
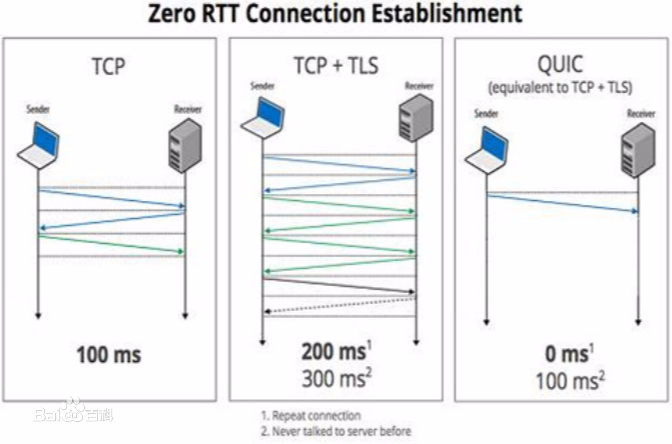

Multicast enables efficient one-to-many communications. Several applications benefit from its scalability properties, e.g., live-streaming and large-scale software updates. Historically, multicast applications have used specialized transport protocols. The flexibility of the recently standardized QUIC protocol opens the possibility of providing both unicast and multicast services to applications with a single transport protocol. We present MCQUIC, an extended version of the QUIC protocol that supports multicast communications. We show how QUIC features and built-in security can be leveraged for multicast transport. We present the design of MCQUIC and implement it in Cloudflare quiche. We assess its performance through benchmarks and in emulated networks under realistic scenarios. We also demonstrate MCQUIC in a campus network. By coupling QUIC with our multicast extension, applications can rely on multicast for efficiency with the possibility to fall back on unicast in case of incompatible network conditions.
相關內容
IMP-MARL: a Suite of Environments for Large-scale Infrastructure Management Planning via MARL
We introduce IMP-MARL, an open-source suite of multi-agent reinforcement learning (MARL) environments for large-scale Infrastructure Management Planning (IMP), offering a platform for benchmarking the scalability of cooperative MARL methods in real-world engineering applications. In IMP, a multi-component engineering system is subject to a risk of failure due to its components' damage condition. Specifically, each agent plans inspections and repairs for a specific system component, aiming to minimise maintenance costs while cooperating to minimise system failure risk. With IMP-MARL, we release several environments including one related to offshore wind structural systems, in an effort to meet today's needs to improve management strategies to support sustainable and reliable energy systems. Supported by IMP practical engineering environments featuring up to 100 agents, we conduct a benchmark campaign, where the scalability and performance of state-of-the-art cooperative MARL methods are compared against expert-based heuristic policies. The results reveal that centralised training with decentralised execution methods scale better with the number of agents than fully centralised or decentralised RL approaches, while also outperforming expert-based heuristic policies in most IMP environments. Based on our findings, we additionally outline remaining cooperation and scalability challenges that future MARL methods should still address. Through IMP-MARL, we encourage the implementation of new environments and the further development of MARL methods.
Inspired by the dual-process theory of human cognition, we introduce DUMA, a novel conversational agent framework that embodies a dual-mind mechanism through the utilization of two generative Large Language Models (LLMs) dedicated to fast and slow thinking respectively. The fast thinking model serves as the primary interface for external interactions and initial response generation, evaluating the necessity for engaging the slow thinking model based on the complexity of the complete response. When invoked, the slow thinking model takes over the conversation, engaging in meticulous planning, reasoning, and tool utilization to provide a well-analyzed response. This dual-mind configuration allows for a seamless transition between intuitive responses and deliberate problem-solving processes based on the situation. We have constructed a conversational agent to handle online inquiries in the real estate industry. The experiment proves that our method balances effectiveness and efficiency, and has a significant improvement compared to the baseline.
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at //www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at //drive-anywhere.github.io/.
As artificial intelligence (AI) gains greater adoption in a wide variety of applications, it has immense potential to contribute to mathematical discovery, by guiding conjecture generation, constructing counterexamples, assisting in formalizing mathematics, and discovering connections between different mathematical areas, to name a few. While prior work has leveraged computers for exhaustive mathematical proof search, recent efforts based on large language models (LLMs) aspire to position computing platforms as co-contributors in the mathematical research process. Despite their current limitations in logic and mathematical tasks, there is growing interest in melding theorem proving systems with foundation models. This work investigates the applicability of LLMs in formalizing advanced mathematical concepts and proposes a framework that can critically review and check mathematical reasoning in research papers. Given the noted reasoning shortcomings of LLMs, our approach synergizes the capabilities of proof assistants, specifically PVS, with LLMs, enabling a bridge between textual descriptions in academic papers and formal specifications in PVS. By harnessing the PVS environment, coupled with data ingestion and conversion mechanisms, we envision an automated process, called \emph{math-PVS}, to extract and formalize mathematical theorems from research papers, offering an innovative tool for academic review and discovery.
