
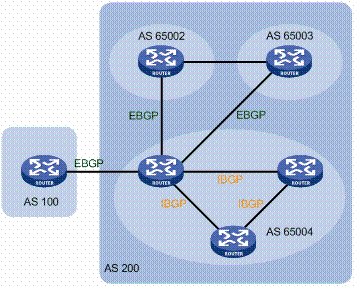

BGP is the protocol that keeps Internet connected. Operators use it by announcing Address Prefixes (APs), namely IP address blocks, that they own or that they agree to serve as transit for. BGP enables ISPs to devise complex policies to control what AP announcements to accept (import policy), the route selection, and what AP to announce and to whom (export policy). In addition, BGP is also used to coarse traffic engineering for incoming traffic via the prepend mechanism. However, there are no wide-spread good tools for managing BGP and much of the complex configuration is done by home-brewed scripts or simply by manually configuring router with bare-bone terminal interface. This process generates many configuration mistakes. In this study, we examine typos that propagates in BGP announcements and can be found in many of the public databases. We classify them and quantify their presence, and surprisingly found tens of ASNs and hundreds of APs affected by typos on any given time. In addition, we suggest a simple algorithm that can detect (and clean) most of them with almost no false positives.
相關內容
Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, which makes them significantly less feasible for real-world situations and introduces security hazards. This paper relaxes the assumptions from previous FDAs and studies a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent, and the target-domain label set is totally blind. Towards a more effective solution for our newly proposed UFDA scenario, we propose a corresponding methodology called Hot-Learning with Contrastive Label Disambiguation (HCLD). It particularly tackles UFDA's domain shifts and category gaps problems by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. Extensive experiments on three benchmark datasets demonstrate that our method achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to previous methodologies with comprehensive additional assumptions.
Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.
Due to the omnipresence of Neural Radiance Fields (NeRFs), the interest towards editable implicit 3D representations has surged over the last years. However, editing implicit or hybrid representations as used for NeRFs is difficult due to the entanglement of appearance and geometry encoded in the model parameters. Despite these challenges, recent research has shown first promising steps towards photorealistic and non-photorealistic appearance edits. The main open issues of related work include limited interactivity, a lack of support for local edits and large memory requirements, rendering them less useful in practice. We address these limitations with LAENeRF, a unified framework for photorealistic and non-photorealistic appearance editing of NeRFs. To tackle local editing, we leverage a voxel grid as starting point for region selection. We learn a mapping from expected ray terminations to final output color, which can optionally be supervised by a style loss, resulting in a framework which can perform photorealistic and non-photorealistic appearance editing of selected regions. Relying on a single point per ray for our mapping, we limit memory requirements and enable fast optimization. To guarantee interactivity, we compose the output color using a set of learned, modifiable base colors, composed with additive layer mixing. Compared to concurrent work, LAENeRF enables recoloring and stylization while keeping processing time low. Furthermore, we demonstrate that our approach surpasses baseline methods both quantitatively and qualitatively.
The goal of 3D mesh watermarking is to embed the message in 3D meshes that can withstand various attacks imperceptibly and reconstruct the message accurately from watermarked meshes. The watermarking algorithm is supposed to withstand multiple attacks, and the complexity should not grow significantly with the mesh size. Unfortunately, previous methods are less robust against attacks and lack of adaptability. In this paper, we propose a robust and adaptable deep 3D mesh watermarking Deep3DMark that leverages attention-based convolutions in watermarking tasks to embed binary messages in vertex distributions without texture assistance. Furthermore, our Deep3DMark exploits the property that simplified meshes inherit similar relations from the original ones, where the relation is the offset vector directed from one vertex to its neighbor. By doing so, our method can be trained on simplified meshes but remains effective on large size meshes (size adaptable) and unseen categories of meshes (geometry adaptable). Extensive experiments demonstrate our method remains efficient and effective even if the mesh size is 190x increased. Under mesh attacks, Deep3DMark achieves 10%~50% higher accuracy than traditional methods, and 2x higher SNR and 8% higher accuracy than previous DNN-based methods.
Besides entity-centric knowledge, usually organized as Knowledge Graph (KG), events are also an essential kind of knowledge in the world, which trigger the spring up of event-centric knowledge representation form like Event KG (EKG). It plays an increasingly important role in many machine learning and artificial intelligence applications, such as intelligent search, question-answering, recommendation, and text generation. This paper provides a comprehensive survey of EKG from history, ontology, instance, and application views. Specifically, to characterize EKG thoroughly, we focus on its history, definitions, schema induction, acquisition, related representative graphs/systems, and applications. The development processes and trends are studied therein. We further summarize perspective directions to facilitate future research on EKG.
