


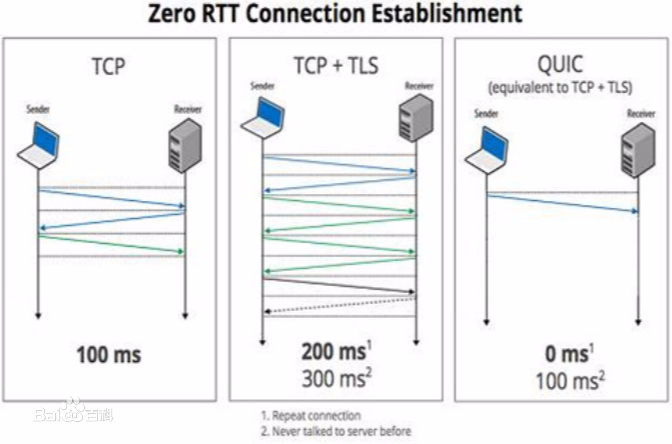
Cryptographic protocols have been widely used to protect the user's privacy and avoid exposing private information. QUIC (Quick UDP Internet Connections), including the version originally designed by Google (GQUIC) and the version standardized by IETF (IQUIC), as alternatives to the traditional HTTP, demonstrate their unique transmission characteristics: based on UDP for encrypted resource transmitting, accelerating web page rendering. However, existing encrypted transmission schemes based on TCP are vulnerable to website fingerprinting (WFP) attacks, allowing adversaries to infer the users' visited websites by eavesdropping on the transmission channel. Whether GQUIC and IQUIC can effectively resist such attacks is worth investigating. In this paper, we study the vulnerabilities of GQUIC, IQUIC, and HTTPS to WFP attacks from the perspective of traffic analysis. Extensive experiments show that, in the early traffic scenario, GQUIC is the most vulnerable to WFP attacks among GQUIC, IQUIC, and HTTPS, while IQUIC is more vulnerable than HTTPS, but the vulnerability of the three protocols is similar in the normal full traffic scenario. Features transferring analysis shows that most features are transferable between protocols when on normal full traffic scenario. However, combining with the qualitative analysis of latent feature representation, we find that the transferring is inefficient when on early traffic, as GQUIC, IQUIC, and HTTPS show the significantly different magnitude of variation in the traffic distribution on early traffic. By upgrading the one-time WFP attacks to multiple WFP Top-a attacks, we find that the attack accuracy on GQUIC and IQUIC reach 95.4% and 95.5%, respectively, with only 40 packets and just using simple features, whereas reach only 60.7% when on HTTPS. We also demonstrate that the vulnerability of IQUIC is only slightly dependent on the network environment.
相關內容
ICT systems provide detailed information on computer network traffic. However, due to storage limitations, some of the information on past traffic is often only retained in an aggregated form. In this paper we show that Linear Gaussian State Space Models yield simple yet effective methods to make predictions based on time series at different aggregation levels. The models link coarse-grained and fine-grained time series to a single model that is able to provide fine-grained predictions. Our numerical experiments show up to 3.7 times improvement in expected mean absolute forecast error when forecasts are made using, instead of ignoring, additional coarse-grained observations. The forecasts are obtained in a Bayesian formulation of the model, which allows for provisioning of a traffic prediction service with highly informative priors obtained from coarse-grained historical data.
A major impediment to researchers working in the area of fingerprint recognition is the lack of publicly available, large-scale, fingerprint datasets. The publicly available datasets that do exist contain very few identities and impressions per finger. This limits research on a number of topics, including e.g., using deep networks to learn fixed length fingerprint embeddings. Therefore, we propose PrintsGAN, a synthetic fingerprint generator capable of generating unique fingerprints along with multiple impressions for a given fingerprint. Using PrintsGAN, we synthesize a database of 525k fingerprints (35K distinct fingers, each with 15 impressions). Next, we show the utility of the PrintsGAN generated dataset by training a deep network to extract a fixed-length embedding from a fingerprint. In particular, an embedding model trained on our synthetic fingerprints and fine-tuned on a small number of publicly available real fingerprints (25K prints from NIST SD302) obtains a TAR of 87.03% @ FAR=0.01% on the NIST SD4 database (a boost from TAR=73.37% when only trained on NIST SD302). Prevailing synthetic fingerprint generation methods do not enable such performance gains due to i) lack of realism or ii) inability to generate multiple impressions per finger. We plan to release our database of synthetic fingerprints to the public.
