

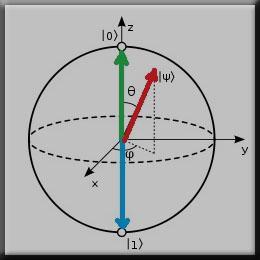
Noisy Intermediate-Scale Quantum (NISQ) quantum computers are being rapidly improved, with bigger numbers of qubits and improved fidelity. The rapidly increasing qubit counts and improving the fidelity of quantum computers will enable novel algorithms to be executed on the quantum computers, and generate novel results and data whose intellectual property will be a highly-guarded secret. At the same time, quantum computers are likely to remain specialized machines, and many will be controlled and maintained in a remote, cloud-based environment where end users who want to come up with novel algorithms have no control over the physical space. Lack of physical control by users means that physical attacks could be possible, by malicious insiders in the data center, for example. This work shows for the first time that power-based side-channel attacks could be deployed against quantum computers. The attacks could be used to recover information about the control pulses sent to quantum computers. From the control pulses, the gate level description of the circuits, and eventually the secret algorithms can be reverse engineered. This work demonstrates how and what information could be recovered, and then in turn how to defend from power-based side-channels. Real control pulse information from real quantum computers is used to demonstrate potential power-based side-channel attacks. Meanwhile, proposed defenses can be deployed already today, without hardware changes.
相關內容
Complexity theory typically focuses on the difficulty of solving computational problems using classical inputs and outputs, even with a quantum computer. In the quantum world, it is natural to apply a different notion of complexity, namely the complexity of synthesizing quantum states. We investigate a state-synthesizing counterpart of the class NP, referred to as stateQMA, which is concerned with preparing certain quantum states through a polynomial-time quantum verifier with the aid of a single quantum message from an all-powerful but untrusted prover. This is a subclass of the class stateQIP recently introduced by Rosenthal and Yuen (ITCS 2022), which permits polynomially many interactions between the prover and the verifier. Our main result consists of error reduction of this class and its variants with an exponentially small gap or a bounded space, as well as how this class relates to other fundamental state synthesizing classes, i.e., states generated by uniform polynomial-time quantum circuits (stateBQP) and space-uniform polynomial-space quantum circuits (statePSPACE). Additionally, we demonstrate that stateQCMA is closed under perfect completeness. Our proof techniques are based on the quantum singular value transformation introduced by Gily\'en, Su, Low, and Wiebe (STOC 2019), and its adaption to achieve exponential precision with a bounded space.
The complexity class Quantum Statistical Zero-Knowledge ($\mathsf{QSZK}$) captures computational difficulties of quantum state testing with respect to the trace distance for efficiently preparable mixed states (Quantum State Distinguishability Problem, QSDP), as introduced by Watrous (FOCS 2002). However, this class faces the same parameter issue as its classical counterpart, because of error reduction for the QSDP (the polarization lemma), as demonstrated by Sahai and Vadhan (JACM, 2003). In this paper, we introduce quantum analogues of triangular discrimination, which is a symmetric version of the $\chi^2$ divergence, and investigate the quantum state testing problems for quantum triangular discrimination and quantum Jensen-Shannon divergence (a symmetric version of the quantum relative entropy). These new $\mathsf{QSZK}$-complete problems allow us to improve the parameter regime for testing quantum states in trace distance and examine the limitations of existing approaches to polarization. Additionally, we prove that the quantum state testing for trace distance with negligible errors is in $\mathsf{PP}$ while the same problem without error is in $\mathsf{BQP}_1$. This result suggests that achieving length-preserving polarization for QSDP seems implausible unless $\mathsf{QSZK}$ is in $\mathsf{PP}$.
The bounded quantum storage model aims to achieve security against computationally unbounded adversaries that are restricted only with respect to their quantum memories. In this work, we provide information-theoretic secure constructions in this model for the following powerful primitives: (1) CCA1-secure symmetric key encryption, message authentication codes, and one-time programs. These schemes require no quantum memory for the honest user, while they can be made secure against adversaries with arbitrarily large memories by increasing the transmission length sufficiently. (2) CCA1-secure asymmetric key encryption, encryption tokens, signatures, signature tokens, and program broadcast. These schemes are secure against adversaries with roughly $e^{\sqrt{m}}$ quantum memory where $m$ is the quantum memory required for the honest user. All of the constructions additionally satisfy notions of disappearing and unclonable security.
Masking is a widely-used effective countermeasure against power side-channel attacks for implementing cryptographic algorithms. Surprisingly, few formal verification techniques have addressed a fundamental question, i.e., whether the masked program and the original (unmasked) cryptographic algorithm are functional equivalent. In this paper, we study this problem for masked arithmetic programs over Galois fields of characteristic 2. We propose an automated approach based on term rewriting, aided by random testing and SMT solving. The overall approach is sound, and complete under certain conditions which do meet in practice. We implement the approach as a new tool FISCHER and carry out extensive experiments on various benchmarks. The results confirm the effectiveness, efficiency and scalability of our approach. Almost all the benchmarks can be proved for the first time by the term rewriting system solely. In particular, FISCHER detects a new flaw in a masked implementation published in EUROCRYPT 2017.
