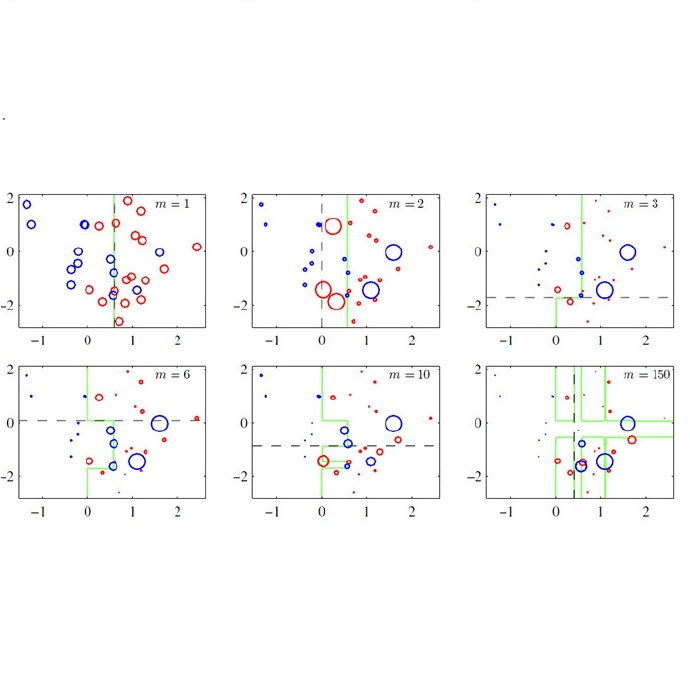

Gradient Boosting Machines (GBMs) have demonstrated remarkable success in solving diverse problems by utilizing Taylor expansions in functional space. However, achieving a balance between performance and generality has posed a challenge for GBMs. In particular, gradient descent-based GBMs employ the first-order Taylor expansion to ensure applicability to all loss functions, while Newton's method-based GBMs use positive Hessian information to achieve superior performance at the expense of generality. To address this issue, this study proposes a new generic Gradient Boosting Machine called Trust-region Boosting (TRBoost). In each iteration, TRBoost uses a constrained quadratic model to approximate the objective and applies the Trust-region algorithm to solve it and obtain a new learner. Unlike Newton's method-based GBMs, TRBoost does not require the Hessian to be positive definite, thereby allowing it to be applied to arbitrary loss functions while still maintaining competitive performance similar to second-order algorithms. The convergence analysis and numerical experiments conducted in this study confirm that TRBoost is as general as first-order GBMs and yields competitive results compared to second-order GBMs. Overall, TRBoost is a promising approach that balances performance and generality, making it a valuable addition to the toolkit of machine learning practitioners.
相關內容
Rapid developments in artificial intelligence technology have led to unmanned systems replacing human beings in many fields requiring high-precision predictions and decisions. In modern operational environments, all job plans are affected by emergency events such as equipment failures and resource shortages, making a quick resolution critical. The use of unmanned systems to assist decision-making can improve resolution efficiency, but their decision-making is not interpretable and may make the wrong decisions. Current unmanned systems require human supervision and control. Based on this, we propose a collaborative human--machine method for resolving unplanned events using two phases: task filtering and task scheduling. In the task filtering phase, we propose a human--machine collaborative decision-making algorithm for dynamic tasks. The GACRNN model is used to predict the state of the job nodes, locate the key nodes, and generate a machine-predicted resolution task list. A human decision-maker supervises the list in real time and modifies and confirms the machine-predicted list through the human--machine interface. In the task scheduling phase, we propose a scheduling algorithm that integrates human experience constraints. The steps to resolve an event are inserted into the normal job sequence to schedule the resolution. We propose several human--machine collaboration methods in each phase to generate steps to resolve an unplanned event while minimizing the impact on the original job plan.
