

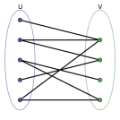
We address two open problems in sorting with priced information, introduced by [Charikar, Fagin, Guruswami, Kleinberg, Raghavan, Sahai (CFGKRS), STOC 2000]. In this setting, different comparisons have different (potentially infinite) costs. The goal is to find a sorting algorithm with small competitive ratio, defined as the (worst-case) ratio of the algorithm's cost to the cost of the cheapest proof of the sorted order. 1) When all costs are in $\{0,1,n,\infty\}$, we give an algorithm that has $\widetilde{O}(n^{3/4})$ competitive ratio. Our result refutes the hypothesis that a widely cited $\Omega(n)$ lower bound on the competitive ratio for finding the maximum extends to sorting. This lower bound by [Gupta, Kumar, FOCS 2000] uses costs in $\{0,1,n, \infty\}$ and was claimed as the reason why sorting with arbitrary costs seemed bleak and hopeless. Our algorithm also generalizes the algorithms for generalized sorting (all costs in $\{1,\infty\}$), a version initiated by [Huang, Kannan, Khanna, FOCS 2011] and addressed recently by [Kuszmaul, Narayanan, FOCS 2021]. 2) We answer the problem of bichromatic sorting posed by [CFGKRS]: We are given two sets $A$ and $B$ of total size $n$, and the cost of an $A-A$ comparison or a $B-B$ comparison is higher than an $A-B$ comparison. The goal is to sort $A \cup B$. An $\Omega(\log n)$ lower bound on competitive ratio follows from unit-cost sorting. We give a randomized algorithm with an almost-optimal w.h.p. competitive ratio of $O(\log^{3} n)$. We also study generalizations of the problem \emph{universal sorting} and \emph{bipartite sorting} (a generalization of nuts-and-bolts). Here, we define a notion of \textit{instance optimality}, and develop an algorithm for bipartite sorting which is $O(\log^{3} n)$ instance-optimal. Our framework of instance optimality applies to other static problems and may be of independent interest.
相關內容
Given an undirected graph $G$ and a conductance parameter $\alpha$, the problem of testing whether $G$ has conductance at least $\alpha$ or is far from having conductance at least $\Omega(\alpha^2)$ has been extensively studied for bounded-degree graphs in the classic property testing model. In the last few years, the same problem has also been addressed in non-sequential models of computing such as MPC and distributed CONGEST. However, all the algorithms in these models like their classic counterparts apply an aggregate function over some statistics pertaining to a set of random walks on $G$ as a test criteria. The only distributed CONGEST algorithm for the problem by~\cite{VasudevDistributed} tests conductance of the underlying network in the unbounded degree graph model. Their algorithm builds a rooted spanning tree of the underlying network to collect information at the root and then applies an aggregate function to this information. We ask the question whether the parallelism offered by distributed computing can be exploited to avoid information collection and answer it in affirmative. We propose a new algorithm which also performs a set of random walks on $G$ but does not collect any statistic at a central node. In fact, we show that for an appropriate statistic, each node has sufficient information to decide on its own whether to accept or not. Given an $n$-vertex, $m$-edge undirected, unweighted graph $G$, a conductance parameter $\alpha$, and a distance parameter $\epsilon$, our distributed conductance tester accepts $G$ if $G$ has conductance at least $\alpha$ and rejects $G$ if $G$ is $\epsilon$-far from having conductance $\Omega(\alpha^2)$ and does so in $O(\log n)$ rounds of communication. Unlike the algorithm of \cite{VasudevDistributed}, our algorithm does not rely on the wasteful construction of a spanning tree and information accumulation at its root.
Intelligent Mesh Generation (IMG) represents a novel and promising field of research, utilizing machine learning techniques to generate meshes. Despite its relative infancy, IMG has significantly broadened the adaptability and practicality of mesh generation techniques, delivering numerous breakthroughs and unveiling potential future pathways. However, a noticeable void exists in the contemporary literature concerning comprehensive surveys of IMG methods. This paper endeavors to fill this gap by providing a systematic and thorough survey of the current IMG landscape. With a focus on 113 preliminary IMG methods, we undertake a meticulous analysis from various angles, encompassing core algorithm techniques and their application scope, agent learning objectives, data types, targeted challenges, as well as advantages and limitations. We have curated and categorized the literature, proposing three unique taxonomies based on key techniques, output mesh unit elements, and relevant input data types. This paper also underscores several promising future research directions and challenges in IMG. To augment reader accessibility, a dedicated IMG project page is available at \url{//github.com/xzb030/IMG_Survey}.
We study the continuous time limit of a self-exciting negative binomial process and discuss the critical properties of its intensity distribution. In this limit, the process transforms into a marked Hawkes process. The probability mass function of the marks has a parameter $\omega$, and the process reduces to a "pure" Hawkes process in the limit $\omega\to 0$. We investigate the Lagrange--Charpit equations for the master equations of the marked Hawkes process in the Laplace representation close to its critical point and extend the previous findings on the power-law scaling of the probability density function (PDF) of intensities in the intermediate asymptotic regime to the case where the memory kernel is the superposition of an arbitrary finite number of exponentials. We develop an efficient sampling method for the marked Hawkes process based on the time-rescaling theorem and verify the power-law exponents.
We are interested in the nonparametric estimation of the probability density of price returns, using the kernel approach. The output of the method heavily relies on the selection of a bandwidth parameter. Many selection methods have been proposed in the statistical literature. We put forward an alternative selection method based on a criterion coming from information theory and from the physics of complex systems: the bandwidth to be selected maximizes a new measure of complexity, with the aim of avoiding both overfitting and underfitting. We review existing methods of bandwidth selection and show that they lead to contradictory conclusions regarding the complexity of the probability distribution of price returns. This has also some striking consequences in the evaluation of the relevance of the efficient market hypothesis. We apply these methods to real financial data, focusing on the Bitcoin.