Gate-defined quantum dots (QDs) have appealing attributes as a quantum computing platform. However, near-term devices possess a range of possible imperfections that need to be accounted for during the tuning and operation of QD devices. One such problem is the capacitive cross-talk between the metallic gates that define and control QD qubits. A way to compensate for the capacitive cross-talk and enable targeted control of specific QDs independent of coupling is by the use of virtual gates. Here, we demonstrate a reliable automated capacitive coupling identification method that combines machine learning with traditional fitting to take advantage of the desirable properties of each. We also show how the cross-capacitance measurement may be used for the identification of spurious QDs sometimes formed during tuning experimental devices. Our systems can autonomously flag devices with spurious dots near the operating regime, which is crucial information for reliable tuning to a regime suitable for qubit operations.
This paper introduces the application of the weak Galerkin (WG) finite element method to solve the Steklov eigenvalue problem, focusing on obtaining lower bounds of the eigenvalues. The noncomforming finite element space of the weak Galerkin finite element method is the key to obtain lower bounds of the eigenvalues. The arbitary high order lower bound estimates are given and the guaranteed lower bounds of the eigenvalues are also discussed. Numerical results demonstrate the accuracy and lower bound property of the numerical scheme.
Digital contactless payments have replaced physical banknotes in many aspects of our daily lives. Similarly to banknotes, they are easy to use, unique, tamper-resistant and untraceable, but additionally have to withstand attackers and data breaches in the digital world. Current technology substitutes customers' sensitive data by randomized tokens, and secures the uniqueness of each digital purchase with a cryptographic function, called a cryptogram. However, computationally powerful attacks violate the security of these functions. Quantum technology, on the other hand, has the unique potential to guarantee payment protection even in the presence of infinite computational power. Here, we show how quantum light can secure daily digital payments in a practical manner by generating inherently unforgeable quantum-cryptograms. We implement the full scheme over an urban optical fiber link, and show its robustness to noise and loss-dependent attacks. Unlike previously proposed quantum-security protocols, our solution does not depend on challenging long-term quantum storage or a network of trusted agents and authenticated channels. The envisioned scenario is practical with near-term technology and has the potential to herald a new era of real-world, quantum-enabled security.
We consider the problem of explaining the predictions of graph neural networks (GNNs), which otherwise are considered as black boxes. Existing methods invariably focus on explaining the importance of graph nodes or edges but ignore the substructures of graphs, which are more intuitive and human-intelligible. In this work, we propose a novel method, known as SubgraphX, to explain GNNs by identifying important subgraphs. Given a trained GNN model and an input graph, our SubgraphX explains its predictions by efficiently exploring different subgraphs with Monte Carlo tree search. To make the tree search more effective, we propose to use Shapley values as a measure of subgraph importance, which can also capture the interactions among different subgraphs. To expedite computations, we propose efficient approximation schemes to compute Shapley values for graph data. Our work represents the first attempt to explain GNNs via identifying subgraphs explicitly and directly. Experimental results show that our SubgraphX achieves significantly improved explanations, while keeping computations at a reasonable level.
Deep neural networks have revolutionized many machine learning tasks in power systems, ranging from pattern recognition to signal processing. The data in these tasks is typically represented in Euclidean domains. Nevertheless, there is an increasing number of applications in power systems, where data are collected from non-Euclidean domains and represented as the graph-structured data with high dimensional features and interdependency among nodes. The complexity of graph-structured data has brought significant challenges to the existing deep neural networks defined in Euclidean domains. Recently, many studies on extending deep neural networks for graph-structured data in power systems have emerged. In this paper, a comprehensive overview of graph neural networks (GNNs) in power systems is proposed. Specifically, several classical paradigms of GNNs structures (e.g., graph convolutional networks, graph recurrent neural networks, graph attention networks, graph generative networks, spatial-temporal graph convolutional networks, and hybrid forms of GNNs) are summarized, and key applications in power systems such as fault diagnosis, power prediction, power flow calculation, and data generation are reviewed in detail. Furthermore, main issues and some research trends about the applications of GNNs in power systems are discussed.
Over the past few years, we have seen fundamental breakthroughs in core problems in machine learning, largely driven by advances in deep neural networks. At the same time, the amount of data collected in a wide array of scientific domains is dramatically increasing in both size and complexity. Taken together, this suggests many exciting opportunities for deep learning applications in scientific settings. But a significant challenge to this is simply knowing where to start. The sheer breadth and diversity of different deep learning techniques makes it difficult to determine what scientific problems might be most amenable to these methods, or which specific combination of methods might offer the most promising first approach. In this survey, we focus on addressing this central issue, providing an overview of many widely used deep learning models, spanning visual, sequential and graph structured data, associated tasks and different training methods, along with techniques to use deep learning with less data and better interpret these complex models --- two central considerations for many scientific use cases. We also include overviews of the full design process, implementation tips, and links to a plethora of tutorials, research summaries and open-sourced deep learning pipelines and pretrained models, developed by the community. We hope that this survey will help accelerate the use of deep learning across different scientific domains.

注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191