
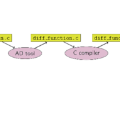

RooFit is a toolkit for statistical modeling and fitting used by most experiments in particle physics. Just as data sets from next-generation experiments grow, processing requirements for physics analysis become more computationally demanding, necessitating performance optimizations for RooFit. One possibility to speed-up minimization and add stability is the use of Automatic Differentiation (AD). Unlike for numerical differentiation, the computation cost scales linearly with the number of parameters, making AD particularly appealing for statistical models with many parameters. In this paper, we report on one possible way to implement AD in RooFit. Our approach is to add a facility to generate C++ code for a full RooFit model automatically. Unlike the original RooFit model, this generated code is free of virtual function calls and other RooFit-specific overhead. In particular, this code is then used to produce the gradient automatically with Clad. Clad is a source transformation AD tool implemented as a plugin to the clang compiler, which automatically generates the derivative code for input C++ functions. We show results demonstrating the improvements observed when applying this code generation strategy to HistFactory and other commonly used RooFit models. HistFactory is the subcomponent of RooFit that implements binned likelihood models with probability densities based on histogram templates. These models frequently have a very large number of free parameters and are thus an interesting first target for AD support in RooFit.
相關內容
在(zai)(zai)數(shu)學(xue)和計(ji)(ji)算(suan)(suan)(suan)機(ji)(ji)代數(shu)中,自動微分(fen)(fen)(fen)有(you)(you)時(shi)稱作演算(suan)(suan)(suan)式(shi)微分(fen)(fen)(fen),是(shi)(shi)一種(zhong)可以借由計(ji)(ji)算(suan)(suan)(suan)機(ji)(ji)程(cheng)序計(ji)(ji)算(suan)(suan)(suan)一個函數(shu)導數(shu)的(de)(de)方(fang)法(fa)(fa)。兩(liang)(liang)種(zhong)傳(chuan)統(tong)做(zuo)微分(fen)(fen)(fen)的(de)(de)方(fang)法(fa)(fa)為:(1)對一個函數(shu)的(de)(de)表示式(shi)做(zuo)符號上的(de)(de)微分(fen)(fen)(fen),并且計(ji)(ji)算(suan)(suan)(suan)其在(zai)(zai)某一點(dian)上的(de)(de)值。(2)使用差(cha)分(fen)(fen)(fen)。使用符號微分(fen)(fen)(fen)最主要的(de)(de)缺點(dian)是(shi)(shi)速度慢及(ji)將計(ji)(ji)算(suan)(suan)(suan)機(ji)(ji)程(cheng)序轉換成表示式(shi)的(de)(de)困難(nan)。此(ci)外,很多函數(shu)在(zai)(zai)要計(ji)(ji)算(suan)(suan)(suan)更高階微分(fen)(fen)(fen)時(shi)會變得復雜(za)。 使用差(cha)分(fen)(fen)(fen)的(de)(de)兩(liang)(liang)個重要的(de)(de)缺點(dian)是(shi)(shi)舍棄誤差(cha)及(ji)數(shu)值化過程(cheng)和相消誤差(cha)。此(ci)兩(liang)(liang)者傳(chuan)統(tong)方(fang)法(fa)(fa)在(zai)(zai)計(ji)(ji)算(suan)(suan)(suan)更高階微分(fen)(fen)(fen)時(shi),都有(you)(you)復雜(za)度及(ji)誤差(cha)增(zeng)加的(de)(de)問題。自動微分(fen)(fen)(fen)則解決上述的(de)(de)問題。
Recent studies have found that summaries generated by large language models (LLMs) are favored by human annotators over the original reference summaries in commonly used summarization datasets. Therefore, we investigate a new learning paradigm of text summarization models that considers the LLMs as the reference or the gold-standard oracle on commonly used summarization datasets such as the CNN/DailyMail dataset. To examine the standard practices that are aligned with the new learning setting, we propose a novel training method that is based on contrastive learning with LLMs as a summarization quality evaluator. For this reward-based training method, we investigate two different methods of utilizing LLMs for summary quality evaluation, namely GPTScore and GPTRank. Our experiments on the CNN/DailyMail dataset demonstrate that smaller summarization models trained by our proposed method can achieve performance equal to or surpass that of the reference LLMs, as evaluated by the LLMs themselves. This underscores the efficacy of our proposed paradigm in enhancing model performance over the standard maximum likelihood estimation (MLE) training method, and its efficiency since it only requires a small budget to access the LLMs. We release the training scripts, model outputs, and LLM-based evaluation results to facilitate future studies.
