

Current causally consistent data storage algorithms use partial or full replication to ensure data access to clients over a distributed setting. We develop, for the first time, an erasure coding-based algorithm called CausalEC that ensures causal consistency for a collection of read-write objects stored in a distributed set of nodes over an asynchronous message-passing system. CausalEC can use an arbitrary linear erasure code for data storage and ensures liveness, fault-tolerance, and storage properties prescribed by the erasure code. CausalEC retains a key benefit of previous replication-based algorithms - every write operation is "local", that is, a server performs only local actions before returning to a client that issued a write operation. For servers that store certain objects in an uncoded manner, read operations to those objects also return locally. In general, a read operation to an object can be returned by a server on contacting a small subset of other servers so long as the underlying erasure code allows for the object to be decoded from that subset. Notably, unlike previous consistent erasure coding-based algorithms, CausalEC is compatible with cross-object erasure coding, where nodes encode values across multiple objects. CausalEC navigates the technical challenges of cross-object erasure coding, in particular, pertaining to re-encoding when writes update the values and ensuring that concurrent reads are served in a non-blocking manner during the transition to storing codeword symbols corresponding to the updated values.
相關內容
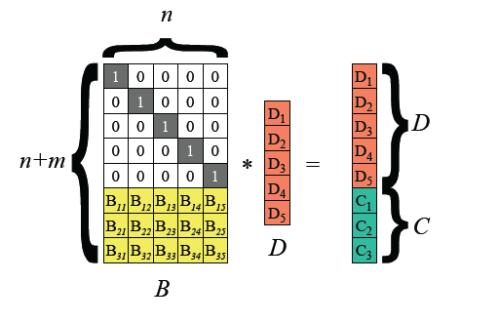
糾(jiu)刪碼(erasure coding,EC)是一種(zhong)數(shu)據保(bao)護方法(fa),它(ta)將數(shu)據分割(ge)成片段,把冗余數(shu)據塊擴展、編碼,并將其存(cun)儲在不同的位(wei)置,比(bi)如(ru)磁盤、存(cun)儲節點或(huo)者其它(ta)地理位(wei)置。
Recent advances in the development of large language models are rapidly changing how online applications function. LLM-based search tools, for instance, offer a natural language interface that can accommodate complex queries and provide detailed, direct responses. At the same time, there have been concerns about the veracity of the information provided by LLM-based tools due to potential mistakes or fabrications that can arise in algorithmically generated text. In a set of online experiments we investigate how LLM-based search changes people's behavior relative to traditional search, and what can be done to mitigate overreliance on LLM-based output. Participants in our experiments were asked to solve a series of decision tasks that involved researching and comparing different products, and were randomly assigned to do so with either an LLM-based search tool or a traditional search engine. In our first experiment, we find that participants using the LLM-based tool were able to complete their tasks more quickly, using fewer but more complex queries than those who used traditional search. Moreover, these participants reported a more satisfying experience with the LLM-based search tool. When the information presented by the LLM was reliable, participants using the tool made decisions with a comparable level of accuracy to those using traditional search, however we observed overreliance on incorrect information when the LLM erred. Our second experiment further investigated this issue by randomly assigning some users to see a simple color-coded highlighting scheme to alert them to potentially incorrect or misleading information in the LLM responses. Overall we find that this confidence-based highlighting substantially increases the rate at which users spot incorrect information, improving the accuracy of their overall decisions while leaving most other measures unaffected.
Large amounts of tabular data remain underutilized due to privacy, data quality, and data sharing limitations. While training a generative model producing synthetic data resembling the original distribution addresses some of these issues, most applications require additional constraints from the generated data. Existing synthetic data approaches are limited as they typically only handle specific constraints, e.g., differential privacy (DP) or increased fairness, and lack an accessible interface for declaring general specifications. In this work, we introduce ProgSyn, the first programmable synthetic tabular data generation algorithm that allows for comprehensive customization over the generated data. To ensure high data quality while adhering to custom specifications, ProgSyn pre-trains a generative model on the original dataset and fine-tunes it on a differentiable loss automatically derived from the provided specifications. These can be programmatically declared using statistical and logical expressions, supporting a wide range of requirements (e.g., DP or fairness, among others). We conduct an extensive experimental evaluation of ProgSyn on a number of constraints, achieving a new state-of-the-art on some, while remaining general. For instance, at the same fairness level we achieve 2.3% higher downstream accuracy than the state-of-the-art in fair synthetic data generation on the Adult dataset. Overall, ProgSyn provides a versatile and accessible framework for generating constrained synthetic tabular data, allowing for specifications that generalize beyond the capabilities of prior work.
The demand of computational resources for the modeling process increases as the scale of the datasets does, since traditional approaches for regression involve inverting huge data matrices. The main problem relies on the large data size, and so a standard approach is subsampling that aims at obtaining the most informative portion of the big data. In the current paper, we explore an existing approach based on leverage scores, proposed for subdata selection in linear model discrimination. Our objective is to propose the aforementioned approach for selecting the most informative data points to estimate unknown parameters in both the first-order linear model and a model with interactions. We conclude that the approach based on leverage scores improves existing approaches, providing simulation experiments as well as a real data application.
In high stake applications, active experimentation may be considered too risky and thus data are often collected passively. While in simple cases, such as in bandits, passive and active data collection are similarly effective, the price of passive sampling can be much higher when collecting data from a system with controlled states. The main focus of the current paper is the characterization of this price. For example, when learning in episodic finite state-action Markov decision processes (MDPs) with $\mathrm{S}$ states and $\mathrm{A}$ actions, we show that even with the best (but passively chosen) logging policy, $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H)}/\varepsilon^2)$ episodes are necessary (and sufficient) to obtain an $\epsilon$-optimal policy, where $H$ is the length of episodes. Note that this shows that the sample complexity blows up exponentially compared to the case of active data collection, a result which is not unexpected, but, as far as we know, have not been published beforehand and perhaps the form of the exact expression is a little surprising. We also extend these results in various directions, such as other criteria or learning in the presence of function approximation, with similar conclusions. A remarkable feature of our result is the sharp characterization of the exponent that appears, which is critical for understanding what makes passive learning hard.
