

Along with the development of virtual reality (VR), omnidirectional images play an important role in producing multimedia content with immersive experience. However, despite various existing approaches for omnidirectional image stitching, how to quantitatively assess the quality of stitched images is still insufficiently explored. To address this problem, we establish a novel omnidirectional image dataset containing stitched images as well as dual-fisheye images captured from standard quarters of 0, 90, 180 and 270. In this manner, when evaluating the quality of an image stitched from a pair of fisheye images (e.g., 0 and 180), the other pair of fisheye images (e.g., 90 and 270) can be used as the cross-reference to provide ground-truth observations of the stitching regions. Based on this dataset, we further benchmark seven widely used stitching models with seven evaluation metrics for IQA. To the best of our knowledge, it is the first dataset that focuses on assessing the stitching quality of omnidirectional images.
相關內容
Recently, neural methods have achieved state-of-the-art (SOTA) results in Named Entity Recognition (NER) tasks for many languages without the need for manually crafted features. However, these models still require manually annotated training data, which is not available for many languages. In this paper, we propose an unsupervised cross-lingual NER model that can transfer NER knowledge from one language to another in a completely unsupervised way without relying on any bilingual dictionary or parallel data. Our model achieves this through word-level adversarial learning and augmented fine-tuning with parameter sharing and feature augmentation. Experiments on five different languages demonstrate the effectiveness of our approach, outperforming existing models by a good margin and setting a new SOTA for each language pair.
Text to Image Synthesis refers to the process of automatic generation of a photo-realistic image starting from a given text and is revolutionizing many real-world applications. In order to perform such process it is necessary to exploit datasets containing captioned images, meaning that each image is associated with one (or more) captions describing it. Despite the abundance of uncaptioned images datasets, the number of captioned datasets is limited. To address this issue, in this paper we propose an approach capable of generating images starting from a given text using conditional GANs trained on uncaptioned images dataset. In particular, uncaptioned images are fed to an Image Captioning Module to generate the descriptions. Then, the GAN Module is trained on both the input image and the machine-generated caption. To evaluate the results, the performance of our solution is compared with the results obtained by the unconditional GAN. For the experiments, we chose to use the uncaptioned dataset LSUN bedroom. The results obtained in our study are preliminary but still promising.
We consider the problem of referring image segmentation. Given an input image and a natural language expression, the goal is to segment the object referred by the language expression in the image. Existing works in this area treat the language expression and the input image separately in their representations. They do not sufficiently capture long-range correlations between these two modalities. In this paper, we propose a cross-modal self-attention (CMSA) module that effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the input image. In addition, we propose a gated multi-level fusion module to selectively integrate self-attentive cross-modal features corresponding to different levels in the image. This module controls the information flow of features at different levels. We validate the proposed approach on four evaluation datasets. Our proposed approach consistently outperforms existing state-of-the-art methods.
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
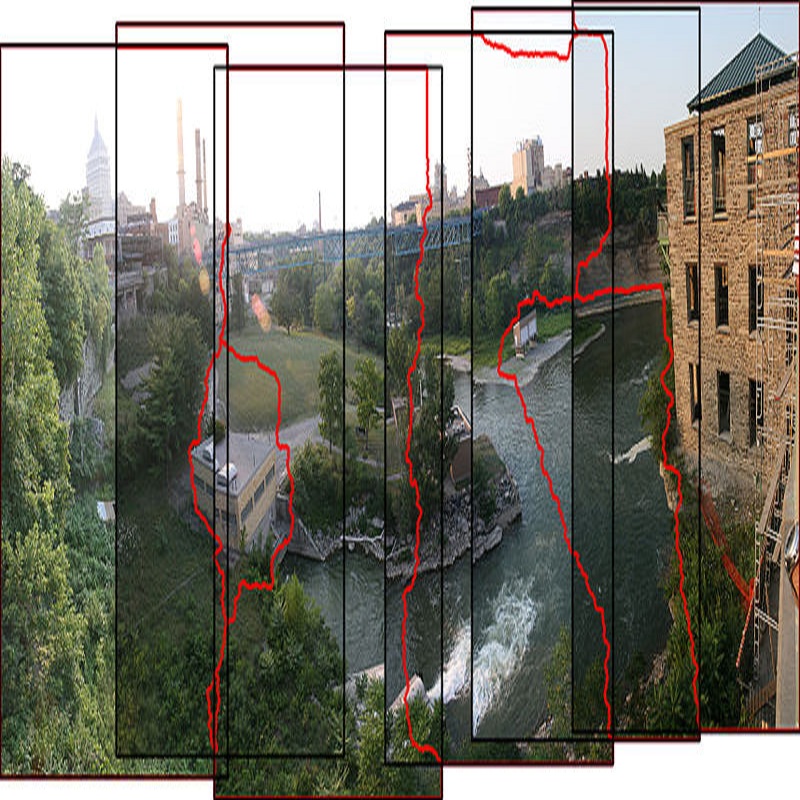
Seam-cutting and seam-driven techniques have been proven effective for handling imperfect image series in image stitching. Generally, seam-driven is to utilize seam-cutting to find a best seam from one or finite alignment hypotheses based on a predefined seam quality metric. However, the quality metrics in most methods are defined to measure the average performance of the pixels on the seam without considering the relevance and variance among them. This may cause that the seam with the minimal measure is not optimal (perception-inconsistent) in human perception. In this paper, we propose a novel coarse-to-fine seam estimation method which applies the evaluation in a different way. For pixels on the seam, we develop a patch-point evaluation algorithm concentrating more on the correlation and variation of them. The evaluations are then used to recalculate the difference map of the overlapping region and reestimate a stitching seam. This evaluation-reestimation procedure iterates until the current seam changes negligibly comparing with the previous seams. Experiments show that our proposed method can finally find a nearly perception-consistent seam after several iterations, which outperforms the conventional seam-cutting and other seam-driven methods.
