
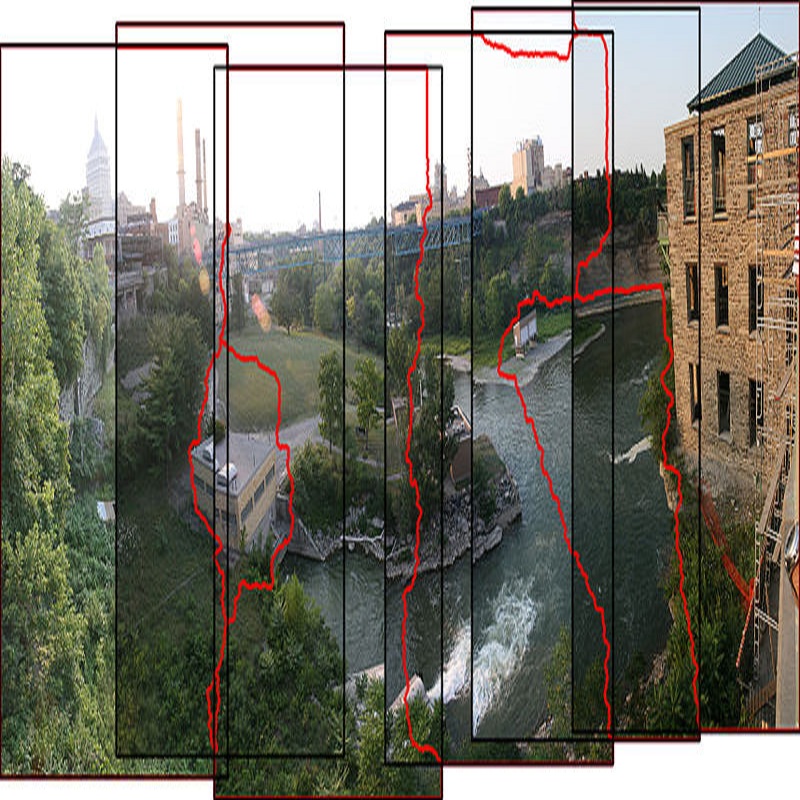

Image stitching is to construct panoramic images with wider field of vision (FOV) from some images captured from different viewing positions. To solve the problem of fusion ghosting in the stitched image, seam-driven methods avoid the misalignment area to fuse images by predicting the best seam. Currently, as standard tools of the OpenCV library, dynamic programming (DP) and GraphCut (GC) are still the only commonly used seam prediction methods despite the fact that they were both proposed two decades ago. However, GC can get excellent seam quality but poor real-time performance while DP method has good efficiency but poor seam quality. In this paper, we propose a deep learning based seam prediction method (DSeam) for the sake of high seam quality with high efficiency. To overcome the difficulty of the seam description in network and no GroundTruth for training we design a selective consistency loss combining the seam shape constraint and seam quality constraint to supervise the network learning. By the constraint of the selection of consistency loss, we implicitly defined the mask boundaries as seams and transform seam prediction into mask prediction. To our knowledge, the proposed DSeam is the first deep learning based seam prediction method for image stitching. Extensive experimental results well demonstrate the superior performance of our proposed Dseam method which is 15 times faster than the classic GC seam prediction method in OpenCV 2.4.9 with similar seam quality.
相關內容
Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at //github.com/longzilicart/GloReDi.
As the focus on Large Language Models (LLMs) in the field of recommendation intensifies, the optimization of LLMs for recommendation purposes (referred to as LLM4Rec) assumes a crucial role in augmenting their effectiveness in providing recommendations. However, existing approaches for LLM4Rec often assess performance using restricted sets of candidates, which may not accurately reflect the models' overall ranking capabilities. In this paper, our objective is to investigate the comprehensive ranking capacity of LLMs and propose a two-step grounding framework known as BIGRec (Bi-step Grounding Paradigm for Recommendation). It initially grounds LLMs to the recommendation space by fine-tuning them to generate meaningful tokens for items and subsequently identifies appropriate actual items that correspond to the generated tokens. By conducting extensive experiments on two datasets, we substantiate the superior performance, capacity for handling few-shot scenarios, and versatility across multiple domains exhibited by BIGRec. Furthermore, we observe that the marginal benefits derived from increasing the quantity of training samples are modest for BIGRec, implying that LLMs possess the limited capability to assimilate statistical information, such as popularity and collaborative filtering, due to their robust semantic priors. These findings also underline the efficacy of integrating diverse statistical information into the LLM4Rec framework, thereby pointing towards a potential avenue for future research. Our code and data are available at //github.com/SAI990323/Grounding4Rec.