While many natural language inference (NLI) datasets target certain semantic phenomena, e.g., negation, tense & aspect, monotonicity, and presupposition, to the best of our knowledge, there is no NLI dataset that involves diverse types of spatial expressions and reasoning. We fill this gap by semi-automatically creating an NLI dataset for spatial reasoning, called SpaceNLI. The data samples are automatically generated from a curated set of reasoning patterns, where the patterns are annotated with inference labels by experts. We test several SOTA NLI systems on SpaceNLI to gauge the complexity of the dataset and the system's capacity for spatial reasoning. Moreover, we introduce a Pattern Accuracy and argue that it is a more reliable and stricter measure than the accuracy for evaluating a system's performance on pattern-based generated data samples. Based on the evaluation results we find that the systems obtain moderate results on the spatial NLI problems but lack consistency per inference pattern. The results also reveal that non-projective spatial inferences (especially due to the "between" preposition) are the most challenging ones.
The Independent Cutset problem asks whether there is a set of vertices in a given graph that is both independent and a cutset. Such a problem is $\textsf{NP}$-complete even when the input graph is planar and has maximum degree five. In this paper, we first present a $\mathcal{O}^*(1.4423^{n})$-time algorithm for the problem. We also show how to compute a minimum independent cutset (if any) in the same running time. Since the property of having an independent cutset is MSO$_1$-expressible, our main results are concerned with structural parameterizations for the problem considering parameters that are not bounded by a function of the clique-width of the input. We present $\textsf{FPT}$-time algorithms for the problem considering the following parameters: the dual of the maximum degree, the dual of the solution size, the size of a dominating set (where a dominating set is given as an additional input), the size of an odd cycle transversal, the distance to chordal graphs, and the distance to $P_5$-free graphs. We close by introducing the notion of $\alpha$-domination, which allows us to identify more fixed-parameter tractable and polynomial-time solvable cases.
Vertical Federated Learning (VFL) is a crucial paradigm for training machine learning models on feature-partitioned, distributed data. However, due to privacy restrictions, few public real-world VFL datasets exist for algorithm evaluation, and these represent a limited array of feature distributions. Existing benchmarks often resort to synthetic datasets, derived from arbitrary feature splits from a global set, which only capture a subset of feature distributions, leading to inadequate algorithm performance assessment. This paper addresses these shortcomings by introducing two key factors affecting VFL performance - feature importance and feature correlation - and proposing associated evaluation metrics and dataset splitting methods. Additionally, we introduce a real VFL dataset to address the deficit in image-image VFL scenarios. Our comprehensive evaluation of cutting-edge VFL algorithms provides valuable insights for future research in the field.
Mutual coherence is a measure of similarity between two opinions. Although the notion comes from philosophy, it is essential for a wide range of technologies, e.g., the Wahl-O-Mat system. In Germany, this system helps voters to find candidates that are the closest to their political preferences. The exact computation of mutual coherence is highly time-consuming due to the iteration over all subsets of an opinion. Moreover, for every subset, an instance of the SAT model counting problem has to be solved which is known to be a hard problem in computer science. This work is the first study to accelerate this computation. We model the distribution of the so-called confirmation values as a mixture of three Gaussians and present efficient heuristics to estimate its model parameters. The mutual coherence is then approximated with the expected value of the distribution. Some of the presented algorithms are fully polynomial-time, others only require solving a small number of instances of the SAT model counting problem. The average squared error of our best algorithm lies below 0.0035 which is insignificant if the efficiency is taken into account. Furthermore, the accuracy is precise enough to be used in Wahl-O-Mat-like systems.
The Data Science domain has expanded monumentally in both research and industry communities during the past decade, predominantly owing to the Big Data revolution. Artificial Intelligence (AI) and Machine Learning (ML) are bringing more complexities to data engineering applications, which are now integrated into data processing pipelines to process terabytes of data. Typically, a significant amount of time is spent on data preprocessing in these pipelines, and hence improving its e fficiency directly impacts the overall pipeline performance. The community has recently embraced the concept of Dataframes as the de-facto data structure for data representation and manipulation. However, the most widely used serial Dataframes today (R, pandas) experience performance limitations while working on even moderately large data sets. We believe that there is plenty of room for improvement by taking a look at this problem from a high-performance computing point of view. In a prior publication, we presented a set of parallel processing patterns for distributed dataframe operators and the reference runtime implementation, Cylon [1]. In this paper, we are expanding on the initial concept by introducing a cost model for evaluating the said patterns. Furthermore, we evaluate the performance of Cylon on the ORNL Summit supercomputer.
This paper aims to mitigate straggler effects in synchronous distributed learning for multi-agent reinforcement learning (MARL) problems. Stragglers arise frequently in a distributed learning system, due to the existence of various system disturbances such as slow-downs or failures of compute nodes and communication bottlenecks. To resolve this issue, we propose a coded distributed learning framework, which speeds up the training of MARL algorithms in the presence of stragglers, while maintaining the same accuracy as the centralized approach. As an illustration, a coded distributed version of the multi-agent deep deterministic policy gradient(MADDPG) algorithm is developed and evaluated. Different coding schemes, including maximum distance separable (MDS)code, random sparse code, replication-based code, and regular low density parity check (LDPC) code are also investigated. Simulations in several multi-robot problems demonstrate the promising performance of the proposed framework.



注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191