


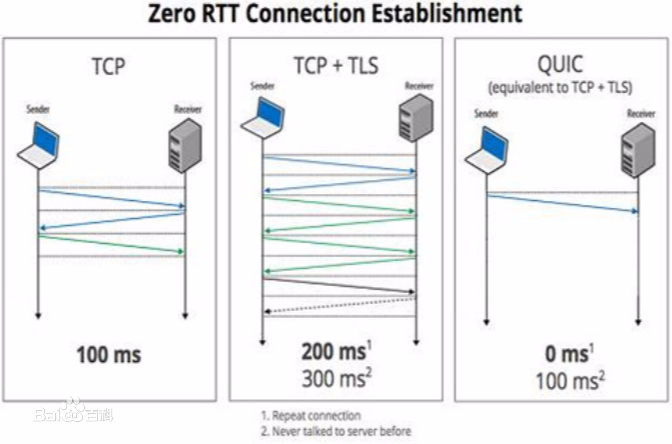
Encrypted QUIC traffic complicates network management as traditional transport layer semantics can no longer be used for RTT or packet loss measurements. Addressing this challenge, QUIC includes an optional, carefully designed mechanism: the spin bit. While its capabilities have already been studied in test settings, its real-world usefulness and adoption are unknown. In this paper, we thus investigate the spin bit's deployment and utility on the web. Analyzing our long-term measurements of more than 200M domains, we find that the spin bit is enabled on ~10% of those with QUIC support and for ~50% / 60% of the underlying IPv4 / IPv6 hosts. The support is mainly driven by medium-sized cloud providers while most hyperscalers do not implement it. Assessing the utility of spin bit RTT measurements, the theoretical issue of reordering does not significantly manifest in our study and the spin bit provides accurate estimates for around 30.5% of connections using the mechanism, but drastically overestimates the RTT for another 51.7%. Overall, we conclude that the spin bit, even though an optional feature, indeed sees use in the wild and is able to provide reasonable RTT estimates for a solid share of QUIC connections, but requires solutions for making its measurements more robust.
相關內容
第26屆SPIN研討會旨在將對軟件分析和軟件模型自動化工具技術感興趣的研究人員和實踐者聚集在一起,以進行驗證和確認。研討會特別關注并發軟件,但不排除對順序軟件的分析。提交的資料包括理論結果、新算法、工具開發和經驗評估。官網鏈接: ·
泛函
·
得分
·
Networking
·
Analysis
·
GossipSub is a new peer-to-peer communication protocol designed to counter attacks from misbehaving peers by controlling what information is sent and to whom, via a score function computed by each peer that captures positive and negative behaviors of its neighbors. The score function depends on several parameters (weights, caps, thresholds) that can be configured by applications using GossipSub. The specification for GossipSub is written in English and its resilience to attacks from misbehaving peers is supported empirically by emulation testing using an implementation in Golang. In this work we take a foundational approach to understanding the resilience of GossipSub to attacks from misbehaving peers. We build the first formal model of GossipSub, using the ACL2s theorem prover. Our model is officially endorsed by the GossipSub developers. It can simulate GossipSub networks of arbitrary size and topology, with arbitrarily configured peers, and can be used to prove and disprove theorems about the protocol. We formalize fundamental security properties stating that the score function is fair, penalizes bad behavior, and rewards good behavior. We prove that the score function is always fair, but can be configured in ways that either penalize good behavior or ignore bad behavior. Using our model, we run GossipSub with the specific configurations for two popular real-world applications: the FileCoin and Eth2.0 blockchains. We show that all properties hold for FileCoin. However, given any Eth2.0 network (of any topology and size) with any number of potentially misbehaving peers, we can synthesize attacks where these peers are able to continuously misbehave by never forwarding topic messages, while maintaining positive scores so that they are never pruned from the network by GossipSub.
Incorporating prior knowledge into a data-driven modeling problem can drastically improve performance, reliability, and generalization outside of the training sample. The stronger the structural properties, the more effective these improvements become. Manifolds are a powerful nonlinear generalization of Euclidean space for modeling finite dimensions. Structural impositions in constrained systems increase when applying group structure, converting them into Lie manifolds. The range of their applications is very wide and includes the important case of robotic tasks. Canonical Correlation Analysis (CCA) can construct a hierarchical sequence of maximal correlations of up to two paired data sets in these Euclidean spaces. We present a method to generalize this concept to Lie Manifolds and demonstrate its efficacy through the substantial improvements it achieves in making structure-consistent predictions about changes in the state of a robotic hand.
Neural networks have demonstrated significant accuracy across various domains, yet their vulnerability to subtle input alterations remains a persistent challenge. Conventional methods like data augmentation, while effective to some extent, fall short in addressing unforeseen corruptions, limiting the adaptability of neural networks in real-world scenarios. In response, this paper introduces a novel paradigm known as the Mixture of Class-Specific Expert Architecture. The approach involves disentangling feature learning for individual classes, offering a nuanced enhancement in scalability and overall performance. By training dedicated network segments for each class and subsequently aggregating their outputs, the proposed architecture aims to mitigate vulnerabilities associated with common neural network structures. The study underscores the importance of comprehensive evaluation methodologies, advocating for the incorporation of benchmarks like the common corruptions benchmark. This inclusion provides nuanced insights into the vulnerabilities of neural networks, especially concerning their generalization capabilities and robustness to unforeseen distortions. The research aligns with the broader objective of advancing the development of highly robust learning systems capable of nuanced reasoning across diverse and challenging real-world scenarios. Through this contribution, the paper aims to foster a deeper understanding of neural network limitations and proposes a practical approach to enhance their resilience in the face of evolving and unpredictable conditions.
