
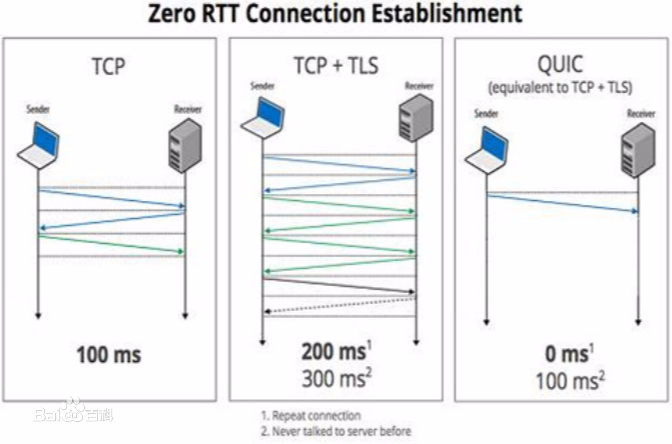

Recent years have seen a rapid increase in the number of CubeSats and other small satellites in orbit - these have highly constrained computational and communication resources, but still require robust secure communication to operate effectively. The QUIC transport layer protocol is designed to provide efficient communication with cryptography guarantees built-in, with a particular focus on networks with high latency and packet loss. In this work we provide spaceQUIC, a proof of concept implementation of QUIC for NASA's "core Flight System" satellite operating system, and assess its performance.
相關內容
Recent generalizations of the Hopfield model of associative memories are able to store a number $P$ of random patterns that grows exponentially with the number $N$ of neurons, $P=\exp(\alpha N)$. Besides the huge storage capacity, another interesting feature of these networks is their connection to the attention mechanism which is part of the Transformer architectures widely applied in deep learning. In this work, we consider a generic family of pattern ensembles, and thanks to the statistical mechanics analysis of an auxiliary Random Energy Model, we are able to provide exact asymptotic thresholds for the retrieval of a typical pattern, $\alpha_1$, and lower bounds for the maximum of the load $\alpha$ for which all patterns can be retrieved, $\alpha_c$. Additionally, we characterize the size of the basins of attractions. We discuss in detail the cases of Gaussian and spherical patterns, and show that they display rich and qualitatively different phase diagrams.
Deep learning is also known as hierarchical learning, where the learner _learns_ to represent a complicated target function by decomposing it into a sequence of simpler functions to reduce sample and time complexity. This paper formally analyzes how multi-layer neural networks can perform such hierarchical learning _efficiently_ and _automatically_ by SGD on the training objective. On the conceptual side, we present a theoretical characterizations of how certain types of deep (i.e. super-constant layer) neural networks can still be sample and time efficiently trained on some hierarchical tasks, when no existing algorithm (including layerwise training, kernel method, etc) is known to be efficient. We establish a new principle called "backward feature correction", where the errors in the lower-level features can be automatically corrected when training together with the higher-level layers. We believe this is a key behind how deep learning is performing deep (hierarchical) learning, as opposed to layerwise learning or simulating some non-hierarchical method. On the technical side, we show for every input dimension $d > 0$, there is a concept class of degree $\omega(1)$ multi-variate polynomials so that, using $\omega(1)$-layer neural networks as learners, SGD can learn any function from this class in $\mathsf{poly}(d)$ time to any $\frac{1}{\mathsf{poly}(d)}$ error, through learning to represent it as a composition of $\omega(1)$ layers of quadratic functions using "backward feature correction." In contrast, we do not know any other simpler algorithm (including layerwise training, applying kernel method sequentially, training a two-layer network, etc) that can learn this concept class in $\mathsf{poly}(d)$ time even to any $d^{-0.01}$ error. As a side result, we prove $d^{\omega(1)}$ lower bounds for several non-hierarchical learners, including any kernel methods.