Most of the research in content-based image retrieval (CBIR) focus on developing robust feature representations that can effectively retrieve instances from a database of images that are visually similar to a query. However, the retrieved images sometimes contain results that are not semantically related to the query. To address this, we propose a method for CBIR that captures both visual and semantic similarity using a visual hierarchy. The hierarchy is constructed by merging classes with overlapping features in the latent space of a deep neural network trained for classification, assuming that overlapping classes share high visual and semantic similarities. Finally, the constructed hierarchy is integrated into the distance calculation metric for similarity search. Experiments on standard datasets: CUB-200-2011 and CIFAR100, and a real-life use case using diatom microscopy images show that our method achieves superior performance compared to the existing methods on image retrieval.
Learning graph embeddings is a crucial task in graph mining tasks. An effective graph embedding model can learn low-dimensional representations from graph-structured data for data publishing benefiting various downstream applications such as node classification, link prediction, etc. However, recent studies have revealed that graph embeddings are susceptible to attribute inference attacks, which allow attackers to infer private node attributes from the learned graph embeddings. To address these concerns, privacy-preserving graph embedding methods have emerged, aiming to simultaneously consider primary learning and privacy protection through adversarial learning. However, most existing methods assume that representation models have access to all sensitive attributes in advance during the training stage, which is not always the case due to diverse privacy preferences. Furthermore, the commonly used adversarial learning technique in privacy-preserving representation learning suffers from unstable training issues. In this paper, we propose a novel approach called Private Variational Graph AutoEncoders (PVGAE) with the aid of independent distribution penalty as a regularization term. Specifically, we split the original variational graph autoencoder (VGAE) to learn sensitive and non-sensitive latent representations using two sets of encoders. Additionally, we introduce a novel regularization to enforce the independence of the encoders. We prove the theoretical effectiveness of regularization from the perspective of mutual information. Experimental results on three real-world datasets demonstrate that PVGAE outperforms other baselines in private embedding learning regarding utility performance and privacy protection.
Learning directed acyclic graphs (DAGs) to identify causal relations underlying observational data is crucial but also poses significant challenges. Recently, topology-based methods have emerged as a two-step approach to discovering DAGs by first learning the topological ordering of variables and then eliminating redundant edges, while ensuring that the graph remains acyclic. However, one limitation is that these methods would generate numerous spurious edges that require subsequent pruning. To overcome this limitation, in this paper, we propose an improvement to topology-based methods by introducing limited time series data, consisting of only two cross-sectional records that need not be adjacent in time and are subject to flexible timing. By incorporating conditional instrumental variables as exogenous interventions, we aim to identify descendant nodes for each variable. Following this line, we propose a hierarchical topological ordering algorithm with conditional independence test (HT-CIT), which enables the efficient learning of sparse DAGs with a smaller search space compared to other popular approaches. The HT-CIT algorithm greatly reduces the number of edges that need to be pruned. Empirical results from synthetic and real-world datasets demonstrate the superiority of the proposed HT-CIT algorithm.
Data uncertainties, such as sensor noise or occlusions, can introduce irreducible ambiguities in images, which result in varying, yet plausible, semantic hypotheses. In Machine Learning, this ambiguity is commonly referred to as aleatoric uncertainty. Latent density models can be utilized to address this problem in image segmentation. The most popular approach is the Probabilistic U-Net (PU-Net), which uses latent Normal densities to optimize the conditional data log-likelihood Evidence Lower Bound. In this work, we demonstrate that the PU- Net latent space is severely inhomogenous. As a result, the effectiveness of gradient descent is inhibited and the model becomes extremely sensitive to the localization of the latent space samples, resulting in defective predictions. To address this, we present the Sinkhorn PU-Net (SPU-Net), which uses the Sinkhorn Divergence to promote homogeneity across all latent dimensions, effectively improving gradient-descent updates and model robustness. Our results show that by applying this on public datasets of various clinical segmentation problems, the SPU-Net receives up to 11% performance gains compared against preceding latent variable models for probabilistic segmentation on the Hungarian-Matched metric. The results indicate that by encouraging a homogeneous latent space, one can significantly improve latent density modeling for medical image segmentation.
