
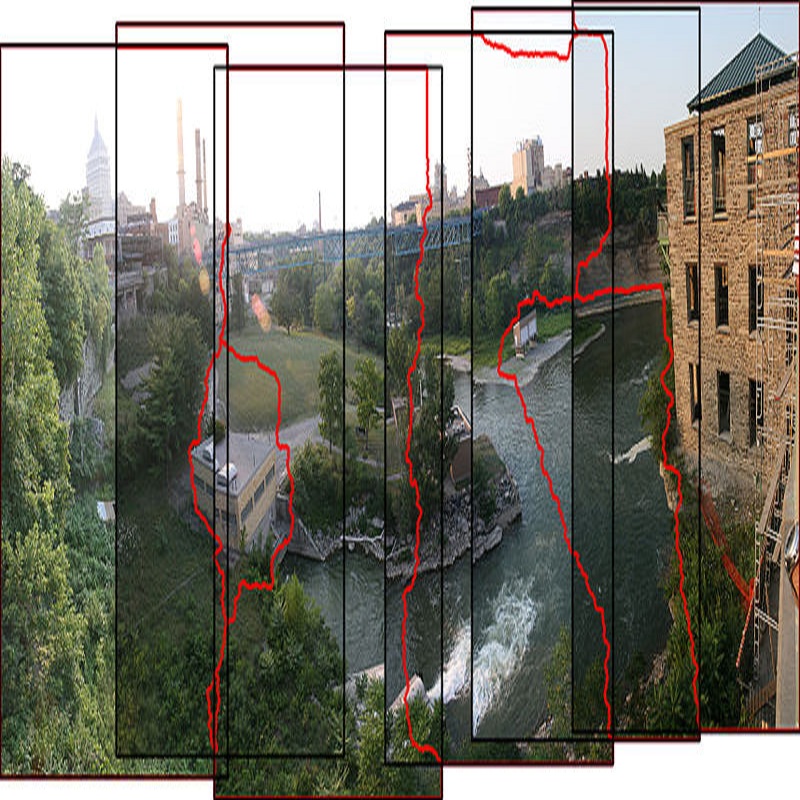

Learning-based image stitching techniques typically involve three distinct stages: registration, fusion, and rectangling. These stages are often performed sequentially, each trained independently, leading to potential cascading error propagation and complex parameter tuning challenges. In rethinking the mathematical modeling of the fusion and rectangling stages, we discovered that these processes can be effectively combined into a single, variety-intensity inpainting problem. Therefore, we propose the Simple and Robust Stitcher (SRStitcher), an efficient training-free image stitching method that merges the fusion and rectangling stages into a unified model. By employing the weighted mask and large-scale generative model, SRStitcher can solve the fusion and rectangling problems in a single inference, without additional training or fine-tuning of other models. Our method not only simplifies the stitching pipeline but also enhances fault tolerance towards misregistration errors. Extensive experiments demonstrate that SRStitcher outperforms state-of-the-art (SOTA) methods in both quantitative assessments and qualitative evaluations. The code is released at //github.com/yayoyo66/SRStitcher
相關內容
Large language models (LLMs) demonstrate exceptional instruct-following ability to complete various downstream tasks. Although this impressive ability makes LLMs flexible task solvers, their performance in solving tasks also heavily relies on instructions. In this paper, we reveal that LLMs are over-sensitive to lexical variations in task instructions, even when the variations are imperceptible to humans. By providing models with neighborhood instructions, which are closely situated in the latent representation space and differ by only one semantically similar word, the performance on downstream tasks can be vastly different. Following this property, we propose a black-box Combinatorial Optimization framework for Prompt Lexical Enhancement (COPLE). COPLE performs iterative lexical optimization according to the feedback from a batch of proxy tasks, using a search strategy related to word influence. Experiments show that even widely-used human-crafted prompts for current benchmarks suffer from the lexical sensitivity of models, and COPLE recovers the declined model ability in both instruct-following and solving downstream tasks.
Current methods to prevent crypto asset fraud are based on the analysis of transaction graphs within blockchain networks. While effective for identifying transaction patterns indicative of fraud, it does not capture the semantics of transactions and is constrained to blockchain data. Consequently, preventive methods based on transaction graphs are inherently limited. In response to these limitations, we propose the Kosmosis approach, which aims to incrementally construct a knowledge graph as new blockchain and social media data become available. During construction, it aims to extract the semantics of transactions and connect blockchain addresses to their real-world entities by fusing blockchain and social media data in a knowledge graph. This enables novel preventive methods against rug pulls as a form of crypto asset fraud. To demonstrate the effectiveness and practical applicability of the Kosmosis approach, we examine a series of real-world rug pulls from 2021. Through this case, we illustrate how Kosmosis can aid in identifying and preventing such fraudulent activities by leveraging the insights from the constructed knowledge graph.
Experimental materials science is experiencing significant growth due to automated experimentation and AI techniques. Integrated autonomous platforms are emerging, combining generative models, robotics, simulations, and automated systems for material synthesis. However, two major challenges remain: democratizing access to these technologies and creating accessible infrastructure for under-resourced scientists. This paper introduces the Quantum Data Hub (QDH), a community-accessible research infrastructure aimed at researchers working with quantum materials. QDH integrates with the National Data Platform, adhering to FAIR principles while proposing additional UNIT principles for usability, navigability, interpretability, and timeliness. The QDH facilitates collaboration and extensibility, allowing seamless integration of new researchers, instruments, and data into the system.