Semantic communication has gained significant attention from researchers as a promising technique to replace conventional communication in the next generation of communication systems, primarily due to its ability to reduce communication costs. However, little literature has studied its effectiveness in multi-user scenarios, particularly when there are variations in the model architectures used by users and their computing capacities. To address this issue, we explore a semantic communication system that caters to multiple users with different model architectures by using a multi-purpose transmitter at the base station (BS). Specifically, the BS in the proposed framework employs semantic and channel encoders to encode the image for transmission, while the receiver utilizes its local channel and semantic decoder to reconstruct the original image. Our joint source-channel encoder at the BS can effectively extract and compress semantic features for specific users by considering the signal-to-noise ratio (SNR) and computing capacity of the user. Based on the network status, the joint source-channel encoder at the BS can adaptively adjust the length of the transmitted signal. A longer signal ensures more information for high-quality image reconstruction for the user, while a shorter signal helps avoid network congestion. In addition, we propose a hybrid loss function for training, which enhances the perceptual details of reconstructed images. Finally, we conduct a series of extensive evaluations and ablation studies to validate the effectiveness of the proposed system.
Order execution is a fundamental task in quantitative finance, aiming at finishing acquisition or liquidation for a number of trading orders of the specific assets. Recent advance in model-free reinforcement learning (RL) provides a data-driven solution to the order execution problem. However, the existing works always optimize execution for an individual order, overlooking the practice that multiple orders are specified to execute simultaneously, resulting in suboptimality and bias. In this paper, we first present a multi-agent RL (MARL) method for multi-order execution considering practical constraints. Specifically, we treat every agent as an individual operator to trade one specific order, while keeping communicating with each other and collaborating for maximizing the overall profits. Nevertheless, the existing MARL algorithms often incorporate communication among agents by exchanging only the information of their partial observations, which is inefficient in complicated financial market. To improve collaboration, we then propose a learnable multi-round communication protocol, for the agents communicating the intended actions with each other and refining accordingly. It is optimized through a novel action value attribution method which is provably consistent with the original learning objective yet more efficient. The experiments on the data from two real-world markets have illustrated superior performance with significantly better collaboration effectiveness achieved by our method.
Social media and user-generated content (UGC) have become increasingly important features of journalistic work in a number of different ways. However, the growth of misinformation means that news organisations have had devote more and more resources to determining its veracity and to publishing corrections if it is found to be misleading. In this work, we present the results of interviews with eight members of fact-checking teams from two organisations. Team members described their fact-checking processes and the challenges they currently face in completing a fact-check in a robust and timely way. The former reveals, inter alia, significant differences in fact-checking practices and the role played by collaboration between team members. We conclude with a discussion of the implications for the development and application of computational tools, including where computational tool support is currently lacking and the importance of being able to accommodate different fact-checking practices.
Using Artificial Neural Networks (ANN) for nonlinear system identification has proven to be a promising approach, but despite of all recent research efforts, many practical and theoretical problems still remain open. Specifically, noise handling and models, issues of consistency and reliable estimation under minimisation of the prediction error are the most severe problems. The latter comes with numerous practical challenges such as explosion of the computational cost in terms of the number of data samples and the occurrence of instabilities during optimization. In this paper, we aim to overcome these issues by proposing a method which uses a truncated prediction loss and a subspace encoder for state estimation. The truncated prediction loss is computed by selecting multiple truncated subsections from the time series and computing the average prediction loss. To obtain a computationally efficient estimation method that minimizes the truncated prediction loss, a subspace encoder represented by an artificial neural network is introduced. This encoder aims to approximate the state reconstructability map of the estimated model to provide an initial state for each truncated subsection given past inputs and outputs. By theoretical analysis, we show that, under mild conditions, the proposed method is locally consistent, increases optimization stability, and achieves increased data efficiency by allowing for overlap between the subsections. Lastly, we provide practical insights and user guidelines employing a numerical example and state-of-the-art benchmark results.
