
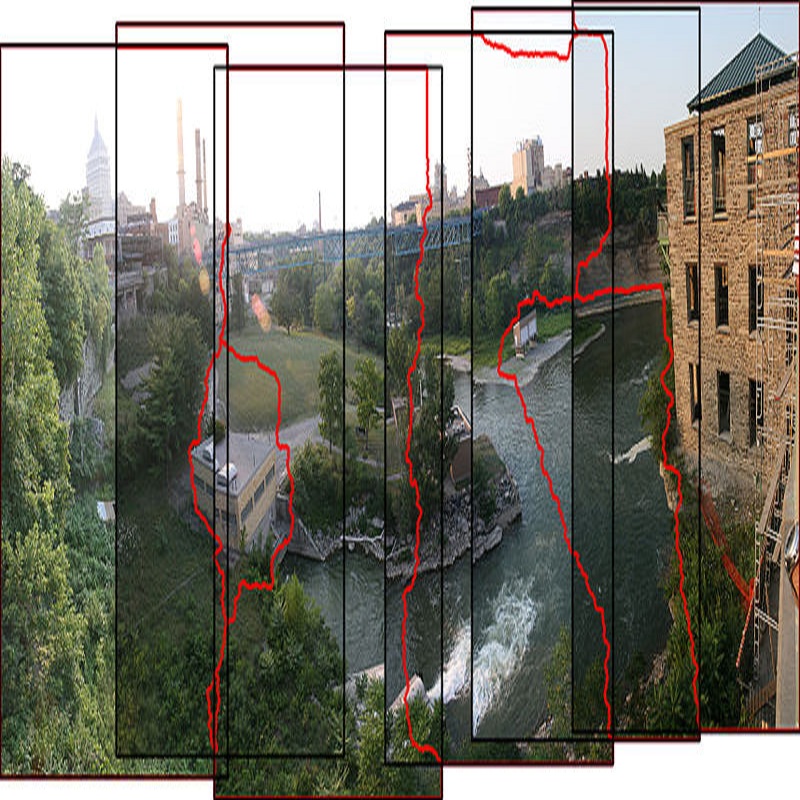

Image stitching is to construct panoramic images with wider field of vision (FOV) from some images captured from different viewing positions. To solve the problem of fusion ghosting in the stitched image, seam-driven methods avoid the misalignment area to fuse images by predicting the best seam. Currently, as standard tools of the OpenCV library, dynamic programming (DP) and GraphCut (GC) are still the only commonly used seam prediction methods despite the fact that they were both proposed two decades ago. However, GC can get excellent seam quality but poor real-time performance while DP method has good efficiency but poor seam quality. In this paper, we propose a deep learning based seam prediction method (DSeam) for the sake of high seam quality with high efficiency. To overcome the difficulty of the seam description in network and no GroundTruth for training we design a selective consistency loss combining the seam shape constraint and seam quality constraint to supervise the network learning. By the constraint of the selection of consistency loss, we implicitly defined the mask boundaries as seams and transform seam prediction into mask prediction. To our knowledge, the proposed DSeam is the first deep learning based seam prediction method for image stitching. Extensive experimental results well demonstrate the superior performance of our proposed Dseam method which is 15 times faster than the classic GC seam prediction method in OpenCV 2.4.9 with similar seam quality.
相關內容
Online Social Network (OSN) has become a hotbed of fake news due to the low cost of information dissemination. Although the existing methods have made many attempts in news content and propagation structure, the detection of fake news is still facing two challenges: one is how to mine the unique key features and evolution patterns, and the other is how to tackle the problem of small samples to build the high-performance model. Different from popular methods which take full advantage of the propagation topology structure, in this paper, we propose a novel framework for fake news detection from perspectives of semantic, emotion and data enhancement, which excavates the emotional evolution patterns of news participants during the propagation process, and a dual deep interaction channel network of semantic and emotion is designed to obtain a more comprehensive and fine-grained news representation with the consideration of comments. Meanwhile, the framework introduces a data enhancement module to obtain more labeled data with high quality based on confidence which further improves the performance of the classification model. Experiments show that the proposed approach outperforms the state-of-the-art methods.