We consider stochastic approximations of sampling algorithms, such as Stochastic Gradient Langevin Dynamics (SGLD) and the Random Batch Method (RBM) for Interacting Particle Dynamcs (IPD). We observe that the noise introduced by the stochastic approximation is nearly Gaussian due to the Central Limit Theorem (CLT) while the driving Brownian motion is exactly Gaussian. We harness this structure to absorb the stochastic approximation error inside the diffusion process, and obtain improved convergence guarantees for these algorithms. For SGLD, we prove the first stable convergence rate in KL divergence without requiring uniform warm start, assuming the target density satisfies a Log-Sobolev Inequality. Our result implies superior first-order oracle complexity compared to prior works, under significantly milder assumptions. We also prove the first guarantees for SGLD under even weaker conditions such as H\"{o}lder smoothness and Poincare Inequality, thus bridging the gap between the state-of-the-art guarantees for LMC and SGLD. Our analysis motivates a new algorithm called covariance correction, which corrects for the additional noise introduced by the stochastic approximation by rescaling the strength of the diffusion. Finally, we apply our techniques to analyze RBM, and significantly improve upon the guarantees in prior works (such as removing exponential dependence on horizon), under minimal assumptions.

The great success neural networks have achieved is inseparable from the application of gradient-descent (GD) algorithms. Based on GD, many variant algorithms have emerged to improve the GD optimization process. The gradient for back-propagation is apparently the most crucial aspect for the training of a neural network. The quality of the calculated gradient can be affected by multiple aspects, e.g., noisy data, calculation error, algorithm limitation, and so on. To reveal gradient information beyond gradient descent, we introduce a framework (\textbf{GCGD}) to perform gradient correction. GCGD consists of two plug-in modules: 1) inspired by the idea of gradient prediction, we propose a \textbf{GC-W} module for weight gradient correction; 2) based on Neural ODE, we propose a \textbf{GC-ODE} module for hidden states gradient correction. Experiment results show that our gradient correction framework can effectively improve the gradient quality to reduce training epochs by $\sim$ 20\% and also improve the network performance.
This paper proposes a new easy-to-implement parameter-free gradient-based optimizer: DoWG (Distance over Weighted Gradients). We prove that DoWG is efficient -- matching the convergence rate of optimally tuned gradient descent in convex optimization up to a logarithmic factor without tuning any parameters, and universal -- automatically adapting to both smooth and nonsmooth problems. While popular algorithms such as AdaGrad, Adam, or DoG compute a running average of the squared gradients, DoWG maintains a new distance-based weighted version of the running average, which is crucial to achieve the desired properties. To our best knowledge, DoWG is the first parameter-free, efficient, and universal algorithm that does not require backtracking search procedures. It is also the first parameter-free AdaGrad style algorithm that adapts to smooth optimization. To complement our theory, we also show empirically that DoWG trains at the edge of stability, and validate its effectiveness on practical machine learning tasks. This paper further uncovers the underlying principle behind the success of the AdaGrad family of algorithms by presenting a novel analysis of Normalized Gradient Descent (NGD), that shows NGD adapts to smoothness when it exists, with no change to the stepsize. This establishes the universality of NGD and partially explains the empirical observation that it trains at the edge of stability in a much more general setup compared to standard gradient descent. The latter might be of independent interest to the community.
Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.
Sampling-based planning algorithm is a powerful tool for solving planning problems in high-dimensional state spaces. In this article, we present a novel approach to sampling in the most promising regions, which significantly reduces planning time-consumption. The RRT# algorithm defines the Relevant Region based on the cost-to-come provided by the optimal forward-searching tree. However, it uses the cumulative cost of a direct connection between the current state and the goal state as the cost-to-go. To improve the path planning efficiency, we propose a batch sampling method that samples in a refined Relevant Region with a direct sampling strategy, which is defined according to the optimal cost-to-come and the adaptive cost-to-go, taking advantage of various sources of heuristic information. The proposed sampling approach allows the algorithm to build the search tree in the direction of the most promising area, resulting in a superior initial solution quality and reducing the overall computation time compared to related work. To validate the effectiveness of our method, we conducted several simulations in both $SE(2)$ and $SE(3)$ state spaces. And the simulation results demonstrate the superiorities of proposed algorithm.