Nowadays, more and more problems are dealing with data with one infinite continuous dimension: functional data. In this paper, we introduce the funLOCI algorithm which allows to identify functional local clusters or functional loci, i.e., subsets/groups of functions exhibiting similar behaviour across the same continuous subset of the domain. The definition of functional local clusters leverages ideas from multivariate and functional clustering and biclustering and it is based on an additive model which takes into account the shape of the curves. funLOCI is a three-step algorithm based on divisive hierarchical clustering. The use of dendrograms allows to visualize and to guide the searching procedure and the cutting thresholds selection. To deal with the large quantity of local clusters, an extra step is implemented to reduce the number of results to the minimum.
Federated learning (FL) shines through in the internet of things (IoT) with its ability to realize collaborative learning and improve learning efficiency by sharing client model parameters trained on local data. Although FL has been successfully applied to various domains, including driver monitoring applications (DMAs) on the internet of vehicles (IoV), its usages still face some open issues, such as data and system heterogeneity, large-scale parallelism communication resources, malicious attacks, and data poisoning. This paper proposes a federated transfer-ordered-personalized learning (FedTOP) framework to address the above problems and test on two real-world datasets with and without system heterogeneity. The performance of the three extensions, transfer, ordered, and personalized, is compared by an ablation study and achieves 92.32% and 95.96% accuracy on the test clients of two datasets, respectively. Compared to the baseline, there is a 462% improvement in accuracy and a 37.46% reduction in communication resource consumption. The results demonstrate that the proposed FedTOP can be used as a highly accurate, streamlined, privacy-preserving, cybersecurity-oriented, and personalized framework for DMA.
The classical analysis of Stochastic Gradient Descent (SGD) with polynomially decaying stepsize $\eta_t = \eta/\sqrt{t}$ relies on well-tuned $\eta$ depending on problem parameters such as Lipschitz smoothness constant, which is often unknown in practice. In this work, we prove that SGD with arbitrary $\eta > 0$, referred to as untuned SGD, still attains an order-optimal convergence rate $\widetilde{O}(T^{-1/4})$ in terms of gradient norm for minimizing smooth objectives. Unfortunately, it comes at the expense of a catastrophic exponential dependence on the smoothness constant, which we show is unavoidable for this scheme even in the noiseless setting. We then examine three families of adaptive methods $\unicode{x2013}$ Normalized SGD (NSGD), AMSGrad, and AdaGrad $\unicode{x2013}$ unveiling their power in preventing such exponential dependency in the absence of information about the smoothness parameter and boundedness of stochastic gradients. Our results provide theoretical justification for the advantage of adaptive methods over untuned SGD in alleviating the issue with large gradients.
Accurate and efficient estimation of rare events probabilities is of significant importance, since often the occurrences of such events have widespread impacts. The focus in this work is on precisely quantifying these probabilities, often encountered in reliability analysis of complex engineering systems, based on an introduced framework termed Approximate Sampling Target with Post-processing Adjustment (ASTPA), which herein is integrated with and supported by gradient-based Hamiltonian Markov Chain Monte Carlo (HMCMC) methods. The developed techniques in this paper are applicable from low- to high-dimensional stochastic spaces, and the basic idea is to construct a relevant target distribution by weighting the original random variable space through a one-dimensional output likelihood model, using the limit-state function. To sample from this target distribution, we exploit HMCMC algorithms, a family of MCMC methods that adopts physical system dynamics, rather than solely using a proposal probability distribution, to generate distant sequential samples, and we develop a new Quasi-Newton mass preconditioned HMCMC scheme (QNp-HMCMC), which is particularly efficient and suitable for high-dimensional spaces. To eventually compute the rare event probability, an original post-sampling step is devised using an inverse importance sampling procedure based on the already obtained samples. The statistical properties of the estimator are analyzed as well, and the performance of the proposed methodology is examined in detail and compared against Subset Simulation in a series of challenging low- and high-dimensional problems.
We study the problem of crowdsourced PAC learning of threshold functions. This is a challenging problem and only recently have query-efficient algorithms been established under the assumption that a noticeable fraction of the workers are perfect. In this work, we investigate a more challenging case where the majority may behave adversarially and the rest behave as the Massart noise - a significant generalization of the perfectness assumption. We show that under the {semi-verified model} of Charikar et al. (2017), where we have (limited) access to a trusted oracle who always returns correct annotations, it is possible to PAC learn the underlying hypothesis class with a manageable amount of label queries. Moreover, we show that the labeling cost can be drastically mitigated via the more easily obtained comparison queries. Orthogonal to recent developments in semi-verified or list-decodable learning that crucially rely on data distributional assumptions, our PAC guarantee holds by exploring the wisdom of the crowd.
Modern neural network training relies heavily on data augmentation for improved generalization. After the initial success of label-preserving augmentations, there has been a recent surge of interest in label-perturbing approaches, which combine features and labels across training samples to smooth the learned decision surface. In this paper, we propose a new augmentation method that leverages the first and second moments extracted and re-injected by feature normalization. We replace the moments of the learned features of one training image by those of another, and also interpolate the target labels. As our approach is fast, operates entirely in feature space, and mixes different signals than prior methods, one can effectively combine it with existing augmentation methods. We demonstrate its efficacy across benchmark data sets in computer vision, speech, and natural language processing, where it consistently improves the generalization performance of highly competitive baseline networks.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191