Imputation of missing images via source-to-target modality translation can improve diversity in medical imaging protocols. A pervasive approach for synthesizing target images involves one-shot mapping through generative adversarial networks (GAN). Yet, GAN models that implicitly characterize the image distribution can suffer from limited sample fidelity. Here, we propose a novel method based on adversarial diffusion modeling, SynDiff, for improved performance in medical image translation. To capture a direct correlate of the image distribution, SynDiff leverages a conditional diffusion process that progressively maps noise and source images onto the target image. For fast and accurate image sampling during inference, large diffusion steps are taken with adversarial projections in the reverse diffusion direction. To enable training on unpaired datasets, a cycle-consistent architecture is devised with coupled diffusive and non-diffusive modules that bilaterally translate between two modalities. Extensive assessments are reported on the utility of SynDiff against competing GAN and diffusion models in multi-contrast MRI and MRI-CT translation. Our demonstrations indicate that SynDiff offers quantitatively and qualitatively superior performance against competing baselines.
Hierarchical classification (HC) assigns each object with multiple labels organized into a hierarchical structure. The existing deep learning based HC methods usually predict an instance starting from the root node until a leaf node is reached. However, in the real world, images interfered by noise, occlusion, blur, or low resolution may not provide sufficient information for the classification at subordinate levels. To address this issue, we propose a novel semantic guided level-category hybrid prediction network (SGLCHPN) that can jointly perform the level and category prediction in an end-to-end manner. SGLCHPN comprises two modules: a visual transformer that extracts feature vectors from the input images, and a semantic guided cross-attention module that uses categories word embeddings as queries to guide learning category-specific representations. In order to evaluate the proposed method, we construct two new datasets in which images are at a broad range of quality and thus are labeled to different levels (depths) in the hierarchy according to their individual quality. Experimental results demonstrate the effectiveness of our proposed HC method.
This paper studies the change point detection problem in time series of networks, with the Separable Temporal Exponential-family Random Graph Model (STERGM). We consider a sequence of networks generated from a piecewise constant distribution that is altered at unknown change points in time. Detection of the change points can identify the discrepancies in the underlying data generating processes and facilitate downstream dynamic network analysis tasks. Moreover, the STERGM that focuses on network statistics is a flexible model to fit dynamic networks with both dyadic and temporal dependence. We propose a new estimator derived from the Alternating Direction Method of Multipliers (ADMM) and the Group Fused Lasso to simultaneously detect multiple time points, where the parameters of STERGM have changed. We also provide Bayesian information criterion for model selection to assist the detection. Our experiments show good performance of the proposed method on both simulated and real data. Lastly, we develop an R package CPDstergm to implement our method.
Self-supervised learning has been widely used to obtain transferrable representations from unlabeled images. Especially, recent contrastive learning methods have shown impressive performances on downstream image classification tasks. While these contrastive methods mainly focus on generating invariant global representations at the image-level under semantic-preserving transformations, they are prone to overlook spatial consistency of local representations and therefore have a limitation in pretraining for localization tasks such as object detection and instance segmentation. Moreover, aggressively cropped views used in existing contrastive methods can minimize representation distances between the semantically different regions of a single image. In this paper, we propose a spatially consistent representation learning algorithm (SCRL) for multi-object and location-specific tasks. In particular, we devise a novel self-supervised objective that tries to produce coherent spatial representations of a randomly cropped local region according to geometric translations and zooming operations. On various downstream localization tasks with benchmark datasets, the proposed SCRL shows significant performance improvements over the image-level supervised pretraining as well as the state-of-the-art self-supervised learning methods.