Node embedding learns low-dimensional vectors for nodes in the graph. Recent state-of-the-art embedding approaches take Personalized PageRank (PPR) as the proximity measure and factorize the PPR matrix or its adaptation to generate embeddings. However, little previous work analyzes what information is encoded by these approaches, and how the information correlates with their superb performance in downstream tasks. In this work, we first show that state-of-the-art embedding approaches that factorize a PPR-related matrix can be unified into a closed-form framework. Then, we study whether the embeddings generated by this strategy can be inverted to better recover the graph topology information than random-walk based embeddings. To achieve this, we propose two methods for recovering graph topology via PPR-based embeddings, including the analytical method and the optimization method. Extensive experimental results demonstrate that the embeddings generated by factorizing a PPR-related matrix maintain more topological information, such as common edges and community structures, than that generated by random walks, paving a new way to systematically comprehend why PPR-based node embedding approaches outperform random walk-based alternatives in various downstream tasks. To the best of our knowledge, this is the first work that focuses on the interpretability of PPR-based node embedding approaches.
Decision making demands intricate interplay between perception, memory, and reasoning to discern optimal policies. Conventional approaches to decision making face challenges related to low sample efficiency and poor generalization. In contrast, foundation models in language and vision have showcased rapid adaptation to diverse new tasks. Therefore, we advocate for the construction of foundation agents as a transformative shift in the learning paradigm of agents. This proposal is underpinned by the formulation of foundation agents with their fundamental characteristics and challenges motivated by the success of large language models (LLMs). Moreover, we specify the roadmap of foundation agents from large interactive data collection or generation, to self-supervised pretraining and adaptation, and knowledge and value alignment with LLMs. Lastly, we pinpoint critical research questions derived from the formulation and delineate trends for foundation agents supported by real-world use cases, addressing both technical and theoretical aspects to propel the field towards a more comprehensive and impactful future.
Computed tomography (CT) relies on precise patient immobilization during image acquisition. Nevertheless, motion artifacts in the reconstructed images can persist. Motion compensation methods aim to correct such artifacts post-acquisition, often incorporating temporal smoothness constraints on the estimated motion patterns. This study analyzes the influence of a spline-based motion model within an existing rigid motion compensation algorithm for cone-beam CT on the recoverable motion frequencies. Results demonstrate that the choice of motion model crucially influences recoverable frequencies. The optimization-based motion compensation algorithm is able to accurately fit the spline nodes for frequencies almost up to the node-dependent theoretical limit according to the Nyquist-Shannon theorem. Notably, a higher node count does not compromise reconstruction performance for slow motion patterns, but can extend the range of recoverable high frequencies for the investigated algorithm. Eventually, the optimal motion model is dependent on the imaged anatomy, clinical use case, and scanning protocol and should be tailored carefully to the expected motion frequency spectrum to ensure accurate motion compensation.
As image recognition models become more prevalent, scalable coding methods for machines and humans gain more importance. Applications of image recognition models include traffic monitoring and farm management. In these use cases, the scalable coding method proves effective because the tasks require occasional image checking by humans. Existing image compression methods for humans and machines meet these requirements to some extent. However, these compression methods are effective solely for specific image recognition models. We propose a learning-based scalable image coding method for humans and machines that is compatible with numerous image recognition models. We combine an image compression model for machines with a compression model, providing additional information to facilitate image decoding for humans. The features in these compression models are fused using a feature fusion network to achieve efficient image compression. Our method's additional information compression model is adjusted to reduce the number of parameters by enabling combinations of features of different sizes in the feature fusion network. Our approach confirms that the feature fusion network efficiently combines image compression models while reducing the number of parameters. Furthermore, we demonstrate the effectiveness of the proposed scalable coding method by evaluating the image compression performance in terms of decoded image quality and bitrate.
Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
Big models have achieved revolutionary breakthroughs in the field of AI, but they might also pose potential concerns. Addressing such concerns, alignment technologies were introduced to make these models conform to human preferences and values. Despite considerable advancements in the past year, various challenges lie in establishing the optimal alignment strategy, such as data cost and scalable oversight, and how to align remains an open question. In this survey paper, we comprehensively investigate value alignment approaches. We first unpack the historical context of alignment tracing back to the 1920s (where it comes from), then delve into the mathematical essence of alignment (what it is), shedding light on the inherent challenges. Following this foundation, we provide a detailed examination of existing alignment methods, which fall into three categories: Reinforcement Learning, Supervised Fine-Tuning, and In-context Learning, and demonstrate their intrinsic connections, strengths, and limitations, helping readers better understand this research area. In addition, two emerging topics, personal alignment, and multimodal alignment, are also discussed as novel frontiers in this field. Looking forward, we discuss potential alignment paradigms and how they could handle remaining challenges, prospecting where future alignment will go.
This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
小貼士
登錄享



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191