


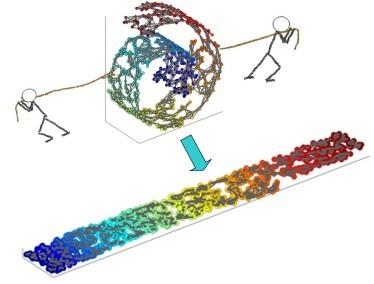
As a pivotal approach in machine learning and data science, manifold learning aims to uncover the intrinsic low-dimensional structure within complex nonlinear manifolds in high-dimensional space. By exploiting the manifold hypothesis, various techniques for nonlinear dimension reduction have been developed to facilitate visualization, classification, clustering, and gaining key insights. Although existing manifold learning methods have achieved remarkable successes, they still suffer from extensive distortions incurred in the global structure, which hinders the understanding of underlying patterns. Scalability issues also limit their applicability for handling large-scale data. Here, we propose a scalable manifold learning (scML) method that can manipulate large-scale and high-dimensional data in an efficient manner. It starts by seeking a set of landmarks to construct the low-dimensional skeleton of the entire data and then incorporates the non-landmarks into the landmark space based on the constrained locally linear embedding (CLLE). We empirically validated the effectiveness of scML on synthetic datasets and real-world benchmarks of different types, and applied it to analyze the single-cell transcriptomics and detect anomalies in electrocardiogram (ECG) signals. scML scales well with increasing data sizes and exhibits promising performance in preserving the global structure. The experiments demonstrate notable robustness in embedding quality as the sample rate decreases.
相關內容
Federated Learning is a machine learning approach that enables the training of a deep learning model among several participants with sensitive data that wish to share their own knowledge without compromising the privacy of their data. In this research, the authors employ a secured Federated Learning method with an additional layer of privacy and proposes a method for addressing the non-IID challenge. Moreover, differential privacy is compared with chaotic-based encryption as layer of privacy. The experimental approach assesses the performance of the federated deep learning model with differential privacy using both IID and non-IID data. In each experiment, the Federated Learning process improves the average performance metrics of the deep neural network, even in the case of non-IID data.
Under a generalised estimating equation analysis approach, approximate design theory is used to determine Bayesian D-optimal designs. For two examples, considering simple exchangeable and exponential decay correlation structures, we compare the efficiency of identified optimal designs to balanced stepped-wedge designs and corresponding stepped-wedge designs determined by optimising using a normal approximation approach. The dependence of the Bayesian D-optimal designs on the assumed correlation structure is explored; for the considered settings, smaller decay in the correlation between outcomes across time periods, along with larger values of the intra-cluster correlation, leads to designs closer to a balanced design being optimal. Unlike for normal data, it is shown that the optimal design need not be centro-symmetric in the binary outcome case. The efficiency of the Bayesian D-optimal design relative to a balanced design can be large, but situations are demonstrated in which the advantages are small. Similarly, the optimal design from a normal approximation approach is often not much less efficient than the Bayesian D-optimal design. Bayesian D-optimal designs can be readily identified for stepped-wedge cluster randomised trials with binary outcome data. In certain circumstances, principally ones with strong time period effects, they will indicate that a design unlikely to have been identified by previous methods may be substantially more efficient. However, they require a larger number of assumptions than existing optimal designs, and in many situations existing theory under a normal approximation will provide an easier means of identifying an efficient design for binary outcome data.
The latest generative large language models (LLMs) have found their application in data augmentation tasks, where small numbers of text samples are LLM-paraphrased and then used to fine-tune downstream models. However, more research is needed to assess how different prompts, seed data selection strategies, filtering methods, or model settings affect the quality of paraphrased data (and downstream models). In this study, we investigate three text diversity incentive methods well established in crowdsourcing: taboo words, hints by previous outlier solutions, and chaining on previous outlier solutions. Using these incentive methods as part of instructions to LLMs augmenting text datasets, we measure their effects on generated texts lexical diversity and downstream model performance. We compare the effects over 5 different LLMs, 6 datasets and 2 downstream models. We show that diversity is most increased by taboo words, but downstream model performance is highest with hints.
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.
The standard approach to modern self-supervised learning is to generate random views through data augmentations and minimise a loss computed from the representations of these views. This inherently encourages invariance to the transformations that comprise the data augmentation function. In this work, we show that adding a module to constrain the representations to be predictive of an affine transformation improves the performance and efficiency of the learning process. The module is agnostic to the base self-supervised model and manifests in the form of an additional loss term that encourages an aggregation of the encoder representations to be predictive of an affine transformation applied to the input images. We perform experiments in various modern self-supervised models and see a performance improvement in all cases. Further, we perform an ablation study on the components of the affine transformation to understand which of them is affecting performance the most, as well as on key architectural design decisions.
