


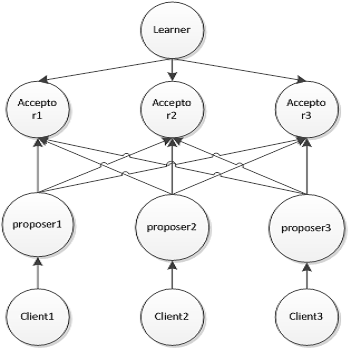
We describe a method to achieve distributed consensus in a Content Centric Network using the PAXOS algorithm. Consensus is necessary, for example, if multiple writers wish to agree on the current version number of a CCNx name or if multiple distributed systems wish to elect a leader for fast transaction processing. We describe two forms of protocols, one using standard CCNx Interest request and Content Object response, and the second using a CCNx Push request and response. We further divide the protocols in to those using the CCNx 0.x protocol where Content Object name may continue Interest names and the CCNx 1.0 protocol where Content Object names exactly match Interest names.
相關內容
Networking:IFIP International Conferences on Networking。
Explanation:國際網絡(luo)會議。
Publisher:IFIP。
SIT:
We present the first experiments on Native Language Identification (NLI) using LLMs such as GPT-4. NLI is the task of predicting a writer's first language by analyzing their writings in a second language, and is used in second language acquisition and forensic linguistics. Our results show that GPT models are proficient at NLI classification, with GPT-4 setting a new performance record of 91.7% on the benchmark TOEFL11 test set in a zero-shot setting. We also show that unlike previous fully-supervised settings, LLMs can perform NLI without being limited to a set of known classes, which has practical implications for real-world applications. Finally, we also show that LLMs can provide justification for their choices, providing reasoning based on spelling errors, syntactic patterns, and usage of directly translated linguistic patterns.
We have utilized the non-conjugate VB method for the problem of the sparse Poisson regression model. To provide an approximated conjugacy in the model, the likelihood is approximated by a quadratic function, which provides the conjugacy of the approximation component with the Gaussian prior to the regression coefficient. Three sparsity-enforcing priors are used for this problem. The proposed models are compared with each other and two frequentist sparse Poisson methods (LASSO and SCAD) to evaluate the prediction performance, as well as, the sparsing performance of the proposed methods. Throughout a simulated data example, the accuracy of the VB methods is computed compared to the corresponding benchmark MCMC methods. It can be observed that the proposed VB methods have provided a good approximation to the posterior distribution of the parameters, while the VB methods are much faster than the MCMC ones. Using several benchmark count response data sets, the prediction performance of the proposed methods is evaluated in real-world applications.
Adaptive importance sampling (AIS) methods provide a useful alternative to Markov Chain Monte Carlo (MCMC) algorithms for performing inference of intractable distributions. Population Monte Carlo (PMC) algorithms constitute a family of AIS approaches which adapt the proposal distributions iteratively to improve the approximation of the target distribution. Recent work in this area primarily focuses on ameliorating the proposal adaptation procedure for high-dimensional applications. However, most of the AIS algorithms use simple proposal distributions for sampling, which might be inadequate in exploring target distributions with intricate geometries. In this work, we construct expressive proposal distributions in the AIS framework using normalizing flow, an appealing approach for modeling complex distributions. We use an iterative parameter update rule to enhance the approximation of the target distribution. Numerical experiments show that in high-dimensional settings, the proposed algorithm offers significantly improved performance compared to the existing techniques.
Emotion detection is a crucial component of Games User Research (GUR), as it allows game developers to gain insights into players' emotional experiences and tailor their games accordingly. However, detecting emotions in Virtual Reality (VR) games is challenging due to the Head-Mounted Display (HMD) that covers the top part of the player's face, namely, their eyes and eyebrows, which provide crucial information for recognizing the impression. To tackle this we used a Convolutional Neural Network (CNN) to train a model to predict emotions in full-face images where the eyes and eyebrows are covered. We used the FER2013 dataset, which we modified to cover eyes and eyebrows in images. The model in these images can accurately recognize seven different emotions which are anger, happiness, disgust, fear, impartiality, sadness and surprise. We assessed the model's performance by testing it on two VR games and using it to detect players' emotions. We collected self-reported emotion data from the players after the gameplay sessions. We analyzed the data collected from our experiment to understand which emotions players experience during the gameplay. We found that our approach has the potential to enhance gameplay analysis by enabling the detection of players' emotions in VR games, which can help game developers create more engaging and immersive game experiences.
