

Several approaches to image stitching use different constraints to estimate the motion model between image pairs. These constraints can be roughly divided into two categories: geometric constraints and photometric constraints. In this paper, geometric and photometric constraints are combined to improve the alignment quality, which is based on the observation that these two kinds of constraints are complementary. On the one hand, geometric constraints (e.g., point and line correspondences) are usually spatially biased and are insufficient in some extreme scenes, while photometric constraints are always evenly and densely distributed. On the other hand, photometric constraints are sensitive to displacements and are not suitable for images with large parallaxes, while geometric constraints are usually imposed by feature matching and are more robust to handle parallaxes. The proposed method therefore combines them together in an efficient mesh-based image warping framework. It achieves better alignment quality than methods only with geometric constraints, and can handle larger parallax than photometric-constraint-based method. Experimental results on various images illustrate that the proposed method outperforms representative state-of-the-art image stitching methods reported in the literature.
相關內容
Recent studies in image retrieval task have shown that ensembling different models and combining multiple global descriptors lead to performance improvement. However, training different models for ensemble is not only difficult but also inefficient with respect to time or memory. In this paper, we propose a novel framework that exploits multiple global descriptors to get an ensemble-like effect while it can be trained in an end-to-end manner. The proposed framework is flexible and expandable by the global descriptor, CNN backbone, loss, and dataset. Moreover, we investigate the effectiveness of combining multiple global descriptors with quantitative and qualitative analysis. Our extensive experiments show that the combined descriptor outperforms a single global descriptor, as it can utilize different types of feature properties. In the benchmark evaluation, the proposed framework achieves the state-of-the-art performance on the CARS196, CUB200-2011, In-shop Clothes and Stanford Online Products on image retrieval tasks by a large margin compared to competing approaches. Our model implementations and pretrained models are publicly available.
Recognition of Off-line Chinese characters is still a challenging problem, especially in historical documents, not only in the number of classes extremely large in comparison to contemporary image retrieval methods, but also new unseen classes can be expected under open learning conditions (even for CNN). Chinese character recognition with zero or a few training samples is a difficult problem and has not been studied yet. In this paper, we propose a new Chinese character recognition method by multi-type attributes, which are based on pronunciation, structure and radicals of Chinese characters, applied to character recognition in historical books. This intermediate attribute code has a strong advantage over the common `one-hot' class representation because it allows for understanding complex and unseen patterns symbolically using attributes. First, each character is represented by four groups of attribute types to cover a wide range of character possibilities: Pinyin label, layout structure, number of strokes, three different input methods such as Cangjie, Zhengma and Wubi, as well as a four-corner encoding method. A convolutional neural network (CNN) is trained to learn these attributes. Subsequently, characters can be easily recognized by these attributes using a distance metric and a complete lexicon that is encoded in attribute space. We evaluate the proposed method on two open data sets: printed Chinese character recognition for zero-shot learning, historical characters for few-shot learning and a closed set: handwritten Chinese characters. Experimental results show a good general classification of seen classes but also a very promising generalization ability to unseen characters.
This paper addresses the problem of head detection in crowded environments. Our detection is based entirely on the geometric consistency across cameras with overlapping fields of view, and no additional learning process is required. We propose a fully unsupervised method for inferring scene and camera geometry, in contrast to existing algorithms which require specific calibration procedures. Moreover, we avoid relying on the presence of body parts other than heads or on background subtraction, which have limited effectiveness under heavy clutter. We cast the head detection problem as a stereo MRF-based optimization of a dense pedestrian height map, and we introduce a constraint which aligns the height gradient according to the vertical vanishing point direction. We validate the method in an outdoor setting with varying pedestrian density levels. With only three views, our approach is able to detect simultaneously tens of heavily occluded pedestrians across a large, homogeneous area.
