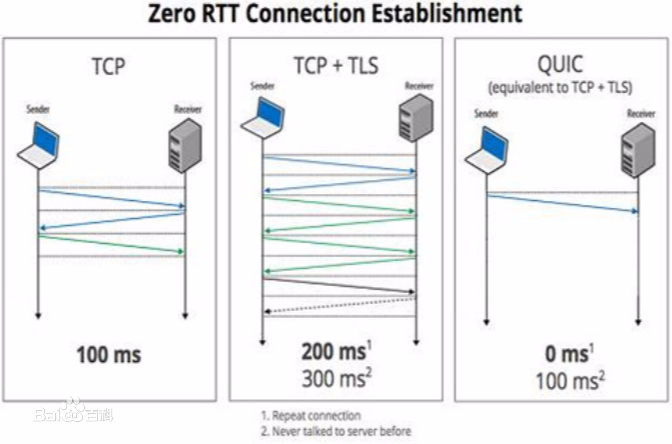

TCP and QUIC can both leverage ECN to avoid congestion loss and its retransmission overhead. However, both protocols require support of their remote endpoints and it took two decades since the initial standardization of ECN for TCP to reach 80% ECN support and more in the wild. In contrast, the QUIC standard mandates ECN support, but there are notable ambiguities that make it unclear if and how ECN can actually be used with QUIC on the Internet. Hence, in this paper, we analyze ECN support with QUIC in the wild: We conduct repeated measurements on more than 180M domains to identify HTTP/3 websites and analyze the underlying QUIC connections w.r.t. ECN support. We only find 20% of QUIC hosts, providing 6% of HTTP/3 websites, to mirror client ECN codepoints. Yet, mirroring ECN is only half of what is required for ECN with QUIC, as QUIC validates mirrored ECN codepoints to detect network impairments: We observe that less than 2% of QUIC hosts, providing less than 0.3% of HTTP/3 websites, pass this validation. We identify possible root causes in content providers not supporting ECN via QUIC and network impairments hindering ECN. We thus also characterize ECN with QUIC distributedly to traverse other paths and discuss our results w.r.t. QUIC and ECN innovations beyond QUIC.
相關內容
The surge in counterfeit signatures has inflicted widespread inconveniences and formidable challenges for both individuals and organizations. This groundbreaking research paper introduces SigScatNet, an innovative solution to combat this issue by harnessing the potential of a Siamese deep learning network, bolstered by Scattering wavelets, to detect signature forgery and assess signature similarity. The Siamese Network empowers us to ascertain the authenticity of signatures through a comprehensive similarity index, enabling precise validation and comparison. Remarkably, the integration of Scattering wavelets endows our model with exceptional efficiency, rendering it light enough to operate seamlessly on cost-effective hardware systems. To validate the efficacy of our approach, extensive experimentation was conducted on two open-sourced datasets: the ICDAR SigComp Dutch dataset and the CEDAR dataset. The experimental results demonstrate the practicality and resounding success of our proposed SigScatNet, yielding an unparalleled Equal Error Rate of 3.689% with the ICDAR SigComp Dutch dataset and an astonishing 0.0578% with the CEDAR dataset. Through the implementation of SigScatNet, our research spearheads a new state-of-the-art in signature analysis in terms of EER scores and computational efficiency, offering an advanced and accessible solution for detecting forgery and quantifying signature similarities. By employing cutting-edge Siamese deep learning and Scattering wavelets, we provide a robust framework that paves the way for secure and efficient signature verification systems.
With the development of trustworthy Federated Learning (FL), the requirement of implementing right to be forgotten gives rise to the area of Federated Unlearning (FU). Comparing to machine unlearning, a major challenge of FU lies in the decentralized and privacy-preserving nature of FL, in which clients jointly train a global model without sharing their raw data, making it substantially more intricate to selectively unlearn specific information. In that regard, many efforts have been made to tackle the challenges of FU and have achieved significant progress. In this paper, we present a comprehensive survey of FU. Specially, we provide the existing algorithms, objectives, evaluation metrics, and identify some challenges of FU. By reviewing and comparing some studies, we summarize them into a taxonomy for various schemes, potential applications and future directions.

