


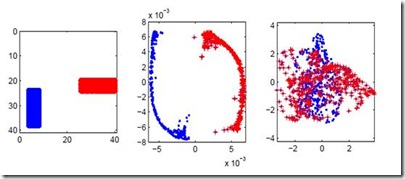
Most existing graph visualization methods based on dimension reduction are limited to relatively small graphs due to performance issues. In this work, we propose a novel dimension reduction method for graph visualization, called t-Distributed Stochastic Graph Neighbor Embedding (t-SGNE). t-SGNE is specifically designed to visualize cluster structures in the graph. As a variant of the standard t-SNE method, t-SGNE avoids the time-consuming computations of pairwise similarity. Instead, it uses the neighbor structures of the graph to reduce the time complexity from quadratic to linear, thus supporting larger graphs. In addition, to suit t-SGNE, we combined Laplacian Eigenmaps with the shortest path algorithm in graphs to form the graph embedding algorithm ShortestPath Laplacian Eigenmaps Embedding (SPLEE). Performing SPLEE to obtain a high-dimensional embedding of the large-scale graph and then using t-SGNE to reduce its dimension for visualization, we are able to visualize graphs with up to 300K nodes and 1M edges within 5 minutes and achieve approximately 10% improvement in visualization quality. Codes and data are available at //github.com/Charlie-XIAO/embedding-visualization-test.
相關內容
Quantum error-correcting codes are crucial for quantum computing and communication. Currently, these codes are mainly categorized into additive, non-additive, and surface codes. Additive and non-additive codes utilize one or more invariant subspaces of the stabilizer G to construct quantum codes. Therefore, the selection of these invariant subspaces is a key issue. In this paper, we propose a solution to this problem by introducing quotient space codes and a construction method for quotient space quantum codes. This new framework unifies additive and non-additive quantum codes. We demonstrate the codeword stabilizer codes as a special case within this framework and supplement its error-correction distance. Furthermore, we provide a simple proof of the Singleton bound for this quantum code by establishing the code bound of quotient space codes and discuss the code bounds for pure and impure codes. The quotient space approach offers a concise and clear mathematical form for the study of quantum codes.
The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users' modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.
Recent language models generate false but plausible-sounding text with surprising frequency. Such "hallucinations" are an obstacle to the usability of language-based AI systems and can harm people who rely upon their outputs. This work shows shows that there is an inherent statistical lower-bound on the rate that pretrained language models hallucinate certain types of facts, having nothing to do with the transformer LM architecture or data quality. For "arbitrary" facts whose veracity cannot be determined from the training data, we show that hallucinations must occur at a certain rate for language models that satisfy a statistical calibration condition appropriate for generative language models. Specifically, if the maximum probability of any fact is bounded, we show that the probability of generating a hallucination is close to the fraction of facts that occur exactly once in the training data (a "Good-Turing" estimate), even assuming ideal training data without errors. One conclusion is that models pretrained to be sufficiently good predictors (i.e., calibrated) may require post-training to mitigate hallucinations on the type of arbitrary facts that tend to appear once in the training set. However, our analysis also suggests that there is no statistical reason that pretraining will lead to hallucination on facts that tend to appear more than once in the training data (like references to publications such as articles and books, whose hallucinations have been particularly notable and problematic) or on systematic facts (like arithmetic calculations). Therefore, different architectures and learning algorithms may mitigate these latter types of hallucinations.
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
Shape-morphing capabilities are crucial for enabling multifunctionality in both biological and artificial systems. Various strategies for shape morphing have been proposed for applications in metamaterials and robotics. However, few of these approaches have achieved the ability to seamlessly transform into a multitude of volumetric shapes post-fabrication using a relatively simple actuation and control mechanism. Taking inspiration from thick origami and hierarchies in nature, we present a new hierarchical construction method based on polyhedrons to create an extensive library of compact origami metastructures. We show that a single hierarchical origami structure can autonomously adapt to over 103 versatile architectural configurations, achieved with the utilization of fewer than 3 actuation degrees of freedom and employing simple transition kinematics. We uncover the fundamental principles governing theses shape transformation through theoretical models. Furthermore, we also demonstrate the wide-ranging potential applications of these transformable hierarchical structures. These include their uses as untethered and autonomous robotic transformers capable of various gait-shifting and multidirectional locomotion, as well as rapidly self-deployable and self-reconfigurable architecture, exemplifying its scalability up to the meter scale. Lastly, we introduce the concept of multitask reconfigurable and deployable space robots and habitats, showcasing the adaptability and versatility of these metastructures.
