
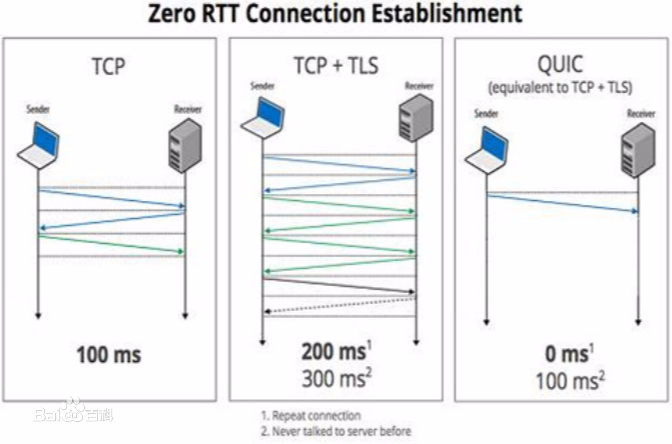

QUIC is a new protocol standardized in 2021 designed to improve on the widely used TCP / TLS stack. The main goal is to speed up web traffic via HTTP, but it is also used in other areas like tunneling. Based on UDP it offers features like reliable in-order delivery, flow and congestion control, streambased multiplexing, and always-on encryption using TLS 1.3. Other than with TCP, QUIC implements all these features in user space, only requiring kernel interaction for UDP. While running in user space provides more flexibility, it profits less from efficiency and optimization within the kernel. Multiple implementations exist, differing in programming language, architecture, and design choices. This paper presents an extension to the QUIC Interop Runner, a framework for testing interoperability of QUIC implementations. Our contribution enables reproducible QUIC benchmarks on dedicated hardware. We provide baseline results on 10G links, including multiple implementations, evaluate how OS features like buffer sizes and NIC offloading impact QUIC performance, and show which data rates can be achieved with QUIC compared to TCP. Our results show that QUIC performance varies widely between client and server implementations from 90 Mbit/s to 4900 Mbit/s. We show that the OS generally sets the default buffer size too small, which should be increased by at least an order of magnitude based on our findings. Furthermore, QUIC benefits less from NIC offloading and AES NI hardware acceleration while both features improve the goodput of TCP to around 8000 Mbit/s. Our framework can be applied to evaluate the effects of future improvements to the protocol or the OS.
相關內容
Time-Sensitive Networking (TSN) extends Ethernet to enable real-time communication, including the Credit-Based Shaper (CBS) for prioritized scheduling and the Time-Aware Shaper (TAS) for scheduled traffic. Generally, TSN requires streams to be explicitly admitted before being transmitted. To ensure that admitted traffic conforms with the traffic descriptors indicated for admission control, Per-Stream Filtering and Policing (PSFP) has been defined. For credit-based metering, well-known token bucket policers are applied. However, time-based metering requires time-dependent switch behavior and time synchronization with sub-microsecond precision. While TSN-capable switches support various TSN traffic shaping mechanisms, a full implementation of PSFP is still not available. To bridge this gap, we present a P4-based implementation of PSFP on a 100 Gb/s per port hardware switch. We explain the most interesting aspects of the PSFP implementation whose code is available on GitHub. We demonstrate credit-based and time-based policing and synchronization capabilities to validate the functionality and effectiveness of P4-PSFP. The implementation scales up to 35840 streams depending on the stream identification method. P4-PSFP can be used in practice as long as appropriate TSN switches lack this function. Moreover, its implementation may be helpful for other P4-based hardware implementations that require time synchronization.
With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.
Players and ball detection are among the first required steps on a football analytics platform. Until recently, the existing open datasets on which the evaluations of most models were based, were not sufficient. In this work, we point out their weaknesses, and with the advent of the SoccerNet v3, we propose and deliver to the community an edited part of its dataset, in YOLO normalized annotation format for training and evaluation. The code of the methods and metrics are provided so that they can be used as a benchmark in future comparisons. The recent YOLO8n model proves better than FootAndBall in long-shot real-time detection of the ball and players on football fields.
秩
·
We unify Ryser's and Glynn's formulas for computing the permanent into a single framework. We then show via an orbital bound argument that the product rank of the permanent is asymptotically upper bounded by $ \frac{\exp\left(\pi\sqrt{\frac{2n}{3}}\right)}{4\sqrt{3}n} $.
Autonomous driving has achieved a significant milestone in research and development over the last decade. There is increasing interest in the field as the deployment of self-operating vehicles on roads promises safer and more ecologically friendly transportation systems. With the rise of computationally powerful artificial intelligence (AI) techniques, autonomous vehicles can sense their environment with high precision, make safe real-time decisions, and operate more reliably without human interventions. However, intelligent decision-making in autonomous cars is not generally understandable by humans in the current state of the art, and such deficiency hinders this technology from being socially acceptable. Hence, aside from making safe real-time decisions, the AI systems of autonomous vehicles also need to explain how these decisions are constructed in order to be regulatory compliant across many jurisdictions. Our study sheds a comprehensive light on developing explainable artificial intelligence (XAI) approaches for autonomous vehicles. In particular, we make the following contributions. First, we provide a thorough overview of the present gaps with respect to explanations in the state-of-the-art autonomous vehicle industry. We then show the taxonomy of explanations and explanation receivers in this field. Thirdly, we propose a framework for an architecture of end-to-end autonomous driving systems and justify the role of XAI in both debugging and regulating such systems. Finally, as future research directions, we provide a field guide on XAI approaches for autonomous driving that can improve operational safety and transparency towards achieving public approval by regulators, manufacturers, and all engaged stakeholders.