Line attributes such as width and dashing are commonly used to encode information. However, many questions on the perception of line attributes remain, such as how many levels of attribute variation can be distinguished or which line attributes are the preferred choices for which tasks. We conducted three studies to develop guidelines for using stylized lines to encode scalar data. In our first study, participants drew stylized lines to encode uncertainty information. Uncertainty is usually visualized alongside other data. Therefore, alternative visual channels are important for the visualization of uncertainty. Additionally, uncertainty -- e.g., in weather forecasts -- is a familiar topic to most people. Thus, we picked it for our visualization scenarios in study 1. We used the results of our study to determine the most common line attributes for drawing uncertainty: Dashing, luminance, wave amplitude, and width. While those line attributes were especially common for drawing uncertainty, they are also commonly used in other areas. In studies 2 and 3, we investigated the discriminability of the line attributes determined in study 1. Studies 2 and 3 did not require specific application areas; thus, their results apply to visualizing any scalar data in line attributes. We evaluated the just-noticeable differences (JND) and derived recommendations for perceptually distinct line levels. We found that participants could discriminate considerably more levels for the line attribute width than for wave amplitude, dashing, or luminance.
Open Radio Access Networks (RAN) offer diverse economic opportunities. A transition to a flexible, modular approach within the disaggregated RAN framework is crucial, involving careful planning of RAN architecture and the deployment of specialized software applications. Collaboration across sectors is essential for efficiency and reliability, with the open-source community driving innovation. This paper explores challenges for third-party application developers in Open RAN. It provides a comparative analysis of solutions, focusing on xApp development and implementation. Challenges arise in two areas: the complexities of xApp development, particularly for advanced use cases like beam management, and issues in low-level software implementation within open platforms. In conclusion, key challenges must promote academia-industry collaboration in Open RAN. This paper shares early lessons from xApp development, guiding the field's evolution.
[Context]: Companies are increasingly recognizing the importance of automating Requirements Engineering (RE) tasks due to their resource-intensive nature. The advent of GenAI has made these tasks more amenable to automation, thanks to its ability to understand and interpret context effectively. [Problem]: However, in the context of GenAI, prompt engineering is a critical factor for success. Despite this, we currently lack tools and methods to systematically assess and determine the most effective prompt patterns to employ for a particular RE task. [Method]: Two tasks related to requirements, specifically requirement classification and tracing, were automated using the GPT-3.5 turbo API. The performance evaluation involved assessing various prompts created using 5 prompt patterns and implemented programmatically to perform the selected RE tasks, focusing on metrics such as precision, recall, accuracy, and F-Score. [Results]: This paper evaluates the effectiveness of the 5 prompt patterns' ability to make GPT-3.5 turbo perform the selected RE tasks and offers recommendations on which prompt pattern to use for a specific RE task. Additionally, it also provides an evaluation framework as a reference for researchers and practitioners who want to evaluate different prompt patterns for different RE tasks.
Galerkin-based reduced-order models (G-ROMs) have provided efficient and accurate approximations of laminar flows. In order to capture the complex dynamics of the turbulent flows, standard G-ROMs require a relatively large number of reduced basis functions (on the order of hundreds and even thousands). Although the resulting G-ROM is still relatively low-dimensional compared to the full-order model (FOM), its computational cost becomes prohibitive due to the 3rd-order convection tensor contraction. The tensor requires storage of $N^3$ entries with a corresponding work of $2N^3$ operations per timestep, which makes such ROMs impossible to use in realistic applications, such as control of turbulent flows. In this paper, we focus on the scenario where the G-ROM requires large $N$ values and propose a novel approach that utilizes the CANDECOMC/PARAFAC decomposition (CPD), a tensor decomposition technique, to accelerate the G-ROM by approximating the 3rd-order convection tensor by a sum of $R$ rank-1 tensors. In addition, we show that the tensor is partially skew-symmetric and derive two conditions for the CP decomposition for preserving the skew-symmetry. Moreover, we investigate the G-ROM with the singular value decomposition (SVD). The G-ROM with CP decomposition is investigated in several flow configurations from 2D periodic flow to 3D turbulent flows. Our numerical investigation shows CPD-ROM achieves at least a factor of 10 speedup. Additionally, the skew-symmetry preserving CPD-ROM is more stable and allows the usage of smaller rank $R$. Moreover, from the singular value behavior, the advection tensor formed using the $H^1_0$-POD basis has a low-rank structure, and is preserved even in higher Reynolds numbers. Furthermore, for a given level of accuracy, the CP decomposition is more efficient in size and cost than the SVD.
Like many optimizers, Bayesian optimization often falls short of gaining user trust due to opacity. While attempts have been made to develop human-centric optimizers, they typically assume user knowledge is well-specified and error-free, employing users mainly as supervisors of the optimization process. We relax these assumptions and propose a more balanced human-AI partnership with our Collaborative and Explainable Bayesian Optimization (CoExBO) framework. Instead of explicitly requiring a user to provide a knowledge model, CoExBO employs preference learning to seamlessly integrate human insights into the optimization, resulting in algorithmic suggestions that resonate with user preference. CoExBO explains its candidate selection every iteration to foster trust, empowering users with a clearer grasp of the optimization. Furthermore, CoExBO offers a no-harm guarantee, allowing users to make mistakes; even with extreme adversarial interventions, the algorithm converges asymptotically to a vanilla Bayesian optimization. We validate CoExBO's efficacy through human-AI teaming experiments in lithium-ion battery design, highlighting substantial improvements over conventional methods.
Australia is a leading AI nation with strong allies and partnerships. Australia has prioritised robotics, AI, and autonomous systems to develop sovereign capability for the military. Australia commits to Article 36 reviews of all new means and methods of warfare to ensure weapons and weapons systems are operated within acceptable systems of control. Additionally, Australia has undergone significant reviews of the risks of AI to human rights and within intelligence organisations and has committed to producing ethics guidelines and frameworks in Security and Defence. Australia is committed to OECD's values-based principles for the responsible stewardship of trustworthy AI as well as adopting a set of National AI ethics principles. While Australia has not adopted an AI governance framework specifically for Defence; Defence Science has published 'A Method for Ethical AI in Defence' (MEAID) technical report which includes a framework and pragmatic tools for managing ethical and legal risks for military applications of AI.
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.
Object detection typically assumes that training and test data are drawn from an identical distribution, which, however, does not always hold in practice. Such a distribution mismatch will lead to a significant performance drop. In this work, we aim to improve the cross-domain robustness of object detection. We tackle the domain shift on two levels: 1) the image-level shift, such as image style, illumination, etc, and 2) the instance-level shift, such as object appearance, size, etc. We build our approach based on the recent state-of-the-art Faster R-CNN model, and design two domain adaptation components, on image level and instance level, to reduce the domain discrepancy. The two domain adaptation components are based on H-divergence theory, and are implemented by learning a domain classifier in adversarial training manner. The domain classifiers on different levels are further reinforced with a consistency regularization to learn a domain-invariant region proposal network (RPN) in the Faster R-CNN model. We evaluate our newly proposed approach using multiple datasets including Cityscapes, KITTI, SIM10K, etc. The results demonstrate the effectiveness of our proposed approach for robust object detection in various domain shift scenarios.
小貼士
登錄享
相關主題




注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191