Based on interactions between individuals and others and references to social norms, this study reveals the impact of heterogeneity in time preference on wealth distribution and inequality. We present a novel approach that connects the interactions between microeconomic agents that generate heterogeneity to the dynamic equations for capital and consumption in macroeconomic models. Using this approach, we estimate the impact of changes in the discount rate due to microeconomic interactions on capital, consumption and utility and the degree of inequality. The results show that intercomparisons with others regarding consumption significantly affect capital, i.e. wealth inequality. Furthermore, the impact on utility is never small and social norms can reduce this impact. Our supporting evidence shows that the quantitative results of inequality calculations correspond to survey data from cohort and cross-cultural studies. This study's micro-macro connection approach can be deployed to connect microeconomic interactions, such as exchange, interest and debt, redistribution, mutual aid and time preference, to dynamic macroeconomic models.
Mesh-based Graph Neural Networks (GNNs) have recently shown capabilities to simulate complex multiphysics problems with accelerated performance times. However, mesh-based GNNs require a large number of message-passing (MP) steps and suffer from over-smoothing for problems involving very fine mesh. In this work, we develop a multiscale mesh-based GNN framework mimicking a conventional iterative multigrid solver, coupled with adaptive mesh refinement (AMR), to mitigate challenges with conventional mesh-based GNNs. We use the framework to accelerate phase field (PF) fracture problems involving coupled partial differential equations with a near-singular operator due to near-zero modulus inside the crack. We define the initial graph representation using all mesh resolution levels. We perform a series of downsampling steps using Transformer MP GNNs to reach the coarsest graph followed by upsampling steps to reach the original graph. We use skip connectors from the generated embedding during coarsening to prevent over-smoothing. We use Transfer Learning (TL) to significantly reduce the size of training datasets needed to simulate different crack configurations and loading conditions. The trained framework showed accelerated simulation times, while maintaining high accuracy for all cases compared to physics-based PF fracture model. Finally, this work provides a new approach to accelerate a variety of mesh-based engineering multiphysics problems
Artificial neural networks thrive in solving the classification problem for a particular rigid task, acquiring knowledge through generalized learning behaviour from a distinct training phase. The resulting network resembles a static entity of knowledge, with endeavours to extend this knowledge without targeting the original task resulting in a catastrophic forgetting. Continual learning shifts this paradigm towards networks that can continually accumulate knowledge over different tasks without the need to retrain from scratch. We focus on task incremental classification, where tasks arrive sequentially and are delineated by clear boundaries. Our main contributions concern 1) a taxonomy and extensive overview of the state-of-the-art, 2) a novel framework to continually determine the stability-plasticity trade-off of the continual learner, 3) a comprehensive experimental comparison of 11 state-of-the-art continual learning methods and 4 baselines. We empirically scrutinize method strengths and weaknesses on three benchmarks, considering Tiny Imagenet and large-scale unbalanced iNaturalist and a sequence of recognition datasets. We study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented, and qualitatively compare methods in terms of required memory, computation time, and storage.
Deep learning is usually described as an experiment-driven field under continuous criticizes of lacking theoretical foundations. This problem has been partially fixed by a large volume of literature which has so far not been well organized. This paper reviews and organizes the recent advances in deep learning theory. The literature is categorized in six groups: (1) complexity and capacity-based approaches for analyzing the generalizability of deep learning; (2) stochastic differential equations and their dynamic systems for modelling stochastic gradient descent and its variants, which characterize the optimization and generalization of deep learning, partially inspired by Bayesian inference; (3) the geometrical structures of the loss landscape that drives the trajectories of the dynamic systems; (4) the roles of over-parameterization of deep neural networks from both positive and negative perspectives; (5) theoretical foundations of several special structures in network architectures; and (6) the increasingly intensive concerns in ethics and security and their relationships with generalizability.
Deep learning constitutes a recent, modern technique for image processing and data analysis, with promising results and large potential. As deep learning has been successfully applied in various domains, it has recently entered also the domain of agriculture. In this paper, we perform a survey of 40 research efforts that employ deep learning techniques, applied to various agricultural and food production challenges. We examine the particular agricultural problems under study, the specific models and frameworks employed, the sources, nature and pre-processing of data used, and the overall performance achieved according to the metrics used at each work under study. Moreover, we study comparisons of deep learning with other existing popular techniques, in respect to differences in classification or regression performance. Our findings indicate that deep learning provides high accuracy, outperforming existing commonly used image processing techniques.

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191