
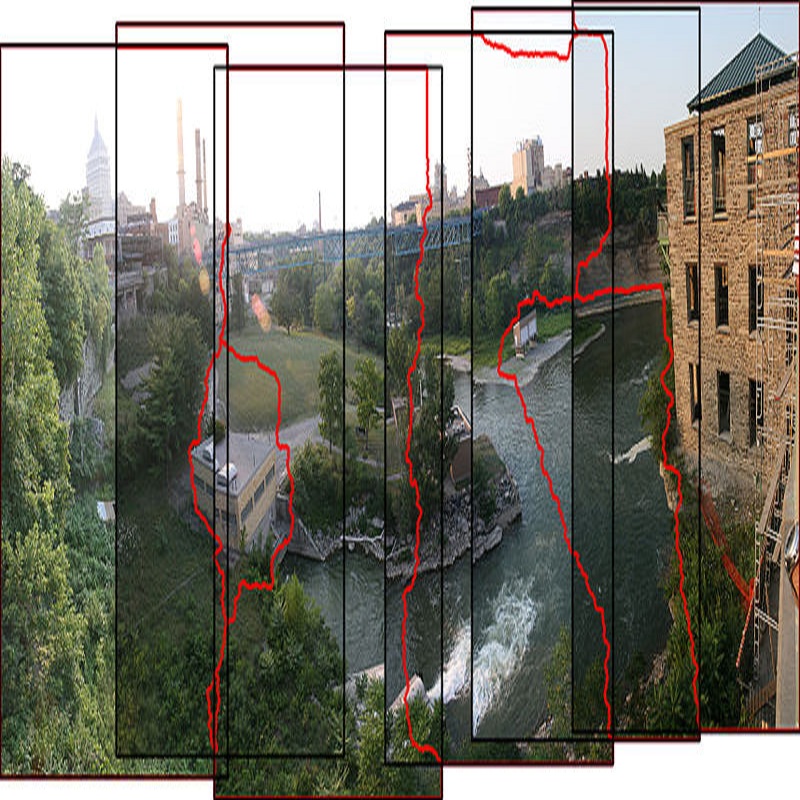

Challenging to capture, and challenging to display on a cellphone screen, the panorama paradoxically remains both a staple and underused feature of modern mobile camera applications. In this work we address both of these challenges with a spherical neural light field model for implicit panoramic image stitching and re-rendering; able to accommodate for depth parallax, view-dependent lighting, and local scene motion and color changes during capture. Fit during test-time to an arbitrary path panoramic video capture -- vertical, horizontal, random-walk -- these neural light spheres jointly estimate the camera path and a high-resolution scene reconstruction to produce novel wide field-of-view projections of the environment. Our single-layer model avoids expensive volumetric sampling, and decomposes the scene into compact view-dependent ray offset and color components, with a total model size of 80 MB per scene, and real-time (50 FPS) rendering at 1080p resolution. We demonstrate improved reconstruction quality over traditional image stitching and radiance field methods, with significantly higher tolerance to scene motion and non-ideal capture settings.
相關內容
The healthcare sector has experienced a rapid accumulation of digital data recently, especially in the form of electronic health records (EHRs). EHRs constitute a precious resource that IS researchers could utilize for clinical applications (e.g., morbidity prediction). Deep learning seems like the obvious choice to exploit this surfeit of data. However, numerous studies have shown that deep learning does not enjoy the same kind of success on EHR data as it has in other domains; simple models like logistic regression are frequently as good as sophisticated deep learning ones. Inspired by this observation, we develop a novel model called rational logistic regression (RLR) that has standard logistic regression (LR) as its special case (and thus inherits LR's inductive bias that aligns with EHR data). RLR has rational series as its theoretical underpinnings, works on longitudinal time-series data, and learns interpretable patterns. Empirical comparisons on real-world clinical tasks demonstrate RLR's efficacy.