Deep learning-based semi-supervised learning (SSL) algorithms have led to promising results in medical images segmentation and can alleviate doctors' expensive annotations by leveraging unlabeled data. However, most of the existing SSL algorithms in literature tend to regularize the model training by perturbing networks and/or data. Observing that multi/dual-task learning attends to various levels of information which have inherent prediction perturbation, we ask the question in this work: can we explicitly build task-level regularization rather than implicitly constructing networks- and/or data-level perturbation-and-transformation for SSL? To answer this question, we propose a novel dual-task-consistency semi-supervised framework for the first time. Concretely, we use a dual-task deep network that jointly predicts a pixel-wise segmentation map and a geometry-aware level set representation of the target. The level set representation is converted to an approximated segmentation map through a differentiable task transform layer. Simultaneously, we introduce a dual-task consistency regularization between the level set-derived segmentation maps and directly predicted segmentation maps for both labeled and unlabeled data. Extensive experiments on two public datasets show that our method can largely improve the performance by incorporating the unlabeled data. Meanwhile, our framework outperforms the state-of-the-art semi-supervised medical image segmentation methods. Code is available at: //github.com/Luoxd1996/DTC
A key requirement for the success of supervised deep learning is a large labeled dataset - a condition that is difficult to meet in medical image analysis. Self-supervised learning (SSL) can help in this regard by providing a strategy to pre-train a neural network with unlabeled data, followed by fine-tuning for a downstream task with limited annotations. Contrastive learning, a particular variant of SSL, is a powerful technique for learning image-level representations. In this work, we propose strategies for extending the contrastive learning framework for segmentation of volumetric medical images in the semi-supervised setting with limited annotations, by leveraging domain-specific and problem-specific cues. Specifically, we propose (1) novel contrasting strategies that leverage structural similarity across volumetric medical images (domain-specific cue) and (2) a local version of the contrastive loss to learn distinctive representations of local regions that are useful for per-pixel segmentation (problem-specific cue). We carry out an extensive evaluation on three Magnetic Resonance Imaging (MRI) datasets. In the limited annotation setting, the proposed method yields substantial improvements compared to other self-supervision and semi-supervised learning techniques. When combined with a simple data augmentation technique, the proposed method reaches within 8% of benchmark performance using only two labeled MRI volumes for training, corresponding to only 4% (for ACDC) of the training data used to train the benchmark.
Hashing has been widely used in approximate nearest search for large-scale database retrieval for its computation and storage efficiency. Deep hashing, which devises convolutional neural network architecture to exploit and extract the semantic information or feature of images, has received increasing attention recently. In this survey, several deep supervised hashing methods for image retrieval are evaluated and I conclude three main different directions for deep supervised hashing methods. Several comments are made at the end. Moreover, to break through the bottleneck of the existing hashing methods, I propose a Shadow Recurrent Hashing(SRH) method as a try. Specifically, I devise a CNN architecture to extract the semantic features of images and design a loss function to encourage similar images projected close. To this end, I propose a concept: shadow of the CNN output. During optimization process, the CNN output and its shadow are guiding each other so as to achieve the optimal solution as much as possible. Several experiments on dataset CIFAR-10 show the satisfying performance of SRH.
Applying artificial intelligence techniques in medical imaging is one of the most promising areas in medicine. However, most of the recent success in this area highly relies on large amounts of carefully annotated data, whereas annotating medical images is a costly process. In this paper, we propose a novel method, called FocalMix, which, to the best of our knowledge, is the first to leverage recent advances in semi-supervised learning (SSL) for 3D medical image detection. We conducted extensive experiments on two widely used datasets for lung nodule detection, LUNA16 and NLST. Results show that our proposed SSL methods can achieve a substantial improvement of up to 17.3% over state-of-the-art supervised learning approaches with 400 unlabeled CT scans.
Image segmentation is considered to be one of the critical tasks in hyperspectral remote sensing image processing. Recently, convolutional neural network (CNN) has established itself as a powerful model in segmentation and classification by demonstrating excellent performances. The use of a graphical model such as a conditional random field (CRF) contributes further in capturing contextual information and thus improving the segmentation performance. In this paper, we propose a method to segment hyperspectral images by considering both spectral and spatial information via a combined framework consisting of CNN and CRF. We use multiple spectral cubes to learn deep features using CNN, and then formulate deep CRF with CNN-based unary and pairwise potential functions to effectively extract the semantic correlations between patches consisting of three-dimensional data cubes. Effective piecewise training is applied in order to avoid the computationally expensive iterative CRF inference. Furthermore, we introduce a deep deconvolution network that improves the segmentation masks. We also introduce a new dataset and experimented our proposed method on it along with several widely adopted benchmark datasets to evaluate the effectiveness of our method. By comparing our results with those from several state-of-the-art models, we show the promising potential of our method.

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191