not require acknowledgements from session participants. Our type system ensures soundness, safety, and progress between the synchronised endpoints within a session. We demonstrate the expressiveness of our framework by implementing Paxos, the textbook protocol for reaching consensus in an unreliable, asynchronous network.
相關內容
Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.
Camera localization methods based on retrieval, local feature matching, and 3D structure-based pose estimation are accurate but require high storage, are slow, and are not privacy-preserving. A method based on scene landmark detection (SLD) was recently proposed to address these limitations. It involves training a convolutional neural network (CNN) to detect a few predetermined, salient, scene-specific 3D points or landmarks and computing camera pose from the associated 2D-3D correspondences. Although SLD outperformed existing learning-based approaches, it was notably less accurate than 3D structure-based methods. In this paper, we show that the accuracy gap was due to insufficient model capacity and noisy labels during training. To mitigate the capacity issue, we propose to split the landmarks into subgroups and train a separate network for each subgroup. To generate better training labels, we propose using dense reconstructions to estimate visibility of scene landmarks. Finally, we present a compact architecture to improve memory efficiency. Accuracy wise, our approach is on par with state of the art structure based methods on the INDOOR-6 dataset but runs significantly faster and uses less storage. Code and models can be found at //github.com/microsoft/SceneLandmarkLocalization.
Despite advances in AI alignment, language models (LM) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries modify input prompts to induce harmful behavior. While some defenses have been proposed, they focus on narrow threat models and fall short of a strong defense, which we posit should be effective, universal, and practical. To achieve this, we propose the first adversarial objective for defending LMs against jailbreaking attacks and an algorithm, robust prompt optimization (RPO), that uses gradient-based token optimization to enforce harmless outputs. This results in an easily accessible suffix that significantly improves robustness to both jailbreaks seen during optimization and unknown, held-out jailbreaks, reducing the attack success rate on Starling-7B from 84% to 8.66% across 20 jailbreaks. In addition, we find that RPO has a minor effect on normal LM use, is successful under adaptive attacks, and can transfer to black-box models, reducing the success rate of the strongest attack on GPT-4 from 92% to 6%.
Guessing random additive noise decoding (GRAND) is a recently proposed decoding paradigm particularly suitable for codes with short length and high rate. Among its variants, ordered reliability bits GRAND (ORBGRAND) exploits soft information in a simple and effective fashion to schedule its queries, thereby allowing efficient hardware implementation. Compared with maximum likelihood (ML) decoding, however, ORBGRAND still exhibits noticeable performance gap in terms of block error rate (BLER). In order to improve the performance of ORBGRAND while still retaining its amenability to hardware implementation, a new variant of ORBGRAND termed RS-ORBGRAND is proposed, whose basic idea is to reshuffle the queries of ORBGRAND so that the expected number of queries is minimized. Numerical simulations show that RS-ORBGRAND leads to noticeable gains compared with ORBGRAND and its existing variants, and is only 0.1dB away from ML decoding, for BLER as low as $10^{-6}$.
Embedding methods transform the knowledge graph into a continuous, low-dimensional space, facilitating inference and completion tasks. Existing methods are mainly divided into two types: translational distance models and semantic matching models. A key challenge in translational distance models is their inability to effectively differentiate between 'head' and 'tail' entities in graphs. To address this problem, a novel location-sensitive embedding (LSE) method has been developed. LSE innovatively modifies the head entity using relation-specific mappings, conceptualizing relations as linear transformations rather than mere translations. The theoretical foundations of LSE, including its representational capabilities and its connections to existing models, have been thoroughly examined. A more streamlined variant, LSE-d, which employs a diagonal matrix for transformations to enhance practical efficiency, is also proposed. Experiments conducted on four large-scale KG datasets for link prediction show that LSEd either outperforms or is competitive with state-of-the-art related works.
