
Non-terrestrial networks (NTNs) will complement terrestrial networks (TNs) in 5G and beyond, which can be attributed to recent deployment and standardization activities. Maximizing the efficiency of NTN communications is critical to unlock its full potential and reap its numerous benefits. One method to make communications more efficient is by the usage of multi-connectivity (MC), which allows a user to connect to multiple base stations simultaneously. It is standardized and widely used for TNs, but for MC to be used in the NTN environment, several challenges must be overcome. In this article, challenges related to MC in NTNs are discussed, and solutions to the identified challenges are proposed.
相關內容
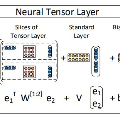
神(shen)經張(zhang)量網絡(luo)(NTN)用一(yi)個雙(shuang)線性(xing)張(zhang)量層(ceng)(ceng)代替(ti)一(yi)個標(biao)準(zhun)的(de)線性(xing)神(shen)經網絡(luo)層(ceng)(ceng),它直(zhi)接關(guan)聯了多個維度上的(de)兩個實體向量。
The classical path planners, such as sampling-based path planners, have the limitations of sensitivity to the initial solution and slow convergence to the optimal solution. However, finding a near-optimal solution in a short period is challenging in many applications such as the autonomous vehicle with limited power/fuel. To achieve an end-to-end near-optimal path planner, we first divide the path planning problem into two subproblems, which are path's space segmentation and waypoints generation in the given path's space. We further propose a two-level cascade neural network named Path Planning Network (PPNet) to solve the path planning problem by solving the abovementioned subproblems. Moreover, we propose a novel efficient data generation method for path planning named EDaGe-PP. The results show the total computation time is less than 1/33 and the success rate of PPNet trained by the dataset that is generated by EDaGe-PP is about $2 \times$ compared to other methods. We validate PPNet against state-of-the-art path planning methods. The results show PPNet can find a near-optimal solution in 15.3ms, which is much shorter than the state-of-the-art path planners.
Addressing trust concerns in Smart Home (SH) systems is imperative due to the limited study on preservation approaches that focus on analyzing and evaluating privacy threats for effective risk management. While most research focuses primarily on user privacy, device data privacy, especially identity privacy, is almost neglected, which can significantly impact overall user privacy within the SH system. To this end, our study incorporates privacy engineering (PE) principles in the SH system that consider user and device data privacy. We start with a comprehensive reference model for a typical SH system. Based on the initial stage of LINDDUN PRO for the PE framework, we present a data flow diagram (DFD) based on a typical SH reference model to better understand SH system operations. To identify potential areas of privacy threat and perform a privacy threat analysis (PTA), we employ the LINDDUN PRO threat model. Then, a privacy impact assessment (PIA) was carried out to implement privacy risk management by prioritizing privacy threats based on their likelihood of occurrence and potential consequences. Finally, we suggest possible privacy enhancement techniques (PETs) that can mitigate some of these threats. The study aims to elucidate the main threats to privacy, associated risks, and effective prioritization of privacy control in SH systems. The outcomes of this study are expected to benefit SH stakeholders, including vendors, cloud providers, users, researchers, and regulatory bodies in the SH systems domain.
Neural networks are known to be susceptible to adversarial samples: small variations of natural examples crafted to deliberately mislead the models. While they can be easily generated using gradient-based techniques in digital and physical scenarios, they often differ greatly from the actual data distribution of natural images, resulting in a trade-off between strength and stealthiness. In this paper, we propose a novel framework dubbed Diffusion-Based Projected Gradient Descent (Diff-PGD) for generating realistic adversarial samples. By exploiting a gradient guided by a diffusion model, Diff-PGD ensures that adversarial samples remain close to the original data distribution while maintaining their effectiveness. Moreover, our framework can be easily customized for specific tasks such as digital attacks, physical-world attacks, and style-based attacks. Compared with existing methods for generating natural-style adversarial samples, our framework enables the separation of optimizing adversarial loss from other surrogate losses (e.g., content/smoothness/style loss), making it more stable and controllable. Finally, we demonstrate that the samples generated using Diff-PGD have better transferability and anti-purification power than traditional gradient-based methods. Code will be released in //github.com/xavihart/Diff-PGD
This article presents the affordances that Generative Artificial Intelligence can have in disinformation context, one of the major threats to our digitalized society. We present a research framework to generate customized agent-based social networks for disinformation simulations that would enable understanding and evaluation of the phenomena whilst discussing open challenges.
Face recognition technology has advanced significantly in recent years due largely to the availability of large and increasingly complex training datasets for use in deep learning models. These datasets, however, typically comprise images scraped from news sites or social media platforms and, therefore, have limited utility in more advanced security, forensics, and military applications. These applications require lower resolution, longer ranges, and elevated viewpoints. To meet these critical needs, we collected and curated the first and second subsets of a large multi-modal biometric dataset designed for use in the research and development (R&D) of biometric recognition technologies under extremely challenging conditions. Thus far, the dataset includes more than 350,000 still images and over 1,300 hours of video footage of approximately 1,000 subjects. To collect this data, we used Nikon DSLR cameras, a variety of commercial surveillance cameras, specialized long-rage R&D cameras, and Group 1 and Group 2 UAV platforms. The goal is to support the development of algorithms capable of accurately recognizing people at ranges up to 1,000 m and from high angles of elevation. These advances will include improvements to the state of the art in face recognition and will support new research in the area of whole-body recognition using methods based on gait and anthropometry. This paper describes methods used to collect and curate the dataset, and the dataset's characteristics at the current stage.