Video Moment Retrieval (VMR) aims at retrieving the most relevant events from an untrimmed video with natural language queries. Existing VMR methods suffer from two defects: (1) massive expensive temporal annotations are required to obtain satisfying performance; (2) complicated cross-modal interaction modules are deployed, which lead to high computational cost and low efficiency for the retrieval process. To address these issues, we propose a novel method termed Cheaper and Faster Moment Retrieval (CFMR), which well balances the retrieval accuracy, efficiency, and annotation cost for VMR. Specifically, our proposed CFMR method learns from point-level supervision where each annotation is a single frame randomly located within the target moment. It is 6 times cheaper than the conventional annotations of event boundaries. Furthermore, we also design a concept-based multimodal alignment mechanism to bypass the usage of cross-modal interaction modules during the inference process, remarkably improving retrieval efficiency. The experimental results on three widely used VMR benchmarks demonstrate the proposed CFMR method establishes new state-of-the-art with point-level supervision. Moreover, it significantly accelerates the retrieval speed with more than 100 times FLOPs compared to existing approaches with point-level supervision.
Studies investigating neural information processing often implicitly ask both, which processing strategy out of several alternatives is used and how this strategy is implemented in neural dynamics. A prime example are studies on predictive coding. These often ask if confirmed predictions about inputs or predictions errors between internal predictions and inputs are passed on in a hierarchical neural system--while at the same time looking for the neural correlates of coding for errors and predictions. If we do not know exactly what a neural system predicts at any given moment, this results in a circular analysis--as has been criticized correctly. To circumvent such circular analysis, we propose to express information processing strategies (such as predictive coding) by local information-theoretic quantities, such that they can be estimated directly from neural data. We demonstrate our approach by investigating two opposing accounts of predictive coding-like processing strategies, where we quantify the building blocks of predictive coding, namely predictability of inputs and transfer of information, by local active information storage and local transfer entropy. We define testable hypotheses on the relationship of both quantities to identify which of the assumed strategies was used. We demonstrate our approach on spiking data from the retinogeniculate synapse of the cat. Applying our local information dynamics framework, we are able to show that the synapse codes for predictable rather than surprising input. To support our findings, we apply measures from partial information decomposition, which allow to differentiate if the transferred information is primarily bottom-up sensory input or information transferred conditionally on the current state of the synapse. Supporting our local information-theoretic results, we find that the synapse preferentially transfers bottom-up information.
Gaussian boson sampling, a computational model that is widely believed to admit quantum supremacy, has already been experimentally demonstrated and is claimed to surpass the classical simulation capabilities of even the most powerful supercomputers today. However, whether the current approach limited by photon loss and noise in such experiments prescribes a scalable path to quantum advantage is an open question. To understand the effect of photon loss on the scalability of Gaussian boson sampling, we analytically derive the asymptotic operator entanglement entropy scaling, which relates to the simulation complexity. As a result, we observe that efficient tensor network simulations are likely possible under the $N_\text{out}\propto\sqrt{N}$ scaling of the number of surviving photons in the number of input photons. We numerically verify this result using a tensor network algorithm with $U(1)$ symmetry, and overcome previous challenges due to the large local Hilbert space dimensions in Gaussian boson sampling with hardware acceleration. Additionally, we observe that increasing the photon number through larger squeezing does not increase the entanglement entropy significantly. Finally, we numerically find the bond dimension necessary for fixed accuracy simulations, providing more direct evidence for the complexity of tensor networks.
Wearable devices permit the continuous monitoring of biological processes, such as blood glucose metabolism, and behavior, such as sleep quality and physical activity. The continuous monitoring often occurs in epochs of 60 seconds over multiple days, resulting in high dimensional longitudinal curves that are best described and analyzed as functional data. From this perspective, the functional data are smooth, latent functions obtained at discrete time intervals and prone to homoscedastic white noise. However, the assumption of homoscedastic errors might not be appropriate in this setting because the devices collect the data serially. While researchers have previously addressed measurement error in scalar covariates prone to errors, less work has been done on correcting measurement error in high dimensional longitudinal curves prone to heteroscedastic errors. We present two new methods for correcting measurement error in longitudinal functional curves prone to complex measurement error structures in multi-level generalized functional linear regression models. These methods are based on two-stage scalable regression calibration. We assume that the distribution of the scalar responses and the surrogate measures prone to heteroscedastic errors both belong in the exponential family and that the measurement errors follow Gaussian processes. In simulations and sensitivity analyses, we established some finite sample properties of these methods. In our simulations, both regression calibration methods for correcting measurement error performed better than estimators based on averaging the longitudinal functional data and using observations from a single day. We also applied the methods to assess the relationship between physical activity and type 2 diabetes in community dwelling adults in the United States who participated in the National Health and Nutrition Examination Survey.