Neuromorphic vision sensors, or event cameras, differ from conventional cameras in that they do not capture images at a specified rate. Instead, they asynchronously log local brightness changes at each pixel. As a result, event cameras only record changes in a given scene, and do so with very high temporal resolution, high dynamic range, and low power requirements. Recent research has demonstrated how these characteristics make event cameras extremely practical sensors in driver monitoring systems (DMS), enabling the tracking of high-speed eye motion and blinks. This research provides a proof of concept to expand event-based DMS techniques to include seatbelt state detection. Using an event simulator, a dataset of 108,691 synthetic neuromorphic frames of car occupants was generated from a near-infrared (NIR) dataset, and split into training, validation, and test sets for a seatbelt state detection algorithm based on a recurrent convolutional neural network (CNN). In addition, a smaller set of real event data was collected and reserved for testing. In a binary classification task, the fastened/unfastened frames were identified with an F1 score of 0.989 and 0.944 on the simulated and real test sets respectively. When the problem extended to also classify the action of fastening/unfastening the seatbelt, respective F1 scores of 0.964 and 0.846 were achieved.
A key component of many graph neural networks (GNNs) is the pooling operation, which seeks to reduce the size of a graph while preserving important structural information. However, most existing graph pooling strategies rely on an assignment matrix obtained by employing a GNN layer, which is characterized by trainable parameters, often leading to significant computational complexity and a lack of interpretability in the pooling process. In this paper, we propose an unsupervised graph encoder-decoder model to detect abnormal nodes from graphs by learning an anomaly scoring function to rank nodes based on their degree of abnormality. In the encoding stage, we design a novel pooling mechanism, named LCPool, which leverages locality-constrained linear coding for feature encoding to find a cluster assignment matrix by solving a least-squares optimization problem with a locality regularization term. By enforcing locality constraints during the coding process, LCPool is designed to be free from learnable parameters, capable of efficiently handling large graphs, and can effectively generate a coarser graph representation while retaining the most significant structural characteristics of the graph. In the decoding stage, we propose an unpooling operation, called LCUnpool, to reconstruct both the structure and nodal features of the original graph. We conduct empirical evaluations of our method on six benchmark datasets using several evaluation metrics, and the results demonstrate its superiority over state-of-the-art anomaly detection approaches.
Visual dialogue is a challenging task that needs to extract implicit information from both visual (image) and textual (dialogue history) contexts. Classical approaches pay more attention to the integration of the current question, vision knowledge and text knowledge, despising the heterogeneous semantic gaps between the cross-modal information. In the meantime, the concatenation operation has become de-facto standard to the cross-modal information fusion, which has a limited ability in information retrieval. In this paper, we propose a novel Knowledge-Bridge Graph Network (KBGN) model by using graph to bridge the cross-modal semantic relations between vision and text knowledge in fine granularity, as well as retrieving required knowledge via an adaptive information selection mode. Moreover, the reasoning clues for visual dialogue can be clearly drawn from intra-modal entities and inter-modal bridges. Experimental results on VisDial v1.0 and VisDial-Q datasets demonstrate that our model outperforms exiting models with state-of-the-art results.
High spectral dimensionality and the shortage of annotations make hyperspectral image (HSI) classification a challenging problem. Recent studies suggest that convolutional neural networks can learn discriminative spatial features, which play a paramount role in HSI interpretation. However, most of these methods ignore the distinctive spectral-spatial characteristic of hyperspectral data. In addition, a large amount of unlabeled data remains an unexploited gold mine for efficient data use. Therefore, we proposed an integration of generative adversarial networks (GANs) and probabilistic graphical models for HSI classification. Specifically, we used a spectral-spatial generator and a discriminator to identify land cover categories of hyperspectral cubes. Moreover, to take advantage of a large amount of unlabeled data, we adopted a conditional random field to refine the preliminary classification results generated by GANs. Experimental results obtained using two commonly studied datasets demonstrate that the proposed framework achieved encouraging classification accuracy using a small number of data for training.

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191