This work presents StrAE: a Structured Autoencoder framework that through strict adherence to explicit structure, and use of a novel contrastive objective over tree-structured representations, enables effective learning of multi-level representations. Through comparison over different forms of structure, we verify that our results are directly attributable to the informativeness of the structure provided as input, and show that this is not the case for existing tree models. We then further extend StrAE to allow the model to define its own compositions using a simple localised-merge algorithm. This variant, called Self-StrAE, outperforms baselines that don't involve explicit hierarchical compositions, and is comparable to models given informative structure (e.g. constituency parses). Our experiments are conducted in a data-constrained (circa 10M tokens) setting to help tease apart the contribution of the inductive bias to effective learning. However, we find that this framework can be robust to scale, and when extended to a much larger dataset (circa 100M tokens), our 430 parameter model performs comparably to a 6-layer RoBERTa many orders of magnitude larger in size. Our findings support the utility of incorporating explicit composition as an inductive bias for effective representation learning.
This work presents a camera model for refractive media such as water and its application in underwater visual-inertial odometry. The model is self-calibrating in real-time and is free of known correspondences or calibration targets. It is separable as a distortion model (dependent on refractive index $n$ and radial pixel coordinate) and a virtual pinhole model (as a function of $n$). We derive the self-calibration formulation leveraging epipolar constraints to estimate the refractive index and subsequently correct for distortion. Through experimental studies using an underwater robot integrating cameras and inertial sensing, the model is validated regarding the accurate estimation of the refractive index and its benefits for robust odometry estimation in an extended envelope of conditions. Lastly, we show the transition between media and the estimation of the varying refractive index online, thus allowing computer vision tasks across refractive media.
In order to build reliable and trustworthy NLP applications, models need to be both fair across different demographics and explainable. Usually these two objectives, fairness and explainability, are optimized and/or examined independently of each other. Instead, we argue that forthcoming, trustworthy NLP systems should consider both. In this work, we perform a first study to understand how they influence each other: do fair(er) models rely on more plausible rationales? and vice versa. To this end, we conduct experiments on two English multi-class text classification datasets, BIOS and ECtHR, that provide information on gender and nationality, respectively, as well as human-annotated rationales. We fine-tune pre-trained language models with several methods for (i) bias mitigation, which aims to improve fairness; (ii) rationale extraction, which aims to produce plausible explanations. We find that bias mitigation algorithms do not always lead to fairer models. Moreover, we discover that empirical fairness and explainability are orthogonal.
The construction of large open knowledge bases (OKBs) is integral to many applications in the field of mobile computing. Noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. However, in order to meet the requirements of some privacy protection regulations and to ensure the timeliness of the data, the canonicalized OKB often needs to remove some sensitive information or outdated data. The machine unlearning in OKB canonicalization is an excellent solution to the above problem. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Effective schemes are urgently needed to fully synergise machine unlearning with clustering and KGE learning. To this end, we put forward a multi-task unlearning framework, namely MulCanon, to tackle machine unlearning problem in OKB canonicalization. Specifically, the noise characteristics in the diffusion model are utilized to achieve the effect of machine unlearning for data in OKB. MulCanon unifies the learning objectives of diffusion model, KGE and clustering algorithms, and adopts a two-step multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization datasets validates that MulCanon achieves advanced machine unlearning effects.
This paper surveys vision-language pre-training (VLP) methods for multimodal intelligence that have been developed in the last few years. We group these approaches into three categories: ($i$) VLP for image-text tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding; ($ii$) VLP for core computer vision tasks, such as (open-set) image classification, object detection, and segmentation; and ($iii$) VLP for video-text tasks, such as video captioning, video-text retrieval, and video question answering. For each category, we present a comprehensive review of state-of-the-art methods, and discuss the progress that has been made and challenges still being faced, using specific systems and models as case studies. In addition, for each category, we discuss advanced topics being actively explored in the research community, such as big foundation models, unified modeling, in-context few-shot learning, knowledge, robustness, and computer vision in the wild, to name a few.
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.
小貼士
登錄享
相關主題

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191