Diffeomorphic image registration is crucial for various medical imaging applications because it can preserve the topology of the transformation. This study introduces DCCNN-LSTM-Reg, a learning framework that evolves dynamically and learns a symmetrical registration path by satisfying a specified control increment system. This framework aims to obtain symmetric diffeomorphic deformations between moving and fixed images. To achieve this, we combine deep learning networks with diffeomorphic mathematical mechanisms to create a continuous and dynamic registration architecture, which consists of multiple Symmetric Registration (SR) modules cascaded on five different scales. Specifically, our method first uses two U-nets with shared parameters to extract multiscale feature pyramids from the images. We then develop an SR-module comprising a sequential CNN-LSTM architecture to progressively correct the forward and reverse multiscale deformation fields using control increment learning and the homotopy continuation technique. Through extensive experiments on three 3D registration tasks, we demonstrate that our method outperforms existing approaches in both quantitative and qualitative evaluations.
Photoacoustic imaging (PAI) represents an innovative biomedical imaging modality that harnesses the advantages of optical resolution and acoustic penetration depth while ensuring enhanced safety. Despite its promising potential across a diverse array of preclinical and clinical applications, the clinical implementation of PAI faces significant challenges, including the trade-off between penetration depth and spatial resolution, as well as the demand for faster imaging speeds. This paper explores the fundamental principles underlying PAI, with a particular emphasis on three primary implementations: photoacoustic computed tomography (PACT), photoacoustic microscopy (PAM), and photoacoustic endoscopy (PAE). We undertake a critical assessment of their respective strengths and practical limitations. Furthermore, recent developments in utilizing conventional or deep learning (DL) methodologies for image reconstruction and artefact mitigation across PACT, PAM, and PAE are outlined, demonstrating considerable potential to enhance image quality and accelerate imaging processes. Furthermore, this paper examines the recent developments in quantitative analysis within PAI, including the quantification of haemoglobin concentration, oxygen saturation, and other physiological parameters within tissues. Finally, our discussion encompasses current trends and future directions in PAI research while emphasizing the transformative impact of deep learning on advancing PAI.
Passive non-line-of-sight (NLOS) imaging has witnessed rapid development in recent years, due to its ability to image objects that are out of sight. The light transport condition plays an important role in this task since changing the conditions will lead to different imaging models. Existing learning-based NLOS methods usually train independent models for different light transport conditions, which is computationally inefficient and impairs the practicality of the models. In this work, we propose NLOS-LTM, a novel passive NLOS imaging method that effectively handles multiple light transport conditions with a single network. We achieve this by inferring a latent light transport representation from the projection image and using this representation to modulate the network that reconstructs the hidden image from the projection image. We train a light transport encoder together with a vector quantizer to obtain the light transport representation. To further regulate this representation, we jointly learn both the reconstruction network and the reprojection network during training. A set of light transport modulation blocks is used to modulate the two jointly trained networks in a multi-scale way. Extensive experiments on a large-scale passive NLOS dataset demonstrate the superiority of the proposed method. The code is available at //github.com/JerryOctopus/NLOS-LTM.
Common challenges in fault diagnosis include the lack of labeled data and the need to build models for each domain, resulting in many models that require supervision. Transfer learning can help tackle these challenges by learning cross-domain knowledge. Many approaches still require at least some labeled data in the target domain, and often provide unexplainable results. To this end, we propose a supervised transfer learning framework for fault diagnosis in wind turbines that operates in an Anomaly-Space. This space was created using SCADA data and vibration data and was built and provided to us by our research partner. Data within the Anomaly-Space can be interpreted as anomaly scores for each component in the wind turbine, making each value intuitive to understand. We conducted cross-domain evaluation on the train set using popular supervised classifiers like Random Forest, Light-Gradient-Boosting-Machines and Multilayer Perceptron as metamodels for the diagnosis of bearing and sensor faults. The Multilayer Perceptron achieved the highest classification performance. This model was then used for a final evaluation in our test set. The results show, that the proposed framework is able to detect cross-domain faults in the test set with a high degree of accuracy by using one single classifier, which is a significant asset to the diagnostic team.