The FormAI Dataset: Generative AI in Software Security Through the Lens of Formal Verification
This paper presents the FormAI dataset, a large collection of 112,000 AI-generated compilable and independent C programs with vulnerability classification. We introduce a dynamic zero-shot prompting technique, constructed to spawn a diverse set of programs utilizing Large Language Models (LLMs). The dataset is generated by GPT-3.5-turbo and comprises programs with varying levels of complexity. Some programs handle complicated tasks such as network management, table games, or encryption, while others deal with simpler tasks like string manipulation. Every program is labeled with the vulnerabilities found within the source code, indicating the type, line number, and vulnerable function name. This is accomplished by employing a formal verification method using the Efficient SMT-based Bounded Model Checker (ESBMC), which performs model checking, abstract interpretation, constraint programming, and satisfiability modulo theories, to reason over safety/security properties in programs. This approach definitively detects vulnerabilities and offers a formal model known as a counterexample, thus eliminating the possibility of generating false positive reports. This property of the dataset makes it suitable for evaluating the effectiveness of various static and dynamic analysis tools. Furthermore, we have associated the identified vulnerabilities with relevant Common Weakness Enumeration (CWE) numbers. We make the source code available for the 112,000 programs, accompanied by a comprehensive list detailing the vulnerabilities detected in each individual program including location and function name, which makes the dataset ideal to train LLMs and machine learning algorithms.
The hardware computing landscape is changing. What used to be distributed systems can now be found on a chip with highly configurable, diverse, specialized and general purpose units. Such Systems-on-a-Chip (SoC) are used to control today's cyber-physical systems, being the building blocks of critical infrastructures. They are deployed in harsh environments and are connected to the cyberspace, which makes them exposed to both accidental faults and targeted cyberattacks. This is in addition to the changing fault landscape that continued technology scaling, emerging devices and novel application scenarios will bring. In this paper, we discuss how the very features, distributed, parallelized, reconfigurable, heterogeneous, that cause many of the imminent and emerging security and resilience challenges, also open avenues for their cure though SoC replication, diversity, rejuvenation, adaptation, and hybridization. We show how to leverage these techniques at different levels across the entire SoC hardware/software stack, calling for more research on the topic.
The Data Science domain has expanded monumentally in both research and industry communities during the past decade, predominantly owing to the Big Data revolution. Artificial Intelligence (AI) and Machine Learning (ML) are bringing more complexities to data engineering applications, which are now integrated into data processing pipelines to process terabytes of data. Typically, a significant amount of time is spent on data preprocessing in these pipelines, and hence improving its e fficiency directly impacts the overall pipeline performance. The community has recently embraced the concept of Dataframes as the de-facto data structure for data representation and manipulation. However, the most widely used serial Dataframes today (R, pandas) experience performance limitations while working on even moderately large data sets. We believe that there is plenty of room for improvement by taking a look at this problem from a high-performance computing point of view. In a prior publication, we presented a set of parallel processing patterns for distributed dataframe operators and the reference runtime implementation, Cylon [1]. In this paper, we are expanding on the initial concept by introducing a cost model for evaluating the said patterns. Furthermore, we evaluate the performance of Cylon on the ORNL Summit supercomputer.
Deep neural networks (DNNs) have succeeded in many different perception tasks, e.g., computer vision, natural language processing, reinforcement learning, etc. The high-performed DNNs heavily rely on intensive resource consumption. For example, training a DNN requires high dynamic memory, a large-scale dataset, and a large number of computations (a long training time); even inference with a DNN also demands a large amount of static storage, computations (a long inference time), and energy. Therefore, state-of-the-art DNNs are often deployed on a cloud server with a large number of super-computers, a high-bandwidth communication bus, a shared storage infrastructure, and a high power supplement. Recently, some new emerging intelligent applications, e.g., AR/VR, mobile assistants, Internet of Things, require us to deploy DNNs on resource-constrained edge devices. Compare to a cloud server, edge devices often have a rather small amount of resources. To deploy DNNs on edge devices, we need to reduce the size of DNNs, i.e., we target a better trade-off between resource consumption and model accuracy. In this dissertation, we studied four edge intelligence scenarios, i.e., Inference on Edge Devices, Adaptation on Edge Devices, Learning on Edge Devices, and Edge-Server Systems, and developed different methodologies to enable deep learning in each scenario. Since current DNNs are often over-parameterized, our goal is to find and reduce the redundancy of the DNNs in each scenario.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191