Likelihood profiling is an efficient and powerful frequentist approach for parameter estimation, uncertainty quantification and practical identifiablity analysis. Unfortunately, these methods cannot be easily applied for stochastic models without a tractable likelihood function. Such models are typical in many fields of science, rendering these classical approaches impractical in these settings. To address this limitation, we develop a new approach to generalising the methods of likelihood profiling for situations when the likelihood cannot be evaluated but stochastic simulations of the assumed data generating process are possible. Our approach is based upon recasting developments from generalised Bayesian inference into a frequentist setting. We derive a method for constructing generalised likelihood profiles and calibrating these profiles to achieve desired frequentist coverage for a given coverage level. We demonstrate the performance of our method on realistic examples from the literature and highlight the capability of our approach for the purpose of practical identifability analysis for models with intractable likelihoods.
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
Classic algorithms and machine learning systems like neural networks are both abundant in everyday life. While classic computer science algorithms are suitable for precise execution of exactly defined tasks such as finding the shortest path in a large graph, neural networks allow learning from data to predict the most likely answer in more complex tasks such as image classification, which cannot be reduced to an exact algorithm. To get the best of both worlds, this thesis explores combining both concepts leading to more robust, better performing, more interpretable, more computationally efficient, and more data efficient architectures. The thesis formalizes the idea of algorithmic supervision, which allows a neural network to learn from or in conjunction with an algorithm. When integrating an algorithm into a neural architecture, it is important that the algorithm is differentiable such that the architecture can be trained end-to-end and gradients can be propagated back through the algorithm in a meaningful way. To make algorithms differentiable, this thesis proposes a general method for continuously relaxing algorithms by perturbing variables and approximating the expectation value in closed form, i.e., without sampling. In addition, this thesis proposes differentiable algorithms, such as differentiable sorting networks, differentiable renderers, and differentiable logic gate networks. Finally, this thesis presents alternative training strategies for learning with algorithms.
The conjoining of dynamical systems and deep learning has become a topic of great interest. In particular, neural differential equations (NDEs) demonstrate that neural networks and differential equation are two sides of the same coin. Traditional parameterised differential equations are a special case. Many popular neural network architectures, such as residual networks and recurrent networks, are discretisations. NDEs are suitable for tackling generative problems, dynamical systems, and time series (particularly in physics, finance, ...) and are thus of interest to both modern machine learning and traditional mathematical modelling. NDEs offer high-capacity function approximation, strong priors on model space, the ability to handle irregular data, memory efficiency, and a wealth of available theory on both sides. This doctoral thesis provides an in-depth survey of the field. Topics include: neural ordinary differential equations (e.g. for hybrid neural/mechanistic modelling of physical systems); neural controlled differential equations (e.g. for learning functions of irregular time series); and neural stochastic differential equations (e.g. to produce generative models capable of representing complex stochastic dynamics, or sampling from complex high-dimensional distributions). Further topics include: numerical methods for NDEs (e.g. reversible differential equations solvers, backpropagation through differential equations, Brownian reconstruction); symbolic regression for dynamical systems (e.g. via regularised evolution); and deep implicit models (e.g. deep equilibrium models, differentiable optimisation). We anticipate this thesis will be of interest to anyone interested in the marriage of deep learning with dynamical systems, and hope it will provide a useful reference for the current state of the art.
Dynamic programming (DP) solves a variety of structured combinatorial problems by iteratively breaking them down into smaller subproblems. In spite of their versatility, DP algorithms are usually non-differentiable, which hampers their use as a layer in neural networks trained by backpropagation. To address this issue, we propose to smooth the max operator in the dynamic programming recursion, using a strongly convex regularizer. This allows to relax both the optimal value and solution of the original combinatorial problem, and turns a broad class of DP algorithms into differentiable operators. Theoretically, we provide a new probabilistic perspective on backpropagating through these DP operators, and relate them to inference in graphical models. We derive two particular instantiations of our framework, a smoothed Viterbi algorithm for sequence prediction and a smoothed DTW algorithm for time-series alignment. We showcase these instantiations on two structured prediction tasks and on structured and sparse attention for neural machine translation.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191