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Hence, model pruning has been introduced to compress large-scale PLMs. However, most prior approaches only consider task-specific knowledge towards downstream tasks, but ignore the essential task-agnostic knowledge during pruning, which may cause catastrophic forgetting problem and lead to poor generalization ability. To maintain both task-agnostic and task-specific knowledge in our pruned model, we propose ContrAstive Pruning (CAP) under the paradigm of pre-training and fine-tuning. It is designed as a general framework, compatible with both structured and unstructured pruning. Unified in contrastive learning, CAP enables the pruned model to learn from the pre-trained model for task-agnostic knowledge, and fine-tuned model for task-specific knowledge. Besides, to better retain the performance of the pruned model, the snapshots (i.e., the intermediate models at each pruning iteration) also serve as effective supervisions for pruning. Our extensive experiments show that adopting CAP consistently yields significant improvements, especially in extremely high sparsity scenarios. With only 3% model parameters reserved (i.e., 97% sparsity), CAP successfully achieves 99.2% and 96.3% of the original BERT performance in QQP and MNLI tasks. In addition, our probing experiments demonstrate that the model pruned by CAP tends to achieve better generalization ability.
Graph Convolutional Network (GCN) has been widely applied in transportation demand prediction due to its excellent ability to capture non-Euclidean spatial dependence among station-level or regional transportation demands. However, in most of the existing research, the graph convolution was implemented on a heuristically generated adjacency matrix, which could neither reflect the real spatial relationships of stations accurately, nor capture the multi-level spatial dependence of demands adaptively. To cope with the above problems, this paper provides a novel graph convolutional network for transportation demand prediction. Firstly, a novel graph convolution architecture is proposed, which has different adjacency matrices in different layers and all the adjacency matrices are self-learned during the training process. Secondly, a layer-wise coupling mechanism is provided, which associates the upper-level adjacency matrix with the lower-level one. It also reduces the scale of parameters in our model. Lastly, a unitary network is constructed to give the final prediction result by integrating the hidden spatial states with gated recurrent unit, which could capture the multi-level spatial dependence and temporal dynamics simultaneously. Experiments have been conducted on two real-world datasets, NYC Citi Bike and NYC Taxi, and the results demonstrate the superiority of our model over the state-of-the-art ones.
Recently pre-trained language representation models such as BERT have shown great success when fine-tuned on downstream tasks including information retrieval (IR). However, pre-training objectives tailored for ad-hoc retrieval have not been well explored. In this paper, we propose Pre-training with Representative wOrds Prediction (PROP) for ad-hoc retrieval. PROP is inspired by the classical statistical language model for IR, specifically the query likelihood model, which assumes that the query is generated as the piece of text representative of the "ideal" document. Based on this idea, we construct the representative words prediction (ROP) task for pre-training. Given an input document, we sample a pair of word sets according to the document language model, where the set with higher likelihood is deemed as more representative of the document. We then pre-train the Transformer model to predict the pairwise preference between the two word sets, jointly with the Masked Language Model (MLM) objective. By further fine-tuning on a variety of representative downstream ad-hoc retrieval tasks, PROP achieves significant improvements over baselines without pre-training or with other pre-training methods. We also show that PROP can achieve exciting performance under both the zero- and low-resource IR settings. The code and pre-trained models are available at //github.com/Albert-Ma/PROP.
The goal of text ranking is to generate an ordered list of texts retrieved from a corpus in response to a query. Although the most common formulation of text ranking is search, instances of the task can also be found in many natural language processing applications. This survey provides an overview of text ranking with neural network architectures known as transformers, of which BERT is the best-known example. The combination of transformers and self-supervised pretraining has, without exaggeration, revolutionized the fields of natural language processing (NLP), information retrieval (IR), and beyond. In this survey, we provide a synthesis of existing work as a single point of entry for practitioners who wish to gain a better understanding of how to apply transformers to text ranking problems and researchers who wish to pursue work in this area. We cover a wide range of modern techniques, grouped into two high-level categories: transformer models that perform reranking in multi-stage ranking architectures and learned dense representations that attempt to perform ranking directly. There are two themes that pervade our survey: techniques for handling long documents, beyond the typical sentence-by-sentence processing approaches used in NLP, and techniques for addressing the tradeoff between effectiveness (result quality) and efficiency (query latency). Although transformer architectures and pretraining techniques are recent innovations, many aspects of how they are applied to text ranking are relatively well understood and represent mature techniques. However, there remain many open research questions, and thus in addition to laying out the foundations of pretrained transformers for text ranking, this survey also attempts to prognosticate where the field is heading.
We propose a novel single shot object detection network named Detection with Enriched Semantics (DES). Our motivation is to enrich the semantics of object detection features within a typical deep detector, by a semantic segmentation branch and a global activation module. The segmentation branch is supervised by weak segmentation ground-truth, i.e., no extra annotation is required. In conjunction with that, we employ a global activation module which learns relationship between channels and object classes in a self-supervised manner. Comprehensive experimental results on both PASCAL VOC and MS COCO detection datasets demonstrate the effectiveness of the proposed method. In particular, with a VGG16 based DES, we achieve an mAP of 81.7 on VOC2007 test and an mAP of 32.8 on COCO test-dev with an inference speed of 31.5 milliseconds per image on a Titan Xp GPU. With a lower resolution version, we achieve an mAP of 79.7 on VOC2007 with an inference speed of 13.0 milliseconds per image.
小貼士
登錄享
相關主題


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191