Data assimilation performance can be significantly impacted by biased noise in observations, altering the signal magnitude and introducing fast oscillations or discontinuities when the system lacks smoothness. To mitigate these issues, this paper employ variational state estimation using the so-called parametrized-background data-weak method. This approach relies on a background manifold parametrized by a set of constraints, enabling the state estimation by solving a minimization problem on a reduced-order background model, subject to constraints imposed by the input measurements. The proposed formulation incorporates a novel bias correction mechanism and a manifold decomposition that handles rapid oscillations by treating them as slow-decaying modes based on a two-scale splitting of the classical reconstruction algorithm. The method is validated in different examples, including the assimilation of biased synthetic data, discontinuous signals, and Doppler ultrasound data obtained from experimental measurements.
Community detection plays a pivotal role in uncovering closely connected subgraphs, aiding various real-world applications such as recommendation systems and anomaly detection. With the surge of rich information available for entities in real-world networks, the community detection problem in attributed networks has attracted widespread attention. While previous research has effectively leveraged network topology and attribute information for attributed community detection, these methods overlook two critical issues: (i) the semantic similarity between node attributes within the community, and (ii) the inherent mesoscopic structure, which differs from the pairwise connections of the micro-structure. To address these limitations, we propose HACD, a novel attributed community detection model based on heterogeneous graph attention networks. HACD treats node attributes as another type of node, constructs attributed networks into heterogeneous graph structures and employs attribute-level attention mechanisms to capture semantic similarity. Furthermore, HACD introduces a community membership function to explore mesoscopic community structures, enhancing the robustness of detected communities. Extensive experiments demonstrate the effectiveness and efficiency of HACD, outperforming state-of-the-art methods in attributed community detection tasks. Our code is publicly available at //github.com/Anniran1/HACD1-wsdm.
Integration of diverse visual prompts like clicks, scribbles, and boxes in interactive image segmentation significantly facilitates users' interaction as well as improves interaction efficiency. However, existing studies primarily encode the position or pixel regions of prompts without considering the contextual areas around them, resulting in insufficient prompt feedback, which is not conducive to performance acceleration. To tackle this problem, this paper proposes a simple yet effective Probabilistic Visual Prompt Unified Transformer (PVPUFormer) for interactive image segmentation, which allows users to flexibly input diverse visual prompts with the probabilistic prompt encoding and feature post-processing to excavate sufficient and robust prompt features for performance boosting. Specifically, we first propose a Probabilistic Prompt-unified Encoder (PPuE) to generate a unified one-dimensional vector by exploring both prompt and non-prompt contextual information, offering richer feedback cues to accelerate performance improvement. On this basis, we further present a Prompt-to-Pixel Contrastive (P$^2$C) loss to accurately align both prompt and pixel features, bridging the representation gap between them to offer consistent feature representations for mask prediction. Moreover, our approach designs a Dual-cross Merging Attention (DMA) module to implement bidirectional feature interaction between image and prompt features, generating notable features for performance improvement. A comprehensive variety of experiments on several challenging datasets demonstrates that the proposed components achieve consistent improvements, yielding state-of-the-art interactive segmentation performance. Our code is available at //github.com/XuZhang1211/PVPUFormer.
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Ensembles over neural network weights trained from different random initialization, known as deep ensembles, achieve state-of-the-art accuracy and calibration. The recently introduced batch ensembles provide a drop-in replacement that is more parameter efficient. In this paper, we design ensembles not only over weights, but over hyperparameters to improve the state of the art in both settings. For best performance independent of budget, we propose hyper-deep ensembles, a simple procedure that involves a random search over different hyperparameters, themselves stratified across multiple random initializations. Its strong performance highlights the benefit of combining models with both weight and hyperparameter diversity. We further propose a parameter efficient version, hyper-batch ensembles, which builds on the layer structure of batch ensembles and self-tuning networks. The computational and memory costs of our method are notably lower than typical ensembles. On image classification tasks, with MLP, LeNet, and Wide ResNet 28-10 architectures, our methodology improves upon both deep and batch ensembles.



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191