The rapid deployment of new Internet protocols over the last few years and the COVID-19 pandemic more recently (2020) has resulted in a change in the Internet traffic composition. Consequently, an updated microscopic view of traffic shares is needed to understand how the Internet is evolving to capture both such shorter- and longer-term events. Toward this end, we observe traffic composition at a research network in Japan and a Tier-1 ISP in the USA. We analyze the traffic traces passively captured at two inter-domain links: MAWI (Japan) and CAIDA (New York-Sao Paulo), which cover 100GB of data for MAWI traces and 4TB of data for CAIDA traces in total. We begin by studying the impact of COVID-19 on the MAWI link: We find a substantial increase in the traffic volume of OpenVPN and rsync, as well as increases in traffic volume from cloud storage and video conferencing services, which shows that clients shift to remote work during the pandemic. For traffic traces between March 2018 to December 2018, we find that the use of IPv6 is increasing quickly on the CAIDA monitor: The IPv6 traffic volume increases from 1.1% in March 2018 to 6.1% in December 2018, while the IPv6 traffic share remains stable in the MAWI dataset at around 9% of the traffic volume. Among other protocols at the application layer, 60%-70% of IPv4 traffic on the CAIDA link is HTTP(S) traffic, out of which two-thirds are encrypted; for the MAWI link, more than 90% of the traffic is Web, of which nearly 75% is encrypted. Compared to previous studies, this depicts a larger increase in encrypted Web traffic of up to a 3-to-1 ratio of HTTPS to HTTP. As such, our observations in this study further reconfirm that traffic shares change with time and can vary greatly depending on the vantage point studied despite the use of the same generalized methodology and analyses, which can also be applied to other traffic monitoring datasets.
As the training of giant dense models hits the boundary on the availability and capability of the hardware resources today, Mixture-of-Experts (MoE) models become one of the most promising model architectures due to their significant training cost reduction compared to a quality-equivalent dense model. Its training cost saving is demonstrated from encoder-decoder models (prior works) to a 5x saving for auto-aggressive language models (this work along with parallel explorations). However, due to the much larger model size and unique architecture, how to provide fast MoE model inference remains challenging and unsolved, limiting its practical usage. To tackle this, we present DeepSpeed-MoE, an end-to-end MoE training and inference solution as part of the DeepSpeed library, including novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions. DeepSpeed-MoE offers an unprecedented scale and efficiency to serve massive MoE models with up to 4.5x faster and 9x cheaper inference compared to quality-equivalent dense models. We hope our innovations and systems help open a promising path to new directions in the large model landscape, a shift from dense to sparse MoE models, where training and deploying higher-quality models with fewer resources becomes more widely possible.
Integrated sensing and communication (ISAC) is a novel paradigm using crowdsensing spectrum sensors to help with the management of spectrum scarcity. However, well-known vulnerabilities of resource-constrained spectrum sensors and the possibility of being manipulated by users with physical access complicate their protection against spectrum sensing data falsification (SSDF) attacks. Most recent literature suggests using behavioral fingerprinting and Machine/Deep Learning (ML/DL) for improving similar cybersecurity issues. Nevertheless, the applicability of these techniques in resource-constrained devices, the impact of attacks affecting spectrum data integrity, and the performance and scalability of models suitable for heterogeneous sensors types are still open challenges. To improve limitations, this work presents seven SSDF attacks affecting spectrum sensors and introduces CyberSpec, an ML/DL-oriented framework using device behavioral fingerprinting to detect anomalies produced by SSDF attacks affecting resource-constrained spectrum sensors. CyberSpec has been implemented and validated in ElectroSense, a real crowdsensing RF monitoring platform where several configurations of the proposed SSDF attacks have been executed in different sensors. A pool of experiments with different unsupervised ML/DL-based models has demonstrated the suitability of CyberSpec detecting the previous attacks within an acceptable timeframe.