Learning compact binary codes for image retrieval problem using deep neural networks has attracted increasing attention recently. However, training deep hashing networks is challenging due to the binary constraints on the hash codes, the similarity preserving property, and the requirement for a vast amount of labelled images. To the best of our knowledge, none of the existing methods has tackled all of these challenges completely in a unified framework. In this work, we propose a novel end-to-end deep hashing approach, which is trained to produce binary codes directly from image pixels without the need of manual annotation. In particular, we propose a novel pairwise binary constrained loss function, which simultaneously encodes the distances between pairs of hash codes, and the binary quantization error. In order to train the network with the proposed loss function, we also propose an efficient parameter learning algorithm. In addition, to provide similar/dissimilar training images to train the network, we exploit 3D models reconstructed from unlabelled images for automatic generation of enormous similar/dissimilar pairs. Extensive experiments on three image retrieval benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art hashing methods on the image retrieval problem.
Scene coordinate regression has become an essential part of current camera re-localization methods. Different versions, such as regression forests and deep learning methods, have been successfully applied to estimate the corresponding camera pose given a single input image. In this work, we propose to regress the scene coordinates pixel-wise for a given RGB image by using deep learning. Compared to the recent methods, which usually employ RANSAC to obtain a robust pose estimate from the established point correspondences, we propose to regress confidences of these correspondences, which allows us to immediately discard erroneous predictions and improve the initial pose estimates. Finally, the resulting confidences can be used to score initial pose hypothesis and aid in pose refinement, offering a generalized solution to solve this task.
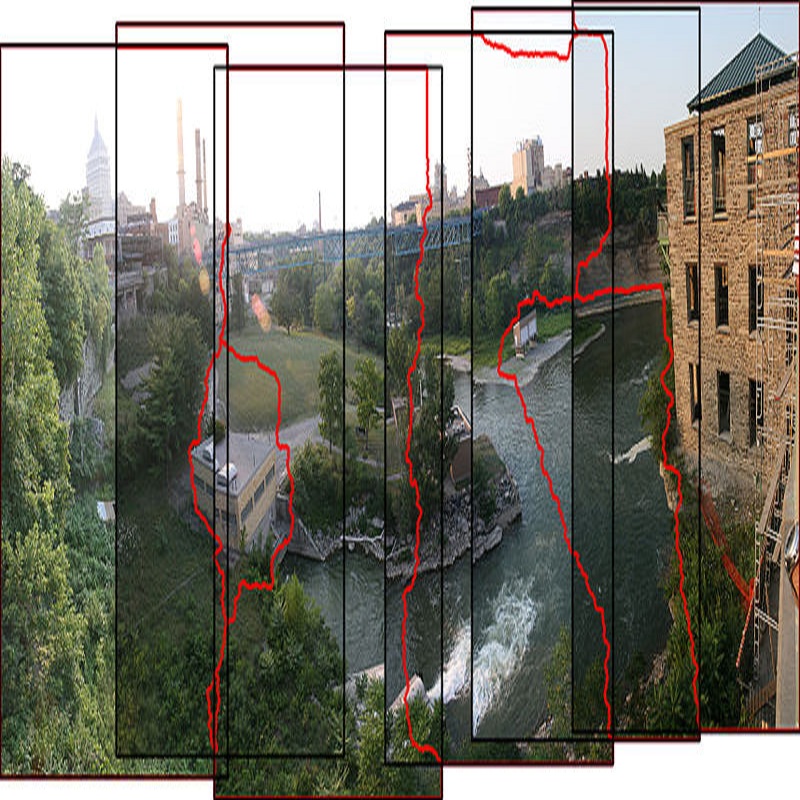
Seam-cutting and seam-driven techniques have been proven effective for handling imperfect image series in image stitching. Generally, seam-driven is to utilize seam-cutting to find a best seam from one or finite alignment hypotheses based on a predefined seam quality metric. However, the quality metrics in most methods are defined to measure the average performance of the pixels on the seam without considering the relevance and variance among them. This may cause that the seam with the minimal measure is not optimal (perception-inconsistent) in human perception. In this paper, we propose a novel coarse-to-fine seam estimation method which applies the evaluation in a different way. For pixels on the seam, we develop a patch-point evaluation algorithm concentrating more on the correlation and variation of them. The evaluations are then used to recalculate the difference map of the overlapping region and reestimate a stitching seam. This evaluation-reestimation procedure iterates until the current seam changes negligibly comparing with the previous seams. Experiments show that our proposed method can finally find a nearly perception-consistent seam after several iterations, which outperforms the conventional seam-cutting and other seam-driven methods.