With the ever-increasing computing power of supercomputers and the growing scale of scientific applications, the efficiency of MPI collective communications turns out to be a critical bottleneck in large-scale distributed and parallel processing. Large message size in MPI collectives is a particularly big concern because it may significantly delay the overall parallel performance. To address this issue, prior research simply applies the off-the-shelf fix-rate lossy compressors in the MPI collectives, leading to suboptimal performance, limited generalizability, and unbounded errors. In this paper, we propose a novel solution, called C-Coll, which leverages error-bounded lossy compression to significantly reduce the message size, resulting in a substantial reduction in communication cost. The key contributions are three-fold. (1) We develop two general, optimized lossy-compression-based frameworks for both types of MPI collectives (collective data movement as well as collective computation), based on their particular characteristics. Our framework not only reduces communication cost but also preserves data accuracy. (2) We customize an optimized version based on SZx, an ultra-fast error-bounded lossy compressor, which can meet the specific needs of collective communication. (3) We integrate C-Coll into multiple collectives, such as MPI_Allreduce, MPI_Scatter, and MPI_Bcast, and perform a comprehensive evaluation based on real-world scientific datasets. Experiments show that our solution outperforms the original MPI collectives as well as multiple baselines and related efforts by 3.5-9.7X.
Localization systems based on ultra-wide band (UWB) measurements can have unsatisfactory performance in harsh environments due to the presence of non-line-of-sight (NLOS) errors. Learning-based methods for error mitigation have shown great performance improvement via directly exploiting the wideband waveform instead of handcrafted features. However, these methods require data samples fully labeled with actual measurement errors for training, which leads to time-consuming data collection. In this paper, we propose a semi-supervised learning method based on variational Bayes for UWB ranging error mitigation. Combining deep learning techniques and statistic tools, our method can efficiently accumulate knowledge from both labeled and unlabeled data samples. Extensive experiments illustrate the effectiveness of the proposed method under different supervision rates, and the superiority compared to other fully supervised methods even at a low supervision rate.
Graph convolutional neural networks have recently shown great potential for the task of zero-shot learning. These models are highly sample efficient as related concepts in the graph structure share statistical strength allowing generalization to new classes when faced with a lack of data. However, multi-layer architectures, which are required to propagate knowledge to distant nodes in the graph, dilute the knowledge by performing extensive Laplacian smoothing at each layer and thereby consequently decrease performance. In order to still enjoy the benefit brought by the graph structure while preventing dilution of knowledge from distant nodes, we propose a Dense Graph Propagation (DGP) module with carefully designed direct links among distant nodes. DGP allows us to exploit the hierarchical graph structure of the knowledge graph through additional connections. These connections are added based on a node's relationship to its ancestors and descendants. A weighting scheme is further used to weigh their contribution depending on the distance to the node to improve information propagation in the graph. Combined with finetuning of the representations in a two-stage training approach our method outperforms state-of-the-art zero-shot learning approaches.
Most previous event extraction studies have relied heavily on features derived from annotated event mentions, thus cannot be applied to new event types without annotation effort. In this work, we take a fresh look at event extraction and model it as a grounding problem. We design a transferable neural architecture, mapping event mentions and types jointly into a shared semantic space using structural and compositional neural networks, where the type of each event mention can be determined by the closest of all candidate types . By leveraging (1)~available manual annotations for a small set of existing event types and (2)~existing event ontologies, our framework applies to new event types without requiring additional annotation. Experiments on both existing event types (e.g., ACE, ERE) and new event types (e.g., FrameNet) demonstrate the effectiveness of our approach. \textit{Without any manual annotations} for 23 new event types, our zero-shot framework achieved performance comparable to a state-of-the-art supervised model which is trained from the annotations of 500 event mentions.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191