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably their most significant impact has been in the area of computer vision where great advances have been made in challenges such as plausible image generation, image-to-image translation, facial attribute manipulation and similar domains. Despite the significant successes achieved to date, applying GANs to real-world problems still poses significant challenges, three of which we focus on here. These are: (1) the generation of high quality images, (2) diversity of image generation, and (3) stable training. Focusing on the degree to which popular GAN technologies have made progress against these challenges, we provide a detailed review of the state of the art in GAN-related research in the published scientific literature. We further structure this review through a convenient taxonomy we have adopted based on variations in GAN architectures and loss functions. While several reviews for GANs have been presented to date, none have considered the status of this field based on their progress towards addressing practical challenges relevant to computer vision. Accordingly, we review and critically discuss the most popular architecture-variant, and loss-variant GANs, for tackling these challenges. Our objective is to provide an overview as well as a critical analysis of the status of GAN research in terms of relevant progress towards important computer vision application requirements. As we do this we also discuss the most compelling applications in computer vision in which GANs have demonstrated considerable success along with some suggestions for future research directions. Code related to GAN-variants studied in this work is summarized on //github.com/sheqi/GAN_Review.
Since real-world objects and their interactions are often multi-modal and multi-typed, heterogeneous networks have been widely used as a more powerful, realistic, and generic superclass of traditional homogeneous networks (graphs). Meanwhile, representation learning (\aka~embedding) has recently been intensively studied and shown effective for various network mining and analytical tasks. In this work, we aim to provide a unified framework to deeply summarize and evaluate existing research on heterogeneous network embedding (HNE), which includes but goes beyond a normal survey. Since there has already been a broad body of HNE algorithms, as the first contribution of this work, we provide a generic paradigm for the systematic categorization and analysis over the merits of various existing HNE algorithms. Moreover, existing HNE algorithms, though mostly claimed generic, are often evaluated on different datasets. Understandable due to the application favor of HNE, such indirect comparisons largely hinder the proper attribution of improved task performance towards effective data preprocessing and novel technical design, especially considering the various ways possible to construct a heterogeneous network from real-world application data. Therefore, as the second contribution, we create four benchmark datasets with various properties regarding scale, structure, attribute/label availability, and \etc.~from different sources, towards handy and fair evaluations of HNE algorithms. As the third contribution, we carefully refactor and amend the implementations and create friendly interfaces for 13 popular HNE algorithms, and provide all-around comparisons among them over multiple tasks and experimental settings.
Graph neural networks (GNNs) have emerged as a powerful paradigm for embedding-based entity alignment due to their capability of identifying isomorphic subgraphs. However, in real knowledge graphs (KGs), the counterpart entities usually have non-isomorphic neighborhood structures, which easily causes GNNs to yield different representations for them. To tackle this problem, we propose a new KG alignment network, namely AliNet, aiming at mitigating the non-isomorphism of neighborhood structures in an end-to-end manner. As the direct neighbors of counterpart entities are usually dissimilar due to the schema heterogeneity, AliNet introduces distant neighbors to expand the overlap between their neighborhood structures. It employs an attention mechanism to highlight helpful distant neighbors and reduce noises. Then, it controls the aggregation of both direct and distant neighborhood information using a gating mechanism. We further propose a relation loss to refine entity representations. We perform thorough experiments with detailed ablation studies and analyses on five entity alignment datasets, demonstrating the effectiveness of AliNet.

The problem of Multiple Object Tracking (MOT) consists in following the trajectory of different objects in a sequence, usually a video. In recent years, with the rise of Deep Learning, the algorithms that provide a solution to this problem have benefited from the representational power of deep models. This paper provides a comprehensive survey on works that employ Deep Learning models to solve the task of MOT on single-camera videos. Four main steps in MOT algorithms are identified, and an in-depth review of how Deep Learning was employed in each one of these stages is presented. A complete experimental comparison of the presented works on the three MOTChallenge datasets is also provided, identifying a number of similarities among the top-performing methods and presenting some possible future research directions.
Recurrent neural nets (RNN) and convolutional neural nets (CNN) are widely used on NLP tasks to capture the long-term and local dependencies, respectively. Attention mechanisms have recently attracted enormous interest due to their highly parallelizable computation, significantly less training time, and flexibility in modeling dependencies. We propose a novel attention mechanism in which the attention between elements from input sequence(s) is directional and multi-dimensional (i.e., feature-wise). A light-weight neural net, "Directional Self-Attention Network (DiSAN)", is then proposed to learn sentence embedding, based solely on the proposed attention without any RNN/CNN structure. DiSAN is only composed of a directional self-attention with temporal order encoded, followed by a multi-dimensional attention that compresses the sequence into a vector representation. Despite its simple form, DiSAN outperforms complicated RNN models on both prediction quality and time efficiency. It achieves the best test accuracy among all sentence encoding methods and improves the most recent best result by 1.02% on the Stanford Natural Language Inference (SNLI) dataset, and shows state-of-the-art test accuracy on the Stanford Sentiment Treebank (SST), Multi-Genre natural language inference (MultiNLI), Sentences Involving Compositional Knowledge (SICK), Customer Review, MPQA, TREC question-type classification and Subjectivity (SUBJ) datasets.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191