This paper presents a new approach for assembling graph neural networks based on framelet transforms. The latter provides a multi-scale representation for graph-structured data. With the framelet system, we can decompose the graph feature into low-pass and high-pass frequencies as extracted features for network training, which then defines a framelet-based graph convolution. The framelet decomposition naturally induces a graph pooling strategy by aggregating the graph feature into low-pass and high-pass spectra, which considers both the feature values and geometry of the graph data and conserves the total information. The graph neural networks with the proposed framelet convolution and pooling achieve state-of-the-art performance in many types of node and graph prediction tasks. Moreover, we propose shrinkage as a new activation for the framelet convolution, which thresholds the high-frequency information at different scales. Compared to ReLU, shrinkage in framelet convolution improves the graph neural network model in terms of denoising and signal compression: noises in both node and structure can be significantly reduced by accurately cutting off the high-pass coefficients from framelet decomposition, and the signal can be compressed to less than half its original size with the prediction performance well preserved.
The aim of this work is to develop a fully-distributed algorithmic framework for training graph convolutional networks (GCNs). The proposed method is able to exploit the meaningful relational structure of the input data, which are collected by a set of agents that communicate over a sparse network topology. After formulating the centralized GCN training problem, we first show how to make inference in a distributed scenario where the underlying data graph is split among different agents. Then, we propose a distributed gradient descent procedure to solve the GCN training problem. The resulting model distributes computation along three lines: during inference, during back-propagation, and during optimization. Convergence to stationary solutions of the GCN training problem is also established under mild conditions. Finally, we propose an optimization criterion to design the communication topology between agents in order to match with the graph describing data relationships. A wide set of numerical results validate our proposal. To the best of our knowledge, this is the first work combining graph convolutional neural networks with distributed optimization.
Graph neural networks (GNNs) have been widely used in representation learning on graphs and achieved state-of-the-art performance in tasks such as node classification and link prediction. However, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. In this paper, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which involve identifying useful connections between unconnected nodes on the original graph, while learning effective node representation on the new graphs in an end-to-end fashion. Graph Transformer layer, a core layer of GTNs, learns a soft selection of edge types and composite relations for generating useful multi-hop connections so-called meta-paths. Our experiments show that GTNs learn new graph structures, based on data and tasks without domain knowledge, and yield powerful node representation via convolution on the new graphs. Without domain-specific graph preprocessing, GTNs achieved the best performance in all three benchmark node classification tasks against the state-of-the-art methods that require pre-defined meta-paths from domain knowledge.
Knowledge graph (KG) embedding encodes the entities and relations from a KG into low-dimensional vector spaces to support various applications such as KG completion, question answering, and recommender systems. In real world, knowledge graphs (KGs) are dynamic and evolve over time with addition or deletion of triples. However, most existing models focus on embedding static KGs while neglecting dynamics. To adapt to the changes in a KG, these models need to be re-trained on the whole KG with a high time cost. In this paper, to tackle the aforementioned problem, we propose a new context-aware Dynamic Knowledge Graph Embedding (DKGE) method which supports the embedding learning in an online fashion. DKGE introduces two different representations (i.e., knowledge embedding and contextual element embedding) for each entity and each relation, in the joint modeling of entities and relations as well as their contexts, by employing two attentive graph convolutional networks, a gate strategy, and translation operations. This effectively helps limit the impacts of a KG update in certain regions, not in the entire graph, so that DKGE can rapidly acquire the updated KG embedding by a proposed online learning algorithm. Furthermore, DKGE can also learn KG embedding from scratch. Experiments on the tasks of link prediction and question answering in a dynamic environment demonstrate the effectiveness and efficiency of DKGE.
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191