This is a sequel to the author's "Truth and Knowledge", College Publications, 2022, and contains some problems and results in connection with a possible representation for Yablo like structures.
Animals often demonstrate a remarkable ability to adapt to their environments during their lifetime. They do so partly due to the evolution of morphological and neural structures. These structures capture features of environments shared between generations to bias and speed up lifetime learning. In this work, we propose a computational model for studying a mechanism that can enable such a process. We adopt a computational framework based on meta reinforcement learning as a model of the interplay between evolution and development. At the evolutionary scale, we evolve reservoirs, a family of recurrent neural networks that differ from conventional networks in that one optimizes not the weight values but hyperparameters of the architecture: the later control macro-level properties, such as memory and dynamics. At the developmental scale, we employ these evolved reservoirs to facilitate the learning of a behavioral policy through Reinforcement Learning (RL). Within an RL agent, a reservoir encodes the environment state before providing it to an action policy. We evaluate our approach on several 2D and 3D simulated environments. Our results show that the evolution of reservoirs can improve the learning of diverse challenging tasks. We study in particular three hypotheses: the use of an architecture combining reservoirs and reinforcement learning could enable (1) solving tasks with partial observability, (2) generating oscillatory dynamics that facilitate the learning of locomotion tasks, and (3) facilitating the generalization of learned behaviors to new tasks unknown during the evolution phase.
2D-based Industrial Anomaly Detection has been widely discussed, however, multimodal industrial anomaly detection based on 3D point clouds and RGB images still has many untouched fields. Existing multimodal industrial anomaly detection methods directly concatenate the multimodal features, which leads to a strong disturbance between features and harms the detection performance. In this paper, we propose Multi-3D-Memory (M3DM), a novel multimodal anomaly detection method with hybrid fusion scheme: firstly, we design an unsupervised feature fusion with patch-wise contrastive learning to encourage the interaction of different modal features; secondly, we use a decision layer fusion with multiple memory banks to avoid loss of information and additional novelty classifiers to make the final decision. We further propose a point feature alignment operation to better align the point cloud and RGB features. Extensive experiments show that our multimodal industrial anomaly detection model outperforms the state-of-the-art (SOTA) methods on both detection and segmentation precision on MVTec-3D AD dataset. Code is available at //github.com/nomewang/M3DM.
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. In this paper, we conduct a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. We focus on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. We further summarize resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions. This survey can serve both academic researchers and industry practitioners working on TTS.
Recently, a considerable literature has grown up around the theme of Graph Convolutional Network (GCN). How to effectively leverage the rich structural information in complex graphs, such as knowledge graphs with heterogeneous types of entities and relations, is a primary open challenge in the field. Most GCN methods are either restricted to graphs with a homogeneous type of edges (e.g., citation links only), or focusing on representation learning for nodes only instead of jointly propagating and updating the embeddings of both nodes and edges for target-driven objectives. This paper addresses these limitations by proposing a novel framework, namely the Knowledge Embedding based Graph Convolutional Network (KE-GCN), which combines the power of GCNs in graph-based belief propagation and the strengths of advanced knowledge embedding (a.k.a. knowledge graph embedding) methods, and goes beyond. Our theoretical analysis shows that KE-GCN offers an elegant unification of several well-known GCN methods as specific cases, with a new perspective of graph convolution. Experimental results on benchmark datasets show the advantageous performance of KE-GCN over strong baseline methods in the tasks of knowledge graph alignment and entity classification.
As a field of AI, Machine Reasoning (MR) uses largely symbolic means to formalize and emulate abstract reasoning. Studies in early MR have notably started inquiries into Explainable AI (XAI) -- arguably one of the biggest concerns today for the AI community. Work on explainable MR as well as on MR approaches to explainability in other areas of AI has continued ever since. It is especially potent in modern MR branches, such as argumentation, constraint and logic programming, planning. We hereby aim to provide a selective overview of MR explainability techniques and studies in hopes that insights from this long track of research will complement well the current XAI landscape. This document reports our work in-progress on MR explainability.
小貼士
登錄享

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191