Language models (LMs) have already demonstrated remarkable abilities in understanding and generating both natural and formal language. Despite these advances, their integration with real-world environments such as large-scale knowledge bases (KBs) remains an underdeveloped area, affecting applications such as semantic parsing and indulging in "hallucinated" information. This paper is an experimental investigation aimed at uncovering the robustness challenges that LMs encounter when tasked with knowledge base question answering (KBQA). The investigation covers scenarios with inconsistent data distribution between training and inference, such as generalization to unseen domains, adaptation to various language variations, and transferability across different datasets. Our comprehensive experiments reveal that even when employed with our proposed data augmentation techniques, advanced small and large language models exhibit poor performance in various dimensions. While the LM is a promising technology, the robustness of the current form in dealing with complex environments is fragile and of limited practicality because of the data distribution issue. This calls for future research on data collection and LM learning paradims.
In Bayesian peer-to-peer decentralized data fusion, the underlying distributions held locally by autonomous agents are frequently assumed to be over the same set of variables (homogeneous). This requires each agent to process and communicate the full global joint distribution, and thus leads to high computation and communication costs irrespective of relevancy to specific local objectives. This work formulates and studies heterogeneous decentralized fusion problems, defined as the set of problems in which either the communicated or the processed distributions describe different, but overlapping, random states of interest that are subsets of a larger full global joint state. We exploit the conditional independence structure of such problems and provide a rigorous derivation of novel exact and approximate conditionally factorized heterogeneous fusion rules. We further develop a new version of the homogeneous Channel Filter algorithm to enable conservative heterogeneous fusion for smoothing and filtering scenarios in dynamic problems. Numerical examples show more than $99.5\%$ potential communication reduction for heterogeneous channel filter fusion, and a multi-target tracking simulation shows that these methods provide consistent estimates while remaining computationally scalable.
Causality can be described in terms of a structural causal model (SCM) that carries information on the variables of interest and their mechanistic relations. For most processes of interest the underlying SCM will only be partially observable, thus causal inference tries to leverage any exposed information. Graph neural networks (GNN) as universal approximators on structured input pose a viable candidate for causal learning, suggesting a tighter integration with SCM. To this effect we present a theoretical analysis from first principles that establishes a novel connection between GNN and SCM while providing an extended view on general neural-causal models. We then establish a new model class for GNN-based causal inference that is necessary and sufficient for causal effect identification. Our empirical illustration on simulations and standard benchmarks validate our theoretical proofs.
We advocate the use of implicit fields for learning generative models of shapes and introduce an implicit field decoder for shape generation, aimed at improving the visual quality of the generated shapes. An implicit field assigns a value to each point in 3D space, so that a shape can be extracted as an iso-surface. Our implicit field decoder is trained to perform this assignment by means of a binary classifier. Specifically, it takes a point coordinate, along with a feature vector encoding a shape, and outputs a value which indicates whether the point is outside the shape or not. By replacing conventional decoders by our decoder for representation learning and generative modeling of shapes, we demonstrate superior results for tasks such as shape autoencoding, generation, interpolation, and single-view 3D reconstruction, particularly in terms of visual quality.
It is always well believed that modeling relationships between objects would be helpful for representing and eventually describing an image. Nevertheless, there has not been evidence in support of the idea on image description generation. In this paper, we introduce a new design to explore the connections between objects for image captioning under the umbrella of attention-based encoder-decoder framework. Specifically, we present Graph Convolutional Networks plus Long Short-Term Memory (dubbed as GCN-LSTM) architecture that novelly integrates both semantic and spatial object relationships into image encoder. Technically, we build graphs over the detected objects in an image based on their spatial and semantic connections. The representations of each region proposed on objects are then refined by leveraging graph structure through GCN. With the learnt region-level features, our GCN-LSTM capitalizes on LSTM-based captioning framework with attention mechanism for sentence generation. Extensive experiments are conducted on COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, GCN-LSTM increases CIDEr-D performance from 120.1% to 128.7% on COCO testing set.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191