Answering visual questions need acquire daily common knowledge and model the semantic connection among different parts in images, which is too difficult for VQA systems to learn from images with the only supervision from answers. Meanwhile, image captioning systems with beam search strategy tend to generate similar captions and fail to diversely describe images. To address the aforementioned issues, we present a system to have these two tasks compensate with each other, which is capable of jointly producing image captions and answering visual questions. In particular, we utilize question and image features to generate question-related captions and use the generated captions as additional features to provide new knowledge to the VQA system. For image captioning, our system attains more informative results in term of the relative improvements on VQA tasks as well as competitive results using automated metrics. Applying our system to the VQA tasks, our results on VQA v2 dataset achieve 65.8% using generated captions and 69.1% using annotated captions in validation set and 68.4% in the test-standard set. Further, an ensemble of 10 models results in 69.7% in the test-standard split.
Image captioning approaches currently generate descriptions which lack specific information, such as named entities that are involved in the images. In this paper we propose a new task which aims to generate informative image captions, given images and hashtags as input. We propose a simple, but effective approach in which we, first, train a CNN-LSTM model to generate a template caption based on the input image. Then we use a knowledge graph based collective inference algorithm to fill in the template with specific named entities retrieved via the hashtags. Experiments on a new benchmark dataset collected from Flickr show that our model generates news-style image descriptions with much richer information. The METEOR score of our model almost triples the score of the baseline image captioning model on our benchmark dataset, from 4.8 to 13.60.
Dense video captioning is a newly emerging task that aims at both localizing and describing all events in a video. We identify and tackle two challenges on this task, namely, (1) how to utilize both past and future contexts for accurate event proposal predictions, and (2) how to construct informative input to the decoder for generating natural event descriptions. First, previous works predominantly generate temporal event proposals in the forward direction, which neglects future video context. We propose a bidirectional proposal method that effectively exploits both past and future contexts to make proposal predictions. Second, different events ending at (nearly) the same time are indistinguishable in the previous works, resulting in the same captions. We solve this problem by representing each event with an attentive fusion of hidden states from the proposal module and video contents (e.g., C3D features). We further propose a novel context gating mechanism to balance the contributions from the current event and its surrounding contexts dynamically. We empirically show that our attentively fused event representation is superior to the proposal hidden states or video contents alone. By coupling proposal and captioning modules into one unified framework, our model outperforms the state-of-the-arts on the ActivityNet Captions dataset with a relative gain of over 100% (Meteor score increases from 4.82 to 9.65).
Improving Bi-directional Generation between Different Modalities with Variational Autoencoders
We investigate deep generative models that can exchange multiple modalities bi-directionally, e.g., generating images from corresponding texts and vice versa. A major approach to achieve this objective is to train a model that integrates all the information of different modalities into a joint representation and then to generate one modality from the corresponding other modality via this joint representation. We simply applied this approach to variational autoencoders (VAEs), which we call a joint multimodal variational autoencoder (JMVAE). However, we found that when this model attempts to generate a large dimensional modality missing at the input, the joint representation collapses and this modality cannot be generated successfully. Furthermore, we confirmed that this difficulty cannot be resolved even using a known solution. Therefore, in this study, we propose two models to prevent this difficulty: JMVAE-kl and JMVAE-h. Results of our experiments demonstrate that these methods can prevent the difficulty above and that they generate modalities bi-directionally with equal or higher likelihood than conventional VAE methods, which generate in only one direction. Moreover, we confirm that these methods can obtain the joint representation appropriately, so that they can generate various variations of modality by moving over the joint representation or changing the value of another modality.
小貼士
登錄享
相關主題




注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191