Despite the recent progress in Graph Neural Networks (GNNs), it remains challenging to explain the predictions made by GNNs. Existing explanation methods mainly focus on post-hoc explanations where another explanatory model is employed to provide explanations for a trained GNN. The fact that post-hoc methods fail to reveal the original reasoning process of GNNs raises the need of building GNNs with built-in interpretability. In this work, we propose Prototype Graph Neural Network (ProtGNN), which combines prototype learning with GNNs and provides a new perspective on the explanations of GNNs. In ProtGNN, the explanations are naturally derived from the case-based reasoning process and are actually used during classification. The prediction of ProtGNN is obtained by comparing the inputs to a few learned prototypes in the latent space. Furthermore, for better interpretability and higher efficiency, a novel conditional subgraph sampling module is incorporated to indicate which part of the input graph is most similar to each prototype in ProtGNN+. Finally, we evaluate our method on a wide range of datasets and perform concrete case studies. Extensive results show that ProtGNN and ProtGNN+ can provide inherent interpretability while achieving accuracy on par with the non-interpretable counterparts.
Graph Neural Networks (GNNs) are information processing architectures for signals supported on graphs. They are presented here as generalizations of convolutional neural networks (CNNs) in which individual layers contain banks of graph convolutional filters instead of banks of classical convolutional filters. Otherwise, GNNs operate as CNNs. Filters are composed with pointwise nonlinearities and stacked in layers. It is shown that GNN architectures exhibit equivariance to permutation and stability to graph deformations. These properties provide a measure of explanation respecting the good performance of GNNs that can be observed empirically. It is also shown that if graphs converge to a limit object, a graphon, GNNs converge to a corresponding limit object, a graphon neural network. This convergence justifies the transferability of GNNs across networks with different number of nodes.
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in computer vision field, applying GANs over real-world problems still have three main challenges: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Considering numerous GAN-related research in the literature, we provide a study on the architecture-variants and loss-variants, which are proposed to handle these three challenges from two perspectives. We propose loss and architecture-variants for classifying most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented, there is no work focusing on the review of GAN-variants based on handling challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on //github.com/sheqi/GAN_Review.
Generative Adversarial Networks (GANs) have recently achieved impressive results for many real-world applications, and many GAN variants have emerged with improvements in sample quality and training stability. However, they have not been well visualized or understood. How does a GAN represent our visual world internally? What causes the artifacts in GAN results? How do architectural choices affect GAN learning? Answering such questions could enable us to develop new insights and better models. In this work, we present an analytic framework to visualize and understand GANs at the unit-, object-, and scene-level. We first identify a group of interpretable units that are closely related to object concepts using a segmentation-based network dissection method. Then, we quantify the causal effect of interpretable units by measuring the ability of interventions to control objects in the output. We examine the contextual relationship between these units and their surroundings by inserting the discovered object concepts into new images. We show several practical applications enabled by our framework, from comparing internal representations across different layers, models, and datasets, to improving GANs by locating and removing artifact-causing units, to interactively manipulating objects in a scene. We provide open source interpretation tools to help researchers and practitioners better understand their GAN models.
ASR (automatic speech recognition) systems like Siri, Alexa, Google Voice or Cortana has become quite popular recently. One of the key techniques enabling the practical use of such systems in people's daily life is deep learning. Though deep learning in computer vision is known to be vulnerable to adversarial perturbations, little is known whether such perturbations are still valid on the practical speech recognition. In this paper, we not only demonstrate such attacks can happen in reality, but also show that the attacks can be systematically conducted. To minimize users' attention, we choose to embed the voice commands into a song, called CommandSong. In this way, the song carrying the command can spread through radio, TV or even any media player installed in the portable devices like smartphones, potentially impacting millions of users in long distance. In particular, we overcome two major challenges: minimizing the revision of a song in the process of embedding commands, and letting the CommandSong spread through the air without losing the voice "command". Our evaluation demonstrates that we can craft random songs to "carry" any commands and the modify is extremely difficult to be noticed. Specially, the physical attack that we play the CommandSongs over the air and record them can success with 94 percentage.
小貼士
登錄享



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191