Similarity/Distance measures play a key role in many machine learning, pattern recognition, and data mining algorithms, which leads to the emergence of metric learning field. Many metric learning algorithms learn a global distance function from data that satisfy the constraints of the problem. However, in many real-world datasets that the discrimination power of features varies in the different regions of input space, a global metric is often unable to capture the complexity of the task. To address this challenge, local metric learning methods are proposed that learn multiple metrics across the different regions of input space. Some advantages of these methods are high flexibility and the ability to learn a nonlinear mapping but typically achieves at the expense of higher time requirement and overfitting problem. To overcome these challenges, this research presents an online multiple metric learning framework. Each metric in the proposed framework is composed of a global and a local component learned simultaneously. Adding a global component to a local metric efficiently reduce the problem of overfitting. The proposed framework is also scalable with both sample size and the dimension of input data. To the best of our knowledge, this is the first local online similarity/distance learning framework based on PA (Passive/Aggressive). In addition, for scalability with the dimension of input data, DRP (Dual Random Projection) is extended for local online learning in the present work. It enables our methods to be run efficiently on high-dimensional datasets, while maintains their predictive performance. The proposed framework provides a straightforward local extension to any global online similarity/distance learning algorithm based on PA.
In this paper, a novel video classification methodology is presented that aims to recognize different categories of third-person videos efficiently. The idea is to keep track of motion in videos by following optical flow elements over time. To classify the resulted motion time series efficiently, the idea is letting the machine to learn temporal features along the time dimension. This is done by training a multi-channel one dimensional Convolutional Neural Network (1D-CNN). Since CNNs represent the input data hierarchically, high level features are obtained by further processing of features in lower level layers. As a result, in the case of time series, long-term temporal features are extracted from short-term ones. Besides, the superiority of the proposed method over most of the deep-learning based approaches is that we only try to learn representative temporal features along the time dimension. This reduces the number of learning parameters significantly which results in trainability of our method on even smaller datasets. It is illustrated that the proposed method could reach state-of-the-art results on two public datasets UCF11 and jHMDB with the aid of a more efficient feature vector representation.
Results of image stitching can be perceptually divided into single-perspective and multiple-perspective. Compared to the multiple-perspective result, the single-perspective result excels in perspective consistency but suffers from projective distortion. In this paper, we propose two single-perspective warps for natural image stitching. The first one is a parametric warp, which is a combination of the as-projective-as-possible warp and the quasi-homography warp via dual-feature. The second one is a mesh-based warp, which is determined by optimizing a total energy function that simultaneously emphasizes different characteristics of the single-perspective warp, including alignment, naturalness, distortion and saliency. A comprehensive evaluation demonstrates that the proposed warp outperforms some state-of-the-art warps, including homography, APAP, AutoStitch, SPHP and GSP.
We propose an attentive local feature descriptor suitable for large-scale image retrieval, referred to as DELF (DEep Local Feature). The new feature is based on convolutional neural networks, which are trained only with image-level annotations on a landmark image dataset. To identify semantically useful local features for image retrieval, we also propose an attention mechanism for keypoint selection, which shares most network layers with the descriptor. This framework can be used for image retrieval as a drop-in replacement for other keypoint detectors and descriptors, enabling more accurate feature matching and geometric verification. Our system produces reliable confidence scores to reject false positives---in particular, it is robust against queries that have no correct match in the database. To evaluate the proposed descriptor, we introduce a new large-scale dataset, referred to as Google-Landmarks dataset, which involves challenges in both database and query such as background clutter, partial occlusion, multiple landmarks, objects in variable scales, etc. We show that DELF outperforms the state-of-the-art global and local descriptors in the large-scale setting by significant margins. Code and dataset can be found at the project webpage: //github.com/tensorflow/models/tree/master/research/delf .
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191