Recent studies have highlighted a phenomenon in large language models (LLMs) known as "the reversal curse," in which the order of knowledge entities in the training data biases the models' comprehension. For example, if a model is trained on sentences where entity A consistently appears before entity B, it can respond to queries about A by providing B as the answer. However, it may encounter confusion when presented with questions concerning B. We contend that the reversal curse is partially a result of specific model training objectives, particularly evident in the prevalent use of the next-token prediction within most causal language models. For the next-token prediction, models solely focus on a token's preceding context, resulting in a restricted comprehension of the input. In contrast, we illustrate that the GLM, trained using the autoregressive blank infilling objective where tokens to be predicted have access to the entire context, exhibits better resilience against the reversal curse. We propose a novel training method, BIdirectional Casual language modeling Optimization (BICO), designed to mitigate the reversal curse when fine-tuning pretrained causal language models on new data. BICO modifies the causal attention mechanism to function bidirectionally and employs a mask denoising optimization. In the task designed to assess the reversal curse, our approach improves Llama's accuracy from the original 0% to around 70%. We hope that more attention can be focused on exploring and addressing these inherent weaknesses of the current LLMs, in order to achieve a higher level of intelligence.
Graph neural networks (GNNs) have been demonstrated to be a powerful algorithmic model in broad application fields for their effectiveness in learning over graphs. To scale GNN training up for large-scale and ever-growing graphs, the most promising solution is distributed training which distributes the workload of training across multiple computing nodes. However, the workflows, computational patterns, communication patterns, and optimization techniques of distributed GNN training remain preliminarily understood. In this paper, we provide a comprehensive survey of distributed GNN training by investigating various optimization techniques used in distributed GNN training. First, distributed GNN training is classified into several categories according to their workflows. In addition, their computational patterns and communication patterns, as well as the optimization techniques proposed by recent work are introduced. Second, the software frameworks and hardware platforms of distributed GNN training are also introduced for a deeper understanding. Third, distributed GNN training is compared with distributed training of deep neural networks, emphasizing the uniqueness of distributed GNN training. Finally, interesting issues and opportunities in this field are discussed.
Graph neural networks (GNNs) have demonstrated a significant boost in prediction performance on graph data. At the same time, the predictions made by these models are often hard to interpret. In that regard, many efforts have been made to explain the prediction mechanisms of these models from perspectives such as GNNExplainer, XGNN and PGExplainer. Although such works present systematic frameworks to interpret GNNs, a holistic review for explainable GNNs is unavailable. In this survey, we present a comprehensive review of explainability techniques developed for GNNs. We focus on explainable graph neural networks and categorize them based on the use of explainable methods. We further provide the common performance metrics for GNNs explanations and point out several future research directions.
Deep neural networks have revolutionized many machine learning tasks in power systems, ranging from pattern recognition to signal processing. The data in these tasks is typically represented in Euclidean domains. Nevertheless, there is an increasing number of applications in power systems, where data are collected from non-Euclidean domains and represented as the graph-structured data with high dimensional features and interdependency among nodes. The complexity of graph-structured data has brought significant challenges to the existing deep neural networks defined in Euclidean domains. Recently, many studies on extending deep neural networks for graph-structured data in power systems have emerged. In this paper, a comprehensive overview of graph neural networks (GNNs) in power systems is proposed. Specifically, several classical paradigms of GNNs structures (e.g., graph convolutional networks, graph recurrent neural networks, graph attention networks, graph generative networks, spatial-temporal graph convolutional networks, and hybrid forms of GNNs) are summarized, and key applications in power systems such as fault diagnosis, power prediction, power flow calculation, and data generation are reviewed in detail. Furthermore, main issues and some research trends about the applications of GNNs in power systems are discussed.
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.
Deep neural networks (DNNs) are successful in many computer vision tasks. However, the most accurate DNNs require millions of parameters and operations, making them energy, computation and memory intensive. This impedes the deployment of large DNNs in low-power devices with limited compute resources. Recent research improves DNN models by reducing the memory requirement, energy consumption, and number of operations without significantly decreasing the accuracy. This paper surveys the progress of low-power deep learning and computer vision, specifically in regards to inference, and discusses the methods for compacting and accelerating DNN models. The techniques can be divided into four major categories: (1) parameter quantization and pruning, (2) compressed convolutional filters and matrix factorization, (3) network architecture search, and (4) knowledge distillation. We analyze the accuracy, advantages, disadvantages, and potential solutions to the problems with the techniques in each category. We also discuss new evaluation metrics as a guideline for future research.
Many natural language processing tasks solely rely on sparse dependencies between a few tokens in a sentence. Soft attention mechanisms show promising performance in modeling local/global dependencies by soft probabilities between every two tokens, but they are not effective and efficient when applied to long sentences. By contrast, hard attention mechanisms directly select a subset of tokens but are difficult and inefficient to train due to their combinatorial nature. In this paper, we integrate both soft and hard attention into one context fusion model, "reinforced self-attention (ReSA)", for the mutual benefit of each other. In ReSA, a hard attention trims a sequence for a soft self-attention to process, while the soft attention feeds reward signals back to facilitate the training of the hard one. For this purpose, we develop a novel hard attention called "reinforced sequence sampling (RSS)", selecting tokens in parallel and trained via policy gradient. Using two RSS modules, ReSA efficiently extracts the sparse dependencies between each pair of selected tokens. We finally propose an RNN/CNN-free sentence-encoding model, "reinforced self-attention network (ReSAN)", solely based on ReSA. It achieves state-of-the-art performance on both Stanford Natural Language Inference (SNLI) and Sentences Involving Compositional Knowledge (SICK) datasets.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191