Traffic accident anticipation is a vital function of Automated Driving Systems (ADSs) for providing a safety-guaranteed driving experience. An accident anticipation model aims to predict accidents promptly and accurately before they occur. Existing Artificial Intelligence (AI) models of accident anticipation lack a human-interpretable explanation of their decision-making. Although these models perform well, they remain a black-box to the ADS users, thus difficult to get their trust. To this end, this paper presents a Gated Recurrent Unit (GRU) network that learns spatio-temporal relational features for the early anticipation of traffic accidents from dashcam video data. A post-hoc attention mechanism named Grad-CAM is integrated into the network to generate saliency maps as the visual explanation of the accident anticipation decision. An eye tracker captures human eye fixation points for generating human attention maps. The explainability of network-generated saliency maps is evaluated in comparison to human attention maps. Qualitative and quantitative results on a public crash dataset confirm that the proposed explainable network can anticipate an accident on average 4.57 seconds before it occurs, with 94.02% average precision. In further, various post-hoc attention-based XAI methods are evaluated and compared. It confirms that the Grad-CAM chosen by this study can generate high-quality, human-interpretable saliency maps (with 1.23 Normalized Scanpath Saliency) for explaining the crash anticipation decision. Importantly, results confirm that the proposed AI model, with a human-inspired design, can outperform humans in the accident anticipation.
Elephant-human conflict (EHC) is one of the major problems in most African and Asian countries. As humans overutilize natural resources for their development, elephants' living area continues to decrease; this leads elephants to invade the human living area and raid crops more frequently, costing millions of dollars annually. To mitigate EHC, in this paper, we propose an original solution that comprises of three parts: a compact custom low-power GPS tag that is installed on the elephants, a receiver stationed in the human living area that detects the elephants' presence near a farm, and an autonomous unmanned aerial vehicle (UAV) system that tracks and herds the elephants away from the farms. By utilizing proportional-integral-derivative controller and machine learning algorithms, we obtain accurate tracking trajectories at a real-time processing speed of 32 FPS. Our proposed autonomous system can save over 68 % cost compared with human-controlled UAVs in mitigating EHC.
Correlation acts as a critical role in the tracking field, especially in recent popular Siamese-based trackers. The correlation operation is a simple fusion manner to consider the similarity between the template and the search region. However, the correlation operation itself is a local linear matching process, leading to lose semantic information and fall into local optimum easily, which may be the bottleneck of designing high-accuracy tracking algorithms. Is there any better feature fusion method than correlation? To address this issue, inspired by Transformer, this work presents a novel attention-based feature fusion network, which effectively combines the template and search region features solely using attention. Specifically, the proposed method includes an ego-context augment module based on self-attention and a cross-feature augment module based on cross-attention. Finally, we present a Transformer tracking (named TransT) method based on the Siamese-like feature extraction backbone, the designed attention-based fusion mechanism, and the classification and regression head. Experiments show that our TransT achieves very promising results on six challenging datasets, especially on large-scale LaSOT, TrackingNet, and GOT-10k benchmarks. Our tracker runs at approximatively 50 fps on GPU. Code and models are available at //github.com/chenxin-dlut/TransT.
We present a traffic simulation named DeepTraffic where the planning systems for a subset of the vehicles are handled by a neural network as part of a model-free, off-policy reinforcement learning process. The primary goal of DeepTraffic is to make the hands-on study of deep reinforcement learning accessible to thousands of students, educators, and researchers in order to inspire and fuel the exploration and evaluation of deep Q-learning network variants and hyperparameter configurations through large-scale, open competition. This paper investigates the crowd-sourced hyperparameter tuning of the policy network that resulted from the first iteration of the DeepTraffic competition where thousands of participants actively searched through the hyperparameter space.
Latent Dirichlet Allocation(LDA) is a popular topic model. Given the fact that the input corpus of LDA algorithms consists of millions to billions of tokens, the LDA training process is very time-consuming, which may prevent the usage of LDA in many scenarios, e.g., online service. GPUs have benefited modern machine learning algorithms and big data analysis as they can provide high memory bandwidth and computation power. Therefore, many frameworks, e.g. Ten- sorFlow, Caffe, CNTK, support to use GPUs for accelerating the popular machine learning data-intensive algorithms. However, we observe that LDA solutions on GPUs are not satisfying. In this paper, we present CuLDA_CGS, a GPU-based efficient and scalable approach to accelerate large-scale LDA problems. CuLDA_CGS is designed to efficiently solve LDA problems at high throughput. To it, we first delicately design workload partition and synchronization mechanism to exploit the benefits of mul- tiple GPUs. Then, we offload the LDA sampling process to each individual GPU by optimizing from the sampling algorithm, par- allelization, and data compression perspectives. Evaluations show that compared with state-of-the-art LDA solutions, CuLDA_CGS outperforms them by a large margin (up to 7.3X) on a single GPU. CuLDA_CGS is able to achieve extra 3.0X speedup on 4 GPUs. The source code is publicly available on //github.com/cuMF/ CuLDA_CGS.
小貼士
登錄享


注冊地址: 北京市海淀